SHOUG成员 – ORACLE ACS高级顾问罗敏
尝鲜Oracle 12c
就在本书写作期间的2013年秋天,Oracle公司终于正式推出了令广大IT人士翘首以盼的12c数据库,c就是云(Cloud),意味着Oracle将12c定位为数据库云平台整体解决方案。
12c到底有哪些新特性和新技术?特别是在云计算方面有什么特色技术?在12c尚未正式推出的2013年春天,本人参加了一次公司内部的12c技术培训,发现12c林林总总的新特性真不少,但培训教材的前几章则在全面介绍两大技术领域:CDB/PDB架构和信息生命周期管理,可见这两大技术领域在数据库云平台和云计算方面的重要性。于是,本章也只涉足这两大技术领域,以及相关的实施案例。
新特性培训课的趣事
本人从2001年加入Oracle公司算起到2013年的12年间,Oracle数据库版本从9i一直发展到了12c,个人知识和能力也是伴随着Oracle技术的不断发展而共同进步。以下就是Oracle公司描述的最新几个版本的技术创新示意图:
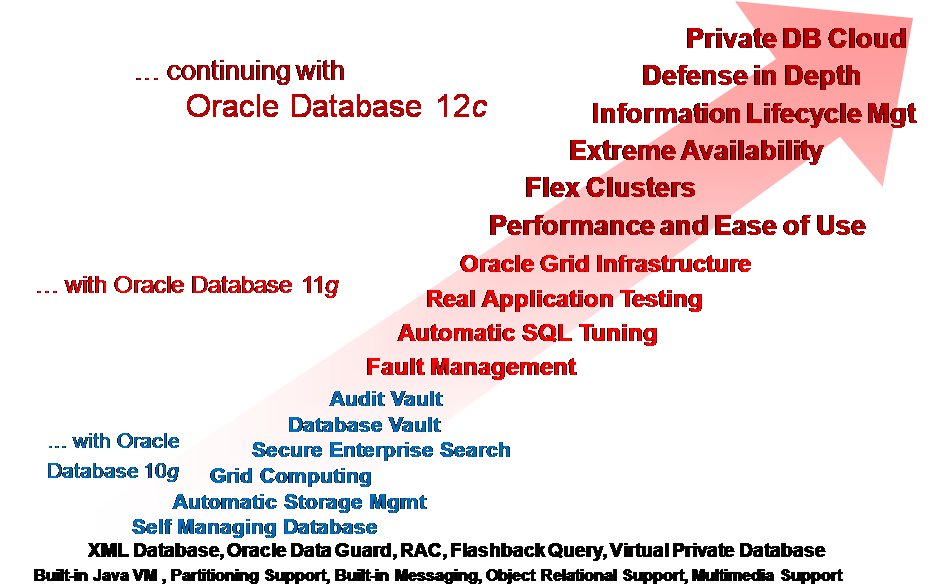
在这12年间,本人也有幸参加了各个版本的新特性培训。记得在2001年参加9i新特性培训时,还是在国贸二座的Oracle大学一间大教室,公司内外听课者有数十人之众。而在2004年参加10g新特性培训时,人数就只有10余人了。再到2007年在上海Oracle大学参加11g新特性培训时,则只有区区3个人,其中包括本人在内的2位是Oracle内部员工,真正的客户就1位。而在2013年参加12c新特性培训时,也只有可怜的4个人,而且可能是因为12c尚未正式发布的缘故,4个人全部都是Oracle公司内部员工。
记得2007年在参加11g培训时,当老师按照教材一上来就介绍有关ASM新特性时,那位唯一的客户一听就傻眼了:“老师,什么叫ASM啊?”。原来他们的系统还运行在9i平台,尚未接触过10g,更未听说过什么ASM,呵呵。感慨:以后听这种新特性的课程,一定不能跨版本。IT技术发展太快了。
在本次连续5天的12c培训过程中,因工作等各种原因,包括本人在内的4位听课者或多或少缺席了一些课程。到培训的最后一天,其他同学因故都缺席了,老师就只对我一个人滔滔不绝了,但老师依然是非常职业地抑扬顿挫,搞得我都不好意思了:“老师,就我一个人了,您不用那么大声音了。”呵呵。但我一直坚持到最后做完课程的所有练习。
IT技术的确发展太快,搞得客户都有点跟不上这种高速发展的步伐了。但作为原厂技术服务人员,紧跟IT技术发展潮流,并及时抢占技术制高点其实是我们的基本职业诉求。
虽然说总体感觉12c相比以前版本而言,并未发生很多革命性的根本变化。例如像10g一样,新增加ASM、clusterware等架构性技术。但5天的培训课程,感觉12c还是推出了大量新特性。限于篇幅,也根据自身理解,将只介绍几个12c最重要的新特