本文固定链接:https://www.askmac.cn/archives/basics-of-mapreduce-development.html
5.MapReduce 开发的基础知识
在前面的章节中,我们将Hadoop作为一个平台介绍给你。您了解了Hadoop架构背后的的概念,知道Hadoop管理的基础知识,甚至还编写了基本的MapReduce程序。
在这一章中,你将学习MapReduce编程的基本原理以及MapReduce程序常见的设计模式,并附带样本用例。这些基本原理将帮助你在下面的章节中深入理解MapReduce的高级概念。
5.1 Hadoop和数据处理
这里将通过实践案例来介绍MapReduce的基本原理。 RDBMS和SQL在数据处理中是无处不在的;我们使用SQL中的语言元素来解释MapReduce的基本概念。
在SQL语言元素背景下讨论MapReduce的基本概念不仅为你创造了一个了解MapReduce的熟悉环境,并且也将使你体会到当数据集很大时,MapReduce解决常见数据处理问题的合适性。
为了实现本章目标,我们使用了航空公司的数据集,包括到从1987年2008年所有商业航班抵达及起飞的详细信息。我们首先介绍一下这个数据集;然后你就可以开始通过MapReduce依据我们提到的SQL语言元素处理常见数据问题。在这一过程中,您将熟悉MapReduce的各个组成部分,其中包括:
- Mapper
- Reducer
- Combiner
- Partitioner
5.2 回顾航空数据集
本章使用了包括美国国内商业航班从1987年到2008年航班到达和起飞详细信息的航空公司数据集。该数据集是以逗号分隔的(CSV)格式,拥有大约120万条记录。数据集未压缩格式的磁盘总容量为120 GB。这是一个适合Hadoop处理的比较大的数据集,但也不是太大,所以很适合这本书的目的。选择该数据集的另一个原因是要在结构化数据处理的背景下讨论MapReduce。虽然Hadoop也用于非结构化数据处理,但其最常见的用途是在结构化数据集上执行大规模的ETL和把它用作大型数据集的数据仓库。该航空公司数据集高度结构化,适合用于解释SQL语言元素方面的MapReduce概念。该数据集可从http://stat-computing.org/dataexpo/2009/the-data.html下载。
数据集各种字段如表5-1所示。
表 5-1. 航空公司数据集数据字典
字段 使用说明
Year 定期航班年份(1987–2008).
Month 定期航班月份 (1–12).
DayofMonth 每月天数 (1–31).
DayOfWeek 标识一周中的天; 如, 1=星期一, 7=星期日.
DepTime 本地时区航班的实际起飞时间, 以 HH/MM 格式表示 (HH = 24小时时钟的小时数; MM = 从 00 到 59的分钟数).
CRSDepTime 预计起飞时间 ,以 HH/MM格式 (参考 DepTime). ArrTime 实际到达时间,以 HH/MM格式.
CRSArrTime 预计到达时间,以HH/MM 格式. 也参见 ArrTime.
UniqueCarrier 航空公司代码.
FlightNum 用于唯一地标识该航班的班机号.
TailNum 用于唯一地标识飞机的飞机注册号,类似于一辆车的车牌号码.
ActualElapsedTime 实际飞行时间 (以分钟计时).
CRSElapsedTime 预计飞行时间 (以分钟计时). 也参见 ActualElapsedTime. AirTime 总飞行时间 (以分钟计时).
ArrDelay 到达延误 (以分钟计时).
DepDelay 起飞延误 (以分钟计时).
Origin 起飞机场代码
Dest 目的地机场代码.
Distance 总飞行距离 (以英里计).
TaxiIn 到达时的滑入时间 (以分钟计时).
TaxiOut 起飞时的滑出时间 (以分钟计时).
Cancelled 显示航班是否取消的标志(1 = 是, 0 = 否).
CancellationCode 航班取消原因 (A = 飞机原因, B = 天气原因, C =美国国家空域系统, D = 安全原因). 延迟原因见下文.
Diverted 显示航班是否被转移的标志(1 =是, 0 = 否).
CarrierDelay 承运人控制范围内的各因素造成的延误 (以分钟计时),有关详细信息,请参阅此链接:
http://aspmhelp.faa.gov/index.php/Types_of_Delay.
WeatherDelay 由可预测的或起飞、途中、到达过程中的极端天气条件造成的延误Delay (以分钟计时).
NASDelay 在美国国家空域系统(NAS)控制范围内的延误(以分钟计时). 有关详细信息,请参阅此链接: http://aspmhelp.faa.gov/index.php/Types_of_Delay.
SecurityDelay 由安全原因造成的安全延迟(以分钟计时)。有关详细信息,请参阅此链接: http://aspmhelp.faa.gov/index.php/Types_of_Delay.
LateAircraftDelay 由于相同飞机在前一机场晚点到达造成的延误(以分钟计时). 是由传播造成的延误.
我们也使用主数据来解释数据集中的代码:
- carriers.csv: 唯一的航空公司代码
- airports.csv: 机场代码
这些主文件以 CSV 格式存在,可从以下网址下载: http://stat-computing.org/dataexpo/2009/supplemental-data.html.
该航空公司的数据是BZIP2压缩格式。压缩方案将在第7章进行更详细的讨论,现在你需要知道的是:Hadoop透明地处理某些压缩格式,bzip2是这些格式的其中之一。
5.2.1 准备开发环境
为了简化开发工作,输入数据的一个小子集已被添加到项目文件夹src/main/resources/input/devairlinedataset/txt/。此文件夹中有两个未压缩的文件:
- 1987:从1987年记录的一个子集
- 1988: 从1988年记录的一个子集
应针对这些文件执行开发计划,以确保作业在开发环境中快速运行。
这些主数据放在src/main/resources/input/masterdata文件夹中,该文件夹中有两个文件:
- carriers.csv: :航空公司数据集中机场代码引用的所有机场的主数据
- carriers.csv: 航空公司数据集中引用的所有航空公司的主数据
5.2.2 准备Hadoop系统
我们需要将航空公司数据传输到HDFS。假设这些数据位于机器的本地目录:/user/local/airlinedata/。该目录包含带有下列文件名的文件:1987.csv.bz2,1988.csv.bz2 … 2008.csv.bz2。
假定所有的主数据(carriers.csv和airports.csv)存在于/user/local/ masterdata/文件夹中。
接下来,我们通过执行以下命令创建三个目录。这些文件夹将被创建在HDFS主文件夹中,假设为/user/hdfs/。
hdfs dfs –mkdir airlinedata hdfs dfs –mkdir sampledata hdfs dfs –mkdir masterdata
第一个文件夹中包含了整个航空公司的数据集。创建第二个文件夹,用来保存1987年和1988年的数据。该文件夹应被用于存放在伪集群环境下进行测试作业的数据,因为整个数据集在伪集群上需要太多的时间来完成。最后一个文件夹中包含主数据文件。
现在,您可以将本地文件复制到其相应目录:
hdfs dfs –copyFromLocal /user/local/airlinedata/* /user/hdfs/airlinedata/ hdfs dfs –copyFromLocal /user/local/airlinedata/1987.bz2 /user/hdfs/sampledata/ hdfs dfs –copyFromLocal /user/local/airlinedata/1988.bz2 /user/hdfs/sampledata/ hdfs dfs –copyFromLocal /user/local/masterdata/* /user/hdfs/masterdata/
在本章中,Hadoop系统现在已准备好执行Hadoop项目。
5.3 MapReduce编程模式
如前所述,本章探讨以下SQL语言功能背景下的典型MapReduce设计模式:
- SELECT: 从表中的大量列中选择列的的子集
- WHERE: 基于布尔标准的各种列,筛选出一个表中的行
- AGGREGATION: 计算聚集值—一般如MIN,MAX和SUM—基于某些属性的分组。在SQL聚集中,查询通常基于GROUP BY和HAVING子句。
第6章和第7章将在以下SQL功能背景下探讨MapReduce的高级概念:
- SORTING: 当需要输出必须按照一定的标准排序时
- JOIN: 基于不同表中的相似的列值,将那些单独的表联合起来
5.3.1 仅Map作业(SELECT 和 WHERE查询)
我们首先讨论仅映射作业(基本的MapReduce程序在第3章中讨论过)。一个典型的MapReduce程序包括两个阶段:Map阶段和Reduce阶段。每个阶段都由一个自定义类执行,从Hadoop框架中分别扩展Mapper和Reducer的基类:
- Map: 自定义类的执行,从Hadoop框架中扩展apache.hadoop.mapreduce.Mapper的基类。其职责是处理以关键值格式接收的输入记录,并产生零个或多个键-—值对作为输出。
- Reduce: 自定义类的执行,从Hadoop框架中扩展apache.hadoop.mapreduce. Reducer的基类。总的来说,这需要Map输出每个键及其各自对应的值。Reducer可通过给定键上的每个值迭代,产生零个或多个键—值对。Reduce阶段是可选的。有些用例就不需要Reduce阶段。这种例子包括,SQL中的SELECT和WHERE子句应用于单个表时。对应这样的功能,你可以使用仅MAP的作业
5.3.2 问题定义:SELECT子句
从航空公司数据集中,我们希望产生整个数据集的输出,其只包括以下属性:
- 航班日期,以MM/DD/YYYY格式(例如,01/13/1987, 03/28/1988)
- 一周中的天数
- 起飞时间
- 到达时间
- 起飞机场代码
- 目的地机场代码
- 总飞行距离(英里数)
- 实际飞行时间
- 预计飞行时间
- 起飞延误
- 到达延误
这是表中一个简单的SELECT子句,包括一些基本的计算:
- 飞行日期是在以指定方式格式化的Month, DayOfMonth和 Year列的组合。
- 字段的结果是对相应字段简单的预测。
执行SELECT子句的程序是org.apress.prohadoop.c5.SelectClauseMRJob。
我们也使用另一个实用程序类,包含了我们之前介绍过的实用函数。该类的名称是:
org.apress.prohadoop.utils.AirlineDataUtils.
表5-1 展示了SelectClauseMRJob的列表。
表5-1 SelectClauseMRJob.java
package org.apress.prohadoop.c5;
//import statements, skipped for brevity
public class SelectClauseMRJob extends Configured implements Tool{
public static class SelectClauseMapper
extends Mapper<LongWritable, Text, NullWritable, Text> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
if(!AirlineDataUtils.isHeader(value)){
StringBuilder output = AirlineDataUtils.mergeStringArray( AirlineDataUtils.getSelectResultsPerRow(value), ",");
context.write(NullWritable.get(),new Text(output.toString()));
}
}
}
public int run(String[] allArgs) throws Exception {
Job job = Job.getInstance(getConf());
job.setJarByClass(SelectClauseMRJob.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(SelectClauseMapper.class);
job.setNumReduceTasks(0);
String[] args = new GenericOptionsParser(getConf(), allArgs).getRemainingArgs();
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean status = job.waitForCompletion(true);
if(status){
return 0;
}
else{
return 1;
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
ToolRunner.run(new SelectClauseMRJob(), args);
}
}
本书中我们统一使用新的MapReduce API和ToolRunner类(见第三章),因为它们通过GenericOptionsParser类(本章中将会经常提到)的使用,灵活性最高。
该方案的主要特点是,它是一个仅Map程序。决定你是否只需要Map阶段,Map和reduce阶段是设计高性能MapReduce程序的关键。仅Map程序明显运行地更快,因为他们没有排序/洗牌阶段,这个阶段我们在本章的后面将会讨论。该阶段负责通过网络传输,将Mapper输出从Mapper节点移动到Reducer节点。在仅Map作业中,Mapper简单地写出其结果,通常是在其被执行的同一台机器上,从而降低了网络通信开销,所以任务才能更迅速地完成 。
5.3.3 run( ) 方法
run()方法的主要方面如下:
- InputFormatClass:这是TextInputFormat,逐行读取输入数据。记住,在该示例中,输入文件是被压缩的。Hadoop框架透明地解压缩这些文件,并使单个行服务于程序的映射器。
- OutputFormatClass:这是TextOutputFormat,输出是未压缩的纯文本文件。压缩将在第6章中讨论,其中输出可以声明使用用户定义的压缩方案压缩。
- 由于输出是CSV文件,其键被声明为NullWritable,值被声明为Text(两个可写接口的实现)。写接口的重要性将在第6章进行更详细的讨论,其中可学到自定义写类是如何实现的。如果该键不被声明为NullWritable,而声明为Text,则我们的输出文件将使键后面跟着tab(\ t)字符,然后是值。使键定义为NullWritable可确保输出的每一行只包含一个值,该值是逗号分隔的字符串。
- 在一定条件下,输出键和值类需被声明。在第7章中,我们将探讨InputFormat接口的实现是如何定义Map输入键和值类型,但Hadoop框架需要知道从Mapper和Reducer中的输出数据类型,在运行时的实例创建这些类型,在Mapper和Reducer之间反序列化值,以及序列化实例从Reducer到输出文件。从Mapper和Reducer的类定义中推断运行时的类型,这是不可能的,因为Java泛型使用类型擦除(参见下面的注释)。InputFormat类定义Mapper输入键和值类型。TextInputFormat分别将这些类型定义为LongWritable和Text。默认情况下,Mapper输出键和值类型被认为与Mapper输入键和值类型相同。如果它们是不同的,我们需要向Hadoop框架指定。在我们的例子中,有一个仅Map任务。因此,我们只定义setOutputKeyClass和setOutputValueClass。后者是可选的,因为我们的Mapper输出值类与默认(Text)的一样。实际上由于TextOutputFormat在内部定义,在这种情况下这两种都是可选的。TextOutputFormat只是简单地逐行写记录。每个输出行包括由tab分隔的键和值。它首先通过调用键和值实例上的toString方法将它们转换为字符串实例。并且将NullWritable键作为特殊情况处理,其中值部分被写入到输出文件。然而,这是一种TextOutputFormat如何被定义的异常副作用。在第7章中,我们会遇到SequenceFileOutputFormat,存储元数据到文件内容中。这包括其内容的键和值的类型。SequenceFileOutputFormat取决于在工作实例中为了这些信息调用getOutputKeyClass()和getOutputValueClass()。稍后我们会见到两种方法,即setMapOutputKeyClass和setMapOutputValueClass。当Mapper和Reducer的输出键和值类型不一样时,将会用到这些方法。在本节中,你已经了解了为何在作业实例中这些方法需要通过客户端调用背后的一般规则。正如所讨论的,这些规则也存在小的异常,取决于特定的OutputFormat类是如何实现的。然而,这些与编写好的MapReduce程序无关。如果你遵循上面的规则,则你的MapReduce程序在运行时不会抛出任何运行异常。
- 我们的任务是仅Map作业,所以我们指定Mapper类,而不指定 Reducer类。我们明确指出,不需要通过调用job.setNumReduceTasks(0)方法得到的 Reducer,这是仅Map作业必须声明的。默认情况下,Hadoop框架配置一个减速器,使用一个叫做IdentityReducer的类。Mapper输出被发送到IdentityReducer,它然后将所有输入写到输出中。由于将Mapper输出从Mapper节点转移到Reducer节点这一不必要行为所产生的额外网络开销,该过程是非常低效的。
- 然后我们用job.waitForCompletion(true)方法运行此任务。该参数名称为verbose,用来标识该任务是否应该显示用户进展情况。
注意: 这里输入和输出格式会有很多种,但是本例使用的是TextInputFormat 和 TextOutputFormat,它们也分别是输入和输出的默认格式。第7章你将会学到不同的i/o格式。
- 注意: Java编程语言使用类型擦除实现泛型特征。这样做是为了确保二进制与传统的类的兼容性,因为Java泛型出现在Java后期。由于类型擦除,使得一个类,如java.util.ArrayList<Integer> 和 java.util. ArrayList <String>之间没有区别。运行时调用getClass()将返回java.util.ArrayList,从而导致运行时类型信息丢失。如果你在源代码中定义了下面的代码片段,这时类型擦除便发挥作用,如下所示:
List<String> l=new ArrayList<String>();l.put("t");String s=l.get("t");
编译器将编译其下面的行
List l=new ArrayList();l.put("t");String s=(String)l.get("t");
从而使类型信息在运行时丢失。因此,人们常说,Java泛型仅仅只是语法糖衣。
5.3.4 SelectClauseMapper 类
所有的行为都发生在Mapper类中。首先,我们来介绍一下Mapper类的配置:
SelectClauseMapper 继承 Mapper<LongWritable, Text, NullWritable, Text>
- 输入键类是LongWritable,文件中行的字节偏移。它是TextInputFormat向Mapper提供适当的键、值实例的任务。
- 输入值类是Text,它是输入文件文本的实际行。
- 输出键类是NullWritable,这是一个没有数据的单例对象。
- 输出值类是Text类。我们利用TextOutputFormat,它定义任务的输出规范。基于此选择,输出文件才有文本行。
接下来,我们使用输入的每一行。跳过标题行;对于非标题行,调用下面的方法:
AirlineDataUtils.getSelectResultsPerRow(value)
表5-2 展示了该方法的实现。
表5-2 AirlineDataUtils.getSelectResultsPerRow
public static String[] getSelectResultsPerRow(Text row){
String[] contents = row.toString().split(",");
String[] outputArray = new String[10];
outputArray[0]=AirlineDataUtils.getDate(contents);
outputArray[1]=AirlineDataUtils.getDepartureTime(contents);
outputArray[2]=AirlineDataUtils.getArrivalTime(contents);
outputArray[3]=AirlineDataUtils.getOrigin(contents);
outputArray[4]=AirlineDataUtils.getDestination(contents);
outputArray[5]=AirlineDataUtils.getDistance(contents);
outputArray[6]=AirlineDataUtils.getElapsedTime(contents);
outputArray[7]=AirlineDataUtils.getScheduledElapsedTime(contents);
outputArray[8]=AirlineDataUtils.getDepartureDelay(contents);
outputArray[9]=AirlineDataUtils.getArrivalDelay(contents);
return outputArray;
}
该方法用一个“,”分隔符将文本的的每一行拆分,提取SELECT子句的各部件,并以适当的顺序返回一个输出数组。调用AirlineDataUtils.mergeStringArray合并之前调用返回的数组,并返回一行,其组件是用逗号分隔的。
StringBuilder output = AirlineDataUtils.mergeStringArray( AirlineDataUtils.getSelectResultsPerRow(value), ",");
最后,下一次的调用和为此任务配置的TextOutputFormat实例一起将行发送到HDFS的输出文件中:
context.write(NullWritable.get(),new Text(output.toString()));
5.3.5 在开发环境中运行SELECT子句任务
The job can be executed in the development environment in local mode. If you are using the Eclipse IDE, simply execute the preceding class using the following set of parameters:
这项任务可在开发环境中以本地模式执行。如果您使用的是Eclipse IDE,只需简单使用以下参数执行之前的类:
- ./src/main/resources/input/devairlinedataset/txt: 包含了1987年和1988年飞行记录小版本的输入文件夹
- ./output/c5/select/: 与Eclipse项目主文件夹有关的输出文件夹
这项任务在本地模式下执行。在以集群模式运行之前先以本地模式执行所有任务是有帮助的。本书中的所有程序都可在此模式下以类似的方式来执行。随后的章节中会跳过在开发环境中的任务执行,因为它们与当前例子非常相似。
5.3.6在集群上运行SELECT子句任务
最后,我们执行一个Maven构建。结果是得到一个叫做prohadoop-0.0.1-SNAPSHOT.jar的JAR文件。
在Hadoop环境下执行此任务,如下所示:
hadoop jar prohadoop-0.0.1-SNAPSHOT.jar org.apress.prohadoop.c5.SelectClauseMRJob /user/hdfs/ sampledata \ /user/hdfs/output/c5/select
以上命令的各个组件如下:
- prohadoop-0.0.1-SNAPSHOT.jar表示Hadoop要执行的JAR文件
- org.apress.prohadoop.c5.SelectClauseMRJob是完全限定类名
- user/hdfs/sampledata是HDFS中包含输入文件的输入文件夹名称;/ user/hdfs/output/c5/select是HDFS中任务写入输出文件的文件夹名称。
当任务执行时,你应该能在屏幕上看到与表5-3所示类似的输出。输出的关键特点以粗体显示。
- 第一条粗线表示正在处理的文件数量。我们从sampledata文件夹中处理1987年和1988年的文件,因此有两个文件。
- 接下来的粗体部分(略)表示从0%到100%的任务进度。
- 第三个粗体部分表示两个map任务已启动,两个都是本地数据。换句话说,每一个映射任务从本地磁盘读取输入文件,并没有从来自另一个节点的磁盘网络获取它。 MapReduce框架努力使其成为可能,因为它最大限度地减少了网络开销。(在第6章讨论InputFormat和RecordReader类中,你将再次看到InputFormat类是如何实现这一点的)
最后两个粗体行很有意思,因为通过它们你会知道有多少文本行已被处理。回想一下,文本的每一行都是一个记录。每个文件还具有被忽略的标题行。输入记录超过输出记录两个是完全正确的,因为我们忽略了Mapper中的标题行。
表5-3 任务执行屏幕日志
14/01/26 06:39:30 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same. 14/01/26 06:39:32 INFO input.FileInputFormat: Total input paths to process : 2 14/01/26 06:39:32 INFO mapred.JobClient: Running job: job_201401251457_0002 14/01/26 06:39:33 INFO mapred.JobClient: map 0% reduce 0% 14/01/26 06:40:47 INFO mapred.JobClient: map 1% reduce 0% ........ 14/01/26 06:45:12 INFO mapred.JobClient: map 98% reduce 0% 14/01/26 06:45:15 INFO mapred.JobClient: map 99% reduce 0% 14/01/26 06:45:19 INFO mapred.JobClient: map 100% reduce 0% 14/01/26 06:45:30 INFO mapred.JobClient: Job complete: job_201401251457_0002 14/01/26 06:45:30 INFO mapred.JobClient: Counters: 24 14/01/26 06:45:30 INFO mapred.JobClient: File System Counters 14/01/26 06:45:30 INFO mapred.JobClient: FILE: Number of bytes read=0 14/01/26 06:45:30 INFO mapred.JobClient: FILE: Number of bytes written=319500 14/01/26 06:45:30 INFO mapred.JobClient: FILE: Number of read operations=0 14/01/26 06:45:30 INFO mapred.JobClient: FILE: Number of large read operations=0 14/01/26 06:45:30 INFO mapred.JobClient: FILE: Number of write operations=0 14/01/26 06:45:30 INFO mapred.JobClient: HDFS: Number of bytes read=62170169 14/01/26 06:45:30 INFO mapred.JobClient: HDFS: Number of bytes written=290559727 14/01/26 06:45:30 INFO mapred.JobClient: HDFS: Number of read operations=4 14/01/26 06:45:30 INFO mapred.JobClient: HDFS: Number of large read operations=0 14/01/26 06:45:30 INFO mapred.JobClient: HDFS: Number of write operations=2 14/01/26 06:45:31 INFO mapred.JobClient: Job Counters <strong>14/01/26 06:45:31 INFO mapred.JobClient: Launched map tasks=2 14/01/26 06:45:31 INFO mapred.JobClient: Data-local map tasks=2</strong> 14/01/26 06:45:31 INFO mapred.JobClient: Total time spent by all maps in occupied slots (ms)=539064 14/01/26 06:45:31 INFO mapred.JobClient: Total time spent by all reduces in occupied slots (ms)=0 14/01/26 06:45:31 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0 14/01/26 06:45:31 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0 14/01/26 06:45:31 INFO mapred.JobClient: Map-Reduce Framework 14/01/26 06:45:31 INFO mapred.JobClient: Map input records=6513924 14/01/26 06:45:31 INFO mapred.JobClient: Map output records=6513922 14/01/26 06:45:31 INFO mapred.JobClient: Input split bytes=270 14/01/26 06:45:31 INFO mapred.JobClient: Spilled Records=0 14/01/26 06:45:31 INFO mapred.JobClient: CPU time spent (ms)=217780 14/01/26 06:45:31 INFO mapred.JobClient: Physical memory (bytes) snapshot=225677312 14/01/26 06:45:31 INFO mapred.JobClient: Virtual memory (bytes) snapshot=1383579648 14/01/26 06:45:31 INFO mapred.JobClient: Total committed heap usage (bytes)=121503744
5.3.7 查看SELECT子句任务结果
执行完任务,你需要处理任务的结果。输出是一组存储在HDFS中以逗号分隔的文件。你可能想将该输出用于各种用途,例如可视化或继续分析。但首先,你应该查看这些文件以验证输出。每个文件都是非常大的。本节回顾一下,处于验证目的查看这些文件中一小部分的步骤。
首先,获取输出目录的列表,如下(假设你当前的hdfs文件夹是/user/hdfs/):
hdfs dfs -ls output/c5/select
此代码应生成以下清单:
-rw-r--r-- 3 hadoop hadoop 0 2014-01-26 06:45 output/c5/select/_SUCCESS drwxr-xr-x - hadoop hadoop 0 2014-01-26 06:39 output/c5/select/_logs -rw-r--r-- 3 hadoop hadoop 232132738 2014-01-26 06:45 output/c5/select/part-m-00000 -rw-r--r-- 3 hadoop hadoop 58426989 2014-01-26 06:42 output/c5/select/part-m-00001
包含程序输出的文件是part-m-00000和 part-m-00001。这些文件可通过执行hdfs版本的cat命令来查看。
hdfs dfs –cat output/c5/select/part-m-00000 hdfs dfs –cat output/c5/select/part-m-00001
这将产生大量输出。不过,文件的最后几行可通过执行hdfs版本的tail命令查看。
hdfs dfs –tail output/c5/select/part-m-00000 hdfs dfs –tail output/c5/select/part-m-00001
需要注意的是每个输入文件是由它自己的Mapper处理,每个输出文件也由各自的Mapper产生的。因此,每个输出文件包含仅1年的列表,类似于输入文件,但不分先后顺序。在我们的系统中,part-m-00000包含1988年记录的输出,part-m-00001包含了1987年记录的输出。每个单独的运行可以是不同的。
表5-4和5-5显示了每个输出文件的最后几行
表5-4 part-m-00000文件的最后五行
... 12/12/1988,1325,2043,HNL,LAX,2556,318,309,0,9 12/13/1988,1325,2038,HNL,LAX,2556,313,309,0,4 12/14/1988,1325,2045,HNL,LAX,2556,320,309,0,11 12/01/1988,2027,2152,ATL,MCO,403,85,78,0,7 12/02/1988,2106,2229,ATL,MCO,403,83,78,39,44
表5-5 part-m-00001文件的最后五行
... 12/11/1987,1530,1825,ORD,EWR,719,115,113,0,2 12/13/1987,1530,1815,ORD,EWR,719,105,113,0,-8 12/14/1987,1530,1807,ORD,EWR,719,97,113,0,-16 12/01/1987,1525,1643,BOS,EWR,200,78,73,0,5 12/02/1987,1540,1706,BOS,EWR,200,86,73,15,28
5.3.8 以SELECT探索重述Hadoop的关键特性
当你执行SELECT子句时,探索以下Hadoop的关键特性并学会以下内容:
- 如何创建文件夹并复制本地文件到HDFS
- 如何编写一个仅映射任务
- 如何解释MapReduce任务的控制台日志输出
- 如何获取MapReduce任务输出目录的目录列表
- 如何查看MapReduce任务的实际输出
5.3.9 问题定义:WHERE 子句
现在,你可以添加一个WHERE子句精确以前的结果。可以筛选结果,包括到达或起飞延迟超过10分钟的航班。还可以添加额外的s属性来标识航班到达、起飞,或到达起飞途中是否延迟。该属性被称为延迟点,且采用以下值之一:
- 0 代表在起点延迟
- D代表在目的地延迟
- B代表在起点和目的地都延迟
注意,我们使用值0,D和B代替Origin, Destination 和 Both。这种替代不仅是为了简洁。当运行一个典型的MapReduce程序,会产生大量的输出,而对于大多数MapReduce程序来说,其主要瓶颈是磁盘或网络I / O。当大量数据被写入到磁盘或通过网络转移,限制字段大小可使MapReduce任务的运行性能有显著提高。
执行WHERE子句的程序是org.apress.prohadoop.c5.WhereClauseMRJob。
表5-6 显示了WhereClauseMRJob源代码列表的相关部分。
表5-6 WhereClauseMRJob.java
package org.apress.prohadoop.c5;
//import statements
public class WhereClauseMRJob extends Configured implements Tool{
public static class WhereClauseMapper
extends Mapper<LongWritable, Text, NullWritable, Text> {
private int delayInMinutes = 0;
@Override
public void setup(Context context){
this.delayInMinutes = context.getConfiguration().getInt("map.where.delay",1);
}
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
if (AirlineDataUtils.isHeader(value)) {
return;
//Only process non header rows
}
String[] arr = AirlineDataUtils.getSelectResultsPerRow(value);
String depDel = arr[8];
String arrDel = arr[9];
int iDepDel = AirlineDataUtils.parseMinutes(depDel, 0);
int iArrDel = AirlineDataUtils.parseMinutes(arrDel, 0);
StringBuilder out = AirlineDataUtils.mergeStringArray(arr, ",");
if (
iDepDel >=this.delayInMinutes
&& iArrDel >=this.delayInMinutes){
out.append(",").append("B");
context.write(NullWritable.get(), new Text(out.toString()));
}
else if (iDepDel >=this.delayInMinutes){
out.append(",").append("O");
context.write(NullWritable.get(), new Text(out.toString()));
}
else if (iArrDel >=this.delayInMinutes) {
out.append(",").append("D");
context.write(NullWritable.get(), new Text(out.toString()));
}
}
}
public int run(String[] allArgs) throws Exception {
Job job = Job.getInstance(getConf());
...
job.setMapperClass(WhereClauseMapper.class);
String[] args = new GenericOptionsParser(getConf(),allArgs).getRemainingArgs();
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
Boolean status = job.waitForCompletion(true);
....
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int res = ToolRunner.run(new WhereClauseMRJob(), args);
}
}
此例是建立在前面部分探讨过的SELECT子句任务上的。它适用于SELECT结果顶部的WHERE子句。此外,我们不产生数分钟的硬编码延迟,我们希望它是由用户提供的运行参数。在前面的列表中,此参数被称为map.where.delay,在Mapper的设置方法中读取,这将在下一节介绍。
5.3.10 WhereClauseMapper类
当 Mapper(或Reducer)启动时,每个Mapper(或Reducer))都有一个被调用一次的设置方法。该设置方法是用来初始化映Mapper(或Reducer))的级属性或初始化任务级资源。
在Mapper(或Reducer))中,也有任务结束时被调用一次的清理方法。它被用于执行任务结束操作,如释放资源回到它们的资源池。
在第六章讨论DistributedCache时,你会再次见到这些方法。
- 注意: 设置方法的一个常用的用途是打开网络资源,而清理方法是用于关闭网络资源。例如,如果你用MapReduce来向搜索引擎,如apache solr,批量索引文档,设置方法是用来打开与solr的连接并保持作为Mapper-or reducer-level实例的属性连接。清理方法用于关闭与搜索引擎的连接。
延迟(以分钟计)是从Context实例读取的,如下:
context.getConfiguration().getInt(“map.where.delay”,1);
提供的默认1分钟是为了确保如用户忘记提供值,只有延迟的航班需返回。
The Configuration instance used to configure the job is accessible in all the remote tasks (Mapper and Reducer).
It is accessed through the Context instance, which is different for the Mapper and Reducer:
可配置实例用来对进入所有远程的任务(Mapper and Reducer)进行配置
可通过Context实例访问,这与Mapper和Reducer不同。
- Mapper: apache.hadoop.mapreduce.Mapper.Context
- Reducer: apache.hadoop.mapreduce.Reducer.Context
WhereClauseMapper在配置上与前面部分所提的SelectClauseMapper非常类似。在其中执行以下操作序列:
- AirlineDataUtils.getSelectResultsPerRow(value)从较大的输入行中获取所需的列。
- depDel = arr[8] and arrDel = arr[9]分别提取起飞延迟和到达延迟
- AirlineDataUtils.parseMinutes(String minutes, int defaultValue)以字符串格式将前述延迟转换为整数。该数据集采用NA来表示空。如果字符串到整数解析失败,该函数将返回defaultValue的值。此例中用到了默认值0,这表明当属性值为NA时,则没有延迟。
- 接下来的几行在用一项指标(其值显示延迟发生的位置)适当地扩充它之后,将行(仅包括第一个项目符号中检索到的字段)写入输出。
5.3.11 在集群上运行WHERE子句任务
最后,我们用Maven重建,并在Hadoop环境下执行任务如下:
hadoop jar prohadoop-0.0.1-SNAPSHOT.jar org.apress.prohadoop.c5.WhereClauseMRJob –D map.where.delay=10 \ /user/hdfs/sampledata /user/hdfs/output/c5/where
前述命令的关键区别在于参数是如何被传递到作业。这与System参数用-D选项通过命令行传递到Java程序的方式是非常相似的。然而,一个关键的区别是:不像Java程序,MapReduce程序中-D和名称/值对之间有一个空格字符。
传递到作业的-D选项都可以通过配置对象传递。在这个例子中,-D map.where.delay=10,相当于在run()函数中做以下直接调用:
job.getConfiguration().set("map.where.delay", "10");
如配置类中的getInt()函数,是get(String paramName, String paramValue)方法上的辅助方法。
5.3.12 再访GenericOptionsParser
GenericOptionsParser在第3章讨论过,同时在使用Hadoop任务的第三方库时对它的效用进行了探讨。在上一节,GenericOptionsParser被用来将命名参数传递到任务。
总之,GenericOptionsParser可用于执行以下操作:
- 用–libjars <comma separated jar paths>传递第三方库
- 用–D <name>=<value>传递自定义命名参数
用于提取用户定义参数的调用如下:
new GenericOptionsParser(getConf(), allArgs).getRemainingArgs();
在该例中,一个包含任务输入路径和输出路径的数组被返回。
5.3.13 用WHERE子句探索Hadoop的关键特性
当我们执行WHERE子句时,我们讨论以下Hadoop的新特征:
- GenericOptionsParser传递命名自定义参数到任务的作用
- 设置和清理方法的作用
5.3.14 Map和Reduce任务(聚集查询)
SQL的另一个常用的语言元素是聚集查询。聚合函数如SUM,COUNT,MAX和MIN,与GROUP BY和HAVING子句一起,——使得SQL通常用于计算数据聚合。
本节将介绍如何使用MapReduce任务来计算聚合。在本章中,你将第一次见到同时使用Map 和 Reduce阶段的任务。
5.3.15 问题定义:GROUP BY和SUM子句
我们先来确定预计航班月份中是否有任何模式延迟。通过月份你可以确定准点航班的比例,并通过月份获得取消/更改航班的比例。本节中探讨以下MapReduce功能:
- 使用Mapper执行部分计算以减少Mapper和在Mapper决定的航班是否按时到达/起飞之间的I/O。用Mapper上一个简单的指标变量传递到Reducer来标识它。这比将全部输入传递到Reducer并在那里执行计算显然要划算得多。这样的决定对好的Map Reduce开发至关重要。
- 用Reducer来计算聚合
- 输出数据集包含以下属性:
- 起飞月份
- 该月航班记录总数
- 准点到达航班的比例
- 延迟到达航班的比例
- 准点起飞航班的比例
- 延迟起飞航班的比例
- 取消航班的比例
- 改道航班的比例
- 对于该例,如果与延迟起飞和延迟到达有关的字段为NA,我们把该值视为0,这表明该活动没有延迟。对于Cancellation属性,我们假设NA表示该航班没有被取消;对于Diverted属性,我们假设NA表示该航班没有改道。
刚刚所描述的执行聚合的程序如下:
org.apress.prohadoop.c5.AggregationMRJob
5.3.16 run( )方法
run()方法中对该任务来说不同的关键行如下:
job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(NullWritable.class); job.setOutputValueClass(Text.class); job.setMapperClass(AggregationMapper.class); job.setReducerClass(AggregationReducer.class); job.setNumReduceTasks(1);
注意前四行。这个例子中Mapper 的输出键和值类与Reducer 的输出键和值类不同。必须显式地调用setMapOutputKeyClass、setMapOutputValueClass,因为它们的实际值与默认值不同(分别为LongWritable和Text,其原因如前面所述)。setOutputKeyClass和setOutputValueClass声明我们在本部分已定义的、有关SELECT子句MapReduce实现的输出键和值类。如果Mapper 输出键和值与Reducer输出键和值相同,那么只调用setOutputKeyClass和setOutputValueClass就足够了。该框架将通过调用getOutputKeyClass和getOutputValueClass方法来假定Mapper输出键类和Mapper输出值类。本例清楚地说明了什么时候两组函数都必须设置。当你在AggregationMapper和AggregationReducer类中读到此时,可回过来重温本部分。
我们设置Mapper和Reducer类,并表明我们将使用一个减速器。最后一行是可选的,因为MapReduce框架默认一个MapReduce任务使用一个减速器。第6章中将探讨此默认值需改变的情况。
5.4 AggregationMapper类
我们定义AggregationMRJob类级别变量、IntWritable的实例如下:
public static final IntWritable RECORD=new IntWritable(0); public static final IntWritable ARRIVAL_DELAY=new IntWritable(1); public static final IntWritable ARRIVAL_ON_TIME=new IntWritable(2); public static final IntWritable DEPARTURE_DELAY=new IntWritable(3); public static final IntWritable DEPARTURE_ON_TIME=new IntWritable(4); public static final IntWritable IS_CANCELLED=new IntWritable(5); public static final IntWritable IS_DIVERTED=new IntWritable(6);
这些行中的每行都是一个Mapper传递给Reducer的标记变量。每个Mapper输出的key是编码为两位数的月值,“0”左填充字符串。
表5-7 显示的是AggregationMapper内部类的map()方法
表5-7 AggregationMapper的map()方法
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if(!AirlineDataUtils.isHeader(value)){
String[] contents = value.toString().split(",");
String month = AirlineDataUtils.getMonth(contents);
int arrivalDelay = AirlineDataUtils.parseMinutes(AirlineDataUtils.getArrivalDelay(contents),0);
int departureDelay =AirlineDataUtils.parseMinutes(AirlineDataUtils.getDepartureDelay(contents),0);
boolean isCancelled = AirlineDataUtils.parseBoolean(AirlineDataUtils.getCancelled(contents),false);
boolean isDiverted = AirlineDataUtils.parseBoolean(AirlineDataUtils.getDiverted(contents),false);
context.write(new Text(month), RECORD);
if(arrivalDelay>0){
context.write(new Text(month), ARRIVAL_DELAY);
}
else{
}
context.write(new Text(month), ARRIVAL_ON_TIME);
if(departureDelay>0){
context.write(new Text(month), DEPARTURE_DELAY);
}
else{
}
context.write(new Text(month), DEPARTURE_ON_TIME);
if(isCancelled){
context.write(new Text(month), IS_CANCELLED);
}
if(isDiverted){
context.write(new Text(month), IS_DIVERTED);
}
}
该方法从航空公司数据中提取关键字段,如下所示:
- 到达延迟(以分钟计)
- 起飞延迟(以分钟计)
- 航班是否取消
- 航班是否延迟
基于不同的条件,调用context.write():
- 每个记录都调用context.write(new Text(month), RECORD)。我们正计算比例。该调用用来计算某一给定月份Reducer中的记录总数
- context.write(new Text(month), ARRIVAL_DELAY)调用显示到达延迟的记录。
- context.write(new Text(month), ARRIVAL_ON_TIME)调用显示准点到达的记录。
- context.write(new Text(month), DEPARTURE_DELAY)调用显示起飞延迟的记录。
- context.write(new Text(month), DEPARTURE_ON_TIME)调用显示准点起飞的记录。
- context.write(new Text(month), IS_CANCELLED)调用显示取消航班的记录。
- context.write(new Text(month), IS_DIVERTED)调用显示改道航班的记录。
5.5 Reduce 阶段
The Reducer has three important phases:
Reducer 有三个重要阶段:
- 排序:Mapper的输出是由键(排序的确切机制将在第6章讨论)来排序。目前为止,接受Mapper输出是由月份键按从01-12的字典顺序来排序的。
- 洗牌:MapReduce框架把输出从Mapper复制到Reducer。洗牌阶段将在第6章进行更详细的讨论。
- Reduce: 在此步骤中,所有相关联的记录必须一起由一个实体进行处理,它是自定义的Reducer类的实例。列表5-8显示了AggregationReducer的定义。
表5-8 AggregationReducer定义
public static class AggregationReducer extends Reducer<Text, IntWritable, NullWritable, Text> {
public void reduce(Text key, Iterable<IntWritable> values, Context context)
...
}
}
AggregationReducer的定义作以下断言:
- Reducer 的输入键类是Text。这与Mapper 输出的键类相同。该键的值是格式化为两个字符串的月份(如01,02..,12)。
- Reducer 的输入值类是IntWritable。这与Mapper 输出的值类相同。
- 接下来注意reduce方法的定义。第一个参数是键类(Text)的一个实例。第二个参数是Iterable<IntWritable>的一个实例。从Iterable实例中出现的每个实例都能显示:该记录是否是一个简单的计数器(RECORD),航班是否准点到达或起飞,航班是否延迟到达或起飞,或航班是否取消或改道。
- 类似于前面的例子,由于输出是一个CSV文件,因此reducer 输出键类被声明为NullWritable,reducer 输出值类被声明为Text。
表5-9 显示了实际的计数器在for循环中是如何递增的。 for循环退出后,确保该月份所有的计数器都被完全处理,并准备和写入最终的输出。
表5-9 AggregationReducer的Reduce()方法
public void reduce(Text key, Iterable<IntWritable> values, Context context) {
double totalRecords = 0;
double arrivalOnTime = 0;
double arrivalDelays = 0;
double departureOnTime = 0;
double departureDelays = 0;
double cancellations = 0;
double diversions = 0; for(IntWritable v:values){
if(v.equals(RECORD)){ totalRecords++;
}
if(v.equals(ARRIVAL_ON_TIME)){ arrivalOnTime++;
}
if(v.equals(ARRIVAL_DELAY)){ arrivalDelays++;
}
if(v.equals(DEPARTURE_ON_TIME)){ departureOnTime++;
}
if(v.equals(DEPARTURE_DELAY)){ departureDelays++;
}
if(v.equals(IS_CANCELLED)){ cancellations++;
}
if(v.equals(IS_DIVERTED)){ diversions++;
}
}
DecimalFormat df = new DecimalFormat( "0.0000" );
//Prepare and produce output
StringBuilder output = new StringBuilder(key.toString());
output.append(",").append(totalRecords);
output.append(",").append(df.format(arrivalOnTime/totalRecords));
output.append(",").append(df.format(arrivalDelays/totalRecords));
output.append(",").append(df.format(departureOnTime/totalRecords));
output.append(",").append(df.format(departureDelays/totalRecords));
output.append(",").append(df.format(cancellations/totalRecords));
output.append(",").append(df.format(diversions/totalRecords));
context.write(NullWritable.get(), new Text(output.toString()));
}
注意以下MapReduce框架的保障:
- 所有与特定键相关、为Mapper输出一部分的输出都由同一reducer在同一reduce调用中处理。即使当同一键是由多个映射器产生时也是如此。在这个例子中,我们选择只有一个reducer,但即使reducer数目大于一时,该规则仍适用。
- 只有被reducer处理的键进行排序。Iterable实例中与由reducer接收的键相关的以及reduce调用中被处理的值默认不排序,其顺序在运行中可能会发生变化。在第六章中,我们将再次讨论排序,它是一种基于用户定义标准、为reduce-side值(与reduce-side输入键相反)排序的方法。
- 尽管从Reducer的角度来说,所有键都排序,但它们并不跨Reducer排序。因为只使用一个Reducer,输出按月份正确排序,1月份的输出在2月份之前,以此类推直到12月。然而,如果我们使用了两个Reducer,那么第一个Reducer获取01,03,05,07,09,11键,第二个Reducer获取02,04,06,08,10,12键将是有可能的。注意,对每个Reducer而言这些键排序,但并不跨Reducer排序。在第6章讨论的排序中,你可以了解更多关于跨Reducer总排序的知识。
- 注意 新的MapReduce程序员们一个常见的错误是重用Reducer内for循环跨迭代值的实例。当计算需要用前面迭代中的值跨迭代执行时,此过程完成,并产生不正确的结果。在每次迭代期间MapReduce框架不提供新的IntWritable实例(在该例中)。相反,HadoopReducer中的迭代器只使用一个实例,其值在每次迭代中都会变化。跨迭代重用这些引用可能导致很难去调试其中错误。
5.5.1 在集群中运行GROUP BY 和 SUM子任务
最后,我们用Maven重建,并在Hadoop环境中执行如下任务:
hadoop jar prohadoop-0.0.1-SNAPSHOT.jar org.apress.prohadoop.c5.AggregationMRJob /user/hdfs/ sampledata \ /user/hdfs/output/c5/aggregation
5.3.20 整个数据集的结果
执行从1987到2008年整个数据集的任务,并绘出输出图,用X轴上的月份产生图5-1中所示的曲线图。
表5-1 每月航班延迟/取消/改道图表
图5-1显示了以下内容:
- 六月至八月夏季月份期间航班延迟增加。在美国学校是在这几个月关闭,所以六月到八月是一个受欢迎的度假季节。
- 十二月到三月冬季月份期间延迟增加,可能是由于降雪造成的恶劣天气。
- 十二月到三月期间,由于天气原因,航班取消也呈上升趋势。有趣的是,九月份航班取消也有增加,难道是由于2001年9月11日大量航班取消的原因?要检验这一假设还需更详细的分析。
用完整数据集输出的整个列表如表5-10所示。
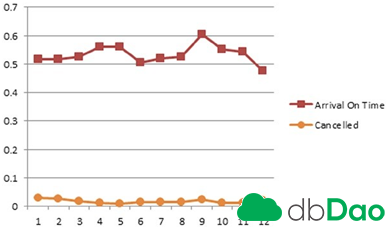
表5-10 在完整数据集上执行的AggregationMRJob输出
01,8473442.0,0.5176,0.4824,0.5851,0.4149,0.0295,0.0029 02,7772317.0,0.5166,0.4834,0.5853,0.4147,0.0258,0.0025 03,8606145.0,0.5258,0.4742,0.5845,0.4155,0.0189,0.0021 04,8305404.0,0.5603,0.4397,0.6288,0.3712,0.0114,0.0018 05,8510026.0,0.5596,0.4404,0.6330,0.3670,0.0103,0.0019 06,8424353.0,0.5061,0.4939,0.5639,0.4361,0.0141,0.0028 07,8715855.0,0.5204,0.4796,0.5712,0.4288,0.0143,0.0028 08,8768265.0,0.5270,0.4730,0.5827,0.4173,0.0140,0.0025 09,8192348.0,0.6037,0.3963,0.6780,0.3220,0.0249,0.0017 10,8908173.0,0.5524,0.4476,0.6336,0.3664,0.0117,0.0017 11,8451547.0,0.5442,0.4558,0.6124,0.3876,0.0113,0.0019 12,8740941.0,0.4751,0.5249,0.5269,0.4731,0.0220,0.0029
5.5.2 以GROUP BY和SUM探索重述Hadoop的关键特性
随着聚合功能的实现,我们讨论以下Hadoop的新特征:
- 开发定制Reducers
- 执行定制聚合的技巧
5.6 用组合器改善聚合性能
本节讨论了可添加到MapReduce程序用以大幅度提高其性能的一个重要优化。在上一节讨论的聚集例子中,每个记录都被从 Mapper传送到Reducer。在Reducer中,我们执行聚合,并且只写了12条记录:每月一条记录。几种情况下的聚合可累计。记录的部分集可以聚合,然后将部分聚合组合成一个最终的聚集。 MapReduce提供在Mapper节点中执行部分聚合的方法。本节阐述了MapReduce API的这一特点。
5.6.1 问题定义:优化聚合器
在每个记录的AggregationMRJob中, AggregationMapper输出最少三条、最多四条记录。
- 每条记录都有一个记录标记。
- 每条记录都有一个准点到达标记或延迟到达标记。
- 每个记录都有一个准点起飞标记或延迟起飞标记。
- 一个记录可以有一个取消标记,但已标记为取消的记录不能有改道标记。
- 一个记录可以有一个改道标记,但已标记为改道的记录不能有取消标记。
所有这些记录需要被移动到Reducer。大多数Mapper中的Reducer 任务在单独的机器上运行。鉴于有超过100万条记录, 300 〜400万条记录正从Mapper移动到Reducer ,这是一项昂贵的操作。
用组合器类可实现相当大的I / O存储量,组合器类是Mapper输出中运行在Mapper机器上的迷你Reducer。实际上,该组合器被作为Reducer类的子类执行。最后的输出仅包含12行。为简单起见,假设每个输入文件启动一个Reducer,那么有22台Mapper。如果每个Mapper产生一次中间输出(每年适当值的总和),每个Mapper仅发送12(月键数)×4 = 48行到Reducer。那么22台映射器,共1056行从Mapper机器被发送到Reducer机器。这与我们通过网络传送的400万行进行比较,这是一个近似值;在内存中生成这些中间行。由于内存限制,在达到某一阈值的内存后,因为输入行正在处理中,Mapper也可能调用组合器多次。(在本章末更详细地讨论排序/洗牌时,你将再次访问这一功能)。
上一节中所述执行聚合的程序如下:
org.apress.prohadoop.c5.AggregationWithCombinerMRJob
在完整数据集运行时,可得到以下数据:
- 启动映射任务= 22
- Mapper 输入记录= 101,868,834
- Mapper 输出记录= 307,596,518
- 组合器输入记录= 307,596,518
- 组合器输出记录= 3,395
- Reducer输入记录= 3,395
组合器输出记录计数表明, 每个Mapper大约调用4次组合器。
5.6.2 AggregationWithCombinerMRJob类中的AggregationMapper类
使用组合器时,必须要遵循其使用要求,这通常包括修改Mapper、组合器及Reducer的输出键和值类。
组合器的关键限制是,该组合器类的输入和输出键和值类必须与Mapper对应的输出键和值类匹配。回想一下,组合器是运行在Mapper节点上的迷你Reducer,组合器输出也被发送到Reducer,Reducer不知道它正接收的输入是直接来自Mapper还是途中经组合器处理过,因此Mapper的输出键和值类应该与组合器的输入键和值类匹配。同样地,组合器的输出键和值类必须与Reducer的输入键和值类匹配。这自然意味着组合器的输出键和值类必须与Mapper的输出键和值类相同,所以我们必须重写Mapper和Reducer。此前,AggregationMapper仅仅必须随着月份键发送一个IntWritable标记。在Reducer中,我们检查标记是否存在,并使各个标记的有关变量递增1个(例如,ARRIVAL_ON_TIME)。
But with the user of the Combiner, it is not enough to send this marker. We need to send the aggregation (SUM) value along with the marker type, which is the partial sum computed at the end of each Mapper. The output of AggregationMapper is MapWritable. It has two key value pairs:
但对组合器的用户,只发送这个标记是不够的。我们需要发送聚集(SUM)值连同标记类型,标记类型是在每个Mapper最后计算的部分和。 AggregationMapper的输出为MapWritable 。它有两个键值对:
- TYPE, 表示标记类型(例如,ARRIVAL_ON_TIME)
- VALUE, 为IntWritable(1)
AggregationCombiner在Mapper机器上充当中间Reducer,产生一个输出为MapWritable。它有两个键值对:
- TYPE, 表示标记类型(例如,ARRIVAL_ON_TIME)
- VALUE, 是该类型从Mapper接收的所有IntWritable实例的中间和
AggregationReducer在组合器运行后,接收来自Mapper机器的输出并执行最终计算,类似于AggregationCombiner。
表5-11 显示了AggregationMapper类源代码中的关键变化。
表5-11 AggregationWithCombinerMRJob中的AggregationMapper
public static class AggregationMapper
extends Mapper<LongWritable, Text, Text, MapWritable> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
if(!AirlineDataUtils.isHeader(value)){
......
context.write(new Text(month),
getMapWritable(RECORD,new IntWritable(1)));
if(arrivalDelay>0){
context.write(new Text(month), getMapWritable(ARRIVAL_DELAY,new IntWritable(1)));
}
else{
context.write(new Text(month), getMapWritable(ARRIVAL_ON_TIME,new IntWritable(1)));
}
if(departureDelay>0){ context.write(new Text(month),
getMapWritable(DEPARTURE_DELAY,new IntWritable(1)));
}
else{
context.write(new Text(month), getMapWritable(DEPARTURE_ON_TIME,new IntWritable(1)));
}
if(isCancelled){ context.write(new Text(month),
getMapWritable(IS_CANCELLED,new IntWritable(1)));
}
if(isDiverted){
context.write(new Text(month), getMapWritable(IS_DIVERTED,new IntWritable(1)));
}
}
}
private MapWritable getMapWritable(IntWritable type,IntWritable value){
MapWritable map = new MapWritable();
map.put(TYPE, type); map.put(VALUE, value);
return map;
}
}
表5-12显示的是AggregationCombiner类源代码。注意,它扩展Reducer 类,就像AggregationReducer一样。还要注意,它执行中间聚合(SUM)并调用context.write。
表5-12 AggregationWithCombinerMRJob中的AggregationCombiner
public static class AggregationCombiner extends Reducer<Text, MapWritable, Text, MapWritable> {
public void reduce(Text key,
Iterable<MapWritable> values, Context context) throws IOException,
InterruptedException {
int totalRecords = 0;
int arrivalOnTime = 0;
int arrivalDelays = 0;
int departureOnTime = 0;
int departureDelays = 0;
int cancellations = 0;
int diversions = 0;
for(MapWritable v:values){
IntWritable type = (IntWritable)v.get(TYPE);
IntWritable value = (IntWritable)v.get(VALUE);
if(type.equals(RECORD)){
totalRecords=totalRecords+value.get();
}
if(type.equals(ARRIVAL_ON_TIME)){
arrivalOnTime=arrivalOnTime+value.get();
}
if(type.equals(ARRIVAL_DELAY)){ arrivalDelays=arrivalDelays+value.get();
}
if(type.equals(DEPARTURE_ON_TIME)){
departureOnTime=departureOnTime+value.get();
}
if(type.equals(DEPARTURE_DELAY)){ departureDelays=departureDelays+value.get();
}
if(type.equals(IS_CANCELLED)){ cancellations=cancellations+value.get();
}
if(type.equals(IS_DIVERTED)){ diversions=diversions+value.get();
}
}
context.write(key, getMapWritable(RECORD,new IntWritable(totalRecords)));
context.write(key, getMapWritable(ARRIVAL_ON_TIME,new IntWritable(arrivalOnTime)));
context.write(key, getMapWritable(ARRIVAL_DELAY,new IntWritable(arrivalDelays)));
context.write(key, getMapWritable(DEPARTURE_ON_TIME,new IntWritable(departureOnTime))); context.write(key, getMapWritable(DEPARTURE_DELAY,new IntWritable(departureDelays)));
context.write(key, getMapWritable(IS_CANCELLED,new IntWritable(cancellations)));
context.write(key, getMapWritable(IS_DIVERTED,new IntWritable(diversions)));
}
private MapWritable getMapWritable(IntWritable type,IntWritable value){
//
}
}
表5-13展示了源代码AggregationReducer类的新版本,与上一节中的版本非常类似。注意,它用从组合器接收的中间聚合的值来执行最终聚合。
表5-13 AggregationWithCombinerMRJob中的AggregationReducer
public static class AggregationReducer
extends Reducer<Text, MapWritable, NullWritable, Text> {
public void reduce(Text key,
Iterable<MapWritable> values, Context context)
throws IOException, InterruptedException {
double totalRecords = 0;
double arrivalOnTime = 0;
double arrivalDelays = 0;
double departureOnTime = 0;
double departureDelays = 0;
double cancellations = 0;
double diversions = 0;
for(MapWritable v:values){
IntWritable type = (IntWritable)v.get(TYPE);
IntWritable value = (IntWritable)v.get(VALUE);
if(type.equals(RECORD)){
totalRecords=totalRecords+value.get();
}
if(type.equals(ARRIVAL_ON_TIME)){
arrivalOnTime=arrivalOnTime+value.get();
}
if(type.equals(ARRIVAL_DELAY)){
arrivalDelays=arrivalOnTime+value.get();
}
if(type.equals(DEPARTURE_ON_TIME)){
departureOnTime=departureOnTime+value.get();
}
if(type.equals(DEPARTURE_DELAY)){
departureDelays=departureDelays+value.get();
}
if(type.equals(IS_CANCELLED)){
cancellations=cancellations+value.get();
}
if(type.equals(IS_DIVERTED)){
diversions=diversions+value.get();
}
}
DecimalFormat df = new DecimalFormat( "0.0000" );
//Prepare and produce output StringBuilder
output = new StringBuilder(key.toString());
output.append(",").append(totalRecords);
output.append(",").append(df.format(arrivalOnTime/totalRecords));
output.append(",").append(df.format(arrivalDelays/totalRecords));
output.append(",").append(df.format(departureOnTime/totalRecords));
output.append(",").append(df.format(departureDelays/totalRecords));
output.append(",").append(df.format(cancellations/totalRecords));
output.append(",").append(df.format(diversions/totalRecords));
context.write(NullWritable.get(), new Text(output.toString()));
}
}
5.6.3 run( )方法
run()方法的唯一变化为下面几行:
job.setMapOutputValueClass(MapWritable.class); job.setCombinerClass(AggregationCombiner.class);
- 注意: 使用组合器并不会自动产生更好的性能。该实例中的组合器使用是适当的,因为该组合器产生的行数显著较低( 3,000对3亿),从Mapper 节点被传送到 reducer。这使运行组合器的额外费用更为合理。然而,如果该要求得不到满足,则使用组合器由于需要额外处理,可能会减慢执行。
在集群上运行基于组合器的聚合任务
5.6.4 最后,我们用Maven重建,并在Hadoop环境中执行如下任务:
hadoop jar prohadoop-0.0.1-SNAPSHOT.jar org.apress.prohadoop.c5.AggregationWithCombinerMRJob /user/ hdfs/sampledata \ /user/hdfs/output/c5/combineraggregation
5.6.5 用聚合探索Hadoop的关键聚合特性
随着聚合功能的实现,我们总结出以下Hadoop的新特征:用自定义组合器j减少Mappers和Reducers之间的I/O。
5.7 分区器的作用
上一节讨论了Reducers的使用,它接收键以及这些键的值的列表。从Reducers的角度把键进行排序。虽然为了简单起见,我们假设一个单一Reducer,但在实践中由于性能原因,它并不是一个好的选择。在实践中,使用几十甚至上百Reducer是很常见的。
Hadoop的API确保Reducer处理它所接收到的、由键进行排序的键值对。这并不意味着Reducer-1的键在排序顺序上低于Reducer-0接收的键。默认情况下,从Mapper到达Reducer,这些键是被随机分配的。然而,这种随机分配是一致的。
相同的键总是被路由到相同的Reducer,不论它来自哪个Mapper。在Reducer内,从Mapper接收到的键和值对按排序(由Reducer输入键或Mapper输出键排序)的顺序进行处理。
本节讨论决定哪个键进入哪个Reducer的组件:分区器类。
本节将讨论该类以及如何创建此类的自定义实现。首先,让我们为该讨论创建一个用例上下文。
5.7.1 问题定义:按月划分航空公司数据
假设我们需要把航空公司数据集拆分成单独的文件,每月一份文件,而我们只想分析某个特定月份的数据。例如,我们想分析一月份(一个典型的恶劣天气季节)每周每天的航班延迟图表,然后与六月份(度假季节)同样的分析相比较。
上述程序的列表位于org.apress.prohadoop.c5.SplitByMonthMRJob中。
5.7.2 run( )方法
run()方法中与该任务不同的关键行如下所示:
job.setMapperClass(SplitByMonthMapper.class); job.setReducerClass(SplitByMonthReducer.class); job.setPartitionerClass(MonthPartioner.class); job.setNumReduceTasks(12);
关键区别是包含分区器类,分区器类负责确保键进入适当的Reduce。
虽然我们选择了硬编码Reduce的数量,我们可以用以下选项,作为命令行参数传递Reduce数量:
-D mapred.reduce.tasks=12
5.7.3 Partitioner 分区器
现在我们来看看键是如何在Reducers之间分布的。用以分发跨Reducer键的类是执行的类org.apache.hadoop.mapreduce.Partitioner,分区器实例在同一个JVM中作为Mapper实例执行。其getPartition方法在Mapper实例每次调用context.write时需要。该getPartition方法说明如下:
int getPartition(K key, V value, int numReduceTasks)
这需要一个实例,每个键和值都由Mapper和Reduce任务的数量发出。Reduce任务的数量通过任务配置得知,并在每次getPartition调用中由框架来传递。返回值是Reducer的指标。10台减速器,需要0到9之间的值。
当一个自定义分区器未定义,Hadoop框架使用由类org.apache. hadoop.mapreduce.lib.partition.HashPartitioner定义的默认值。
HashPartitioner在key实例上调用hashCode()方法,并在其上用numReduceTasks作为分母执行取模操作。这解释了每个Reduce是如何得到随机抽样的键。键排序只有在分区器为每个Reducer分离键后才运用。因此,每个Reducer内能看到由键排序的输入,但键不能跨Reducer排序。HashPartitioner使用的确切公式是
key.hashCode() & Integer.MAX_VALUE) % numReduceTasks.
5.7.4 避免分区错误
计算分区时一个常见的错误是使用Math.abs(key.hashCode())%NO_OF_REDUCERS,从而导致返回负值。如果key.hashCode()中之一返回一个等于-2147483648的负值,在值上调用Math.abs()会返回同样的负值,因为其绝对值比Integer.MAX_VALUE多1 。介于在计算机内部表示负数的方式,一个值为-2147483648的整形变量的绝对值是相同的数和其负数。该问题的替代办法就是HashPartitioner实现此功能的方法。HashPartitioner中代码的关键行是key.hashCode() & Integer.MAX_VALUE) % numReduceTasks。& Integer.MAX_VALUE在位级别运行,前一计算 key.hashCode() & Integer. MAX_VALUE对一个-2147483648的hashCode()值返回0,因为-2147483648的所有位与Integer.MAX_VALUE的位表示法不同。解决该问题的另一种方法是,将key. hashCode()转换为,运用长整型变量上的Math.abs()。现在如果hashCode()的返回值是-2147483648 ,一旦它被类型转换为长整型,则该值长实例的绝对值为2147483648 ,因为长变量上有更多的位数来存储该值。或者,可使用Math.abs(key.hashCode()%NO_ OF_REDUCERS),其中在模函数应用于hashCode函数之后,绝对函数被应用。注意,以前的方法都返回分区ID 中的不同值。
5.7.5 SplitByMonthMapper类
表5-14显示了SplitByMonthMapper类的源代码。注意Mapper 输出是如何表示键的。Mapper 输出键是代表飞行记录月份的IntWritable实例。它取从1到12的值。
表5-14 SplitByMonthMapper
public static class SplitByMonthMapper extends
Mapper<LongWritable, Text, IntWritable, Text> {
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
if (!AirlineDataUtils.isHeader(value)) {
int month = Integer.parseInt(AirlineDataUtils.getMonth(
value.toString().split(","));
context.write(new IntWritable(month), value);
}
}
}
5.7.6 SortByMonthAndDayOfWeekReducer类
表5-15显示了SplitByMonthReducer类的源代码,它循环访问每个月的值(这是关键)并将它们发送到输出文件。
表5-15 SortByMonthAndDayOfWeekReducer
public static class SplitByMonthReducer extends
Reducer<IntWritable, Text, NullWritable, Text> {
public void reduce(IntWritable key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text output : values) {
context.write(NullWritable.get(), new Text(output.toString()));
}
}
}
5.7.7 MonthPartitioner类
表5-16显示了MonthPartitoner类的源代码。我们按照设计使用12台reducers ,每个reducer指数仅仅是(month -1),每月从1到12取值 ,这是确保每个月以适当顺序进入各reducer的关键组件。也就是说,一月份的记录去reducer 0 ,二月份的记录去reducer 1 ,依此类推,直到十二月份的记录去到 reducer 11 。
表5-16. MonthPartitioner
public static class MonthPartioner extends Partitioner<IntWritable, Text> {
@Override
public int getPartition(IntWritable month, Text value, int numPartitions) {
return (month.get() - 1);
}
}
5.7.8 在集群中运行分区任务
最后,我们用Maven重建并在Hadoop环境下执行如下任务:
hadoop jar prohadoop-0.0.1-SNAPSHOT.jar org.apress.prohadoop.c5.SplitByMonthMRJob /user/hdfs/ sampledata \ /user/hdfs/output/c5/partitioner
任务完成后,在/user/hdfs/output/c5/partitioner HDFS目录中有12个文件。名为part-r-00000的文件有一月份的记录,part-r-00001文件有二月份的记录,以此类推,part-r-00011文件有十二月份的记录。
- 注意: 只有当你在伪集群或全集群模式下运行任务时,才使用多个reducer 。在本地单点集群中运行此任务仅使用一个reducer ,产生一个输出文件,其数据按月份排序。本地模式下的分区器被忽略,所有的Mapper 输出记录到单一的reducer 中。
5.7.9 用分区器探索Hadoop的关键特性
本节涵盖以下Hadoop的新特征:
- 分区器是如何划分减速器间的键
- 如何开发定制分区器。第6章讨论排序用例时将开发更为复杂的分区器。
- 如何将Reducers 数量作为命令行参数配置到MR程序;例如: -D mapred.reduce.tasks = 12 。注意,该属性在Hadoop2中已被弃用并替换成mapreduce.job.reduces 。然而旧属性仍然是有效的,并被广泛使用。因此,我们在本书中将继续使用旧的属性名称,因为你很有可能在实践中遇到它们。事实上,任何一种以mapred而不是MapReduce开头的属性,在Hadoop 2中都可能被弃用。如果你想使用新版本,请检查文档进行相应的替换。Hadoop 2.2.0的链接为:http://hadoop.apache.org/docs/r2.2.0/hadoop-project-dist/hadoop-common/ DeprecatedProperties.html.
5.8 综合范例
最后几节讨论MapReduce的主要功能。我们仔细观察了Mapper,Reducer,Partitioner,以及Combiner 组件。图5-2将它们都聚集在一个图表中来展示它们是如何协同工作的。注意这些部件运行的位置,这是真正理解MapReduce的关键 。
图5-2没有提到输入值是如何被反馈到Mapper节点的,这将在第7章描述InputFormat界面时进行讨论。现在,假设Mapper以某种方式得到一组正确的键和值对。

图5-2 综合范例
Mapper 的目标是产生一个由Mapper 输出键排序的分区文件。分区涉及处理键的reducers。Mapper 发出其键和值对之后,它们被反馈到与Mapper 运行在同一JVM中的一个分区实例中。Partitioner 在reducers数量和任何自定义分区逻辑的基础上,对Mapper 输出进行分区。然后结果由Mapper 输出键进行排序。这时,在已排序的输出上Combiner 被调用(如果任务配置了一个组合器的话)。注意Combiner 是在分区器与Mapper 在同一JVM中后被调用的。最后该已分区、排序、合并的输出被溢出到磁盘。根据情况,Mapper 中间输出可被压缩。压缩将在第7章中讨论。压缩可减少I / O,因为这些Mapper 输出文件被写入Mapper 节点的磁盘上。压缩也可减少网络I / O,因为这些压缩文件都被传送到reducers节点上了。
在Mapper 节点上按以下步骤进行:
1.Mapper 上通过context.write调用收集的记录填满保持在Mapper 上的缓冲区。该缓冲区的大小由mapreduce. task.io.sort.mb属性限定,默认值是512 MB。缓冲区的大小控制着.Mapper节点上排序处理的效率。尺寸越大,排序越有效率。然而,内存是有限资源,增加这个尺寸将会限制节点上可启动的.Mapper数量。因此,应该尽力实现排序效率和并行度之间的权衡。
2.当缓存填充到达由属性mapreduce.map.sort.spill. percent限定的程度后,后台线程将启动,将内容溢出到磁盘。此属性的默认值是0.8(80%)。如果溢出正在进行,即使超过这个阈值,context.write的.Mapper端调用也不会阻塞。因此,一次溢出中写入磁盘的数据量可能超过此阈值,使其溢出到由mapreduce.cluster.local.dir属性以循环方式定义的目录中的文件中。
3.在数据被写入磁盘之前,Partitioner 被调用,在每个分区内创建一个分区,在内存中按键进行排序(记住,Reducer以排序的顺序接收其键。第6章中我们将学习如何定义排序的顺序)。如果一个组合器被定义,那么它将在排序的输出上被执行。
4.在Mapper 执行过程中,mapreduce.map.sort.spill.percent可能会超出多次。每次超出该阈值时,都有一个新的溢出文件被创建。当Mapper 最终完成时,Mapper 的本地磁盘上可能有几个分区溢出文件。它们被合并为一个分区、排序文件。一次传递中合并的溢出数量由属性mapreduce.task.io.sort.factor限定。其默认值是10。如果有比属性mapreduce.map.combine.minspills所定义的更多的文件要合并,则在创建最终文件之前组合器再次被调用。记住,组合器可被调用多次,而不影响最终结果。
洗牌阶段确保分区到达适当的Reducers。在洗牌阶段,每个Reducers使用HTTP协议从 Mapper 节点检索自己的分区。每个Reducer 默认采用五个线程来从Mapper 节点pull回属性mapreduce.reduce.shuffle.parallelcopies定义的自己的分区。但Reducer 如何知道查询哪一个节点来获得它们的分区?这在整个主应用程序期间都会发生。当每个Mapper 实例完成时,它会通知主应用程序有关其运行过程中产生的分区。每个Reducer 定期查询主应用程序的Mapper 主机,直到它收到托管其分区的节点最终名单。当已完成总Mapper 实例的比例超过了属性mapreduce.job.reduce.slowstart.completedmaps的设定值时,reduce阶段开始。
在Reducer 节点上,这些预先排序的Mapper输出被合并(排序的合并阶段)。最后,排序键-值对由Reducer 通过调用reduce方法来处理。在Reducer 实例第一次调用reduce之前,所有用于Reducer 的Mapper输出键-值对由Mapper输出键(或Reducer 输入键)进行排序。这能够确保Reducer 处理由其输入键排序的Mapper输出。此外,reduce调用支持的Iterable接口。在一个给定键调用reduce之前,键的整个值集不被加载在内存中。在reduce调用内,它逐个服务于给定键,因为运行时会在Iterable接口上执行迭代(配以适当的内存缓冲,以确保效率)。在Reduce内的Iterable实例上,排序文件通过每次的next()调用按顺序读取。由于随着Reducer 实例上新键的出现,键会改变新的reduce调用,一个新的Iterable实例被创建,它将通过继续从排序文件读取键-值对来服务新键的值。这是MapReduce需要有排序阶段的主要原因。在reduce调用内部,通过熟悉的Iterable接口,排序阶段使得给定键数的百万的值得到有效处理(在一次传递中读取一份文件,其记录是由Reducer 输入键排序的)。而不会内存溢出或在一个reducer 输入文件中进行多次传递。可被用来优化减速器节点上的排序行为的参数包括:
- mapreduce.reduce.shuffle.input.buffer.percent – 这是专用于存储洗牌阶段从mapper 检索到的map输出的堆内存比例。如果一个特定的mapper输出足够小,它就会被检索到该内存中,否则它将保持在reducer的本地磁盘中。
- mapreduce.reduce.shuffle.merge.percent – 这是由mapreduce.reduce.shuffle.input.buffer.percent定义的堆内存使用率阈值,其中保持在内存中的mapper输出内存合并将被启动。
- mapreduce.reduce.merge.inmem.threshold – 这是内存中合并进程启动后,累积在内存中的mapper 输出数量方面的阈值。注意,要启动内存中合并进程,需要达到由mapreduce.reduce.merge.inmem.threshold或mapreduce.reduce.shuffle.merge.percent定义的阈值中的一个。
5.9 小结
本章使用样例驱动的方式探讨了MapReduce的所有主要部件。我们采取了熟悉的SQL范式并开发了常见的数据处理功能,如SELECT ,WHERE和GROUP BY聚合。你们也学到了MapReduce开发的基础知识,因为它适用于现实中的情况以及大规模的数据集。最后,我们讨论了MapReduce进程的内部原理。通过讨论深入研究了在MapReduce程序的执行中这些文件是如何在不同的节点和组件间移动的。
Leave a Reply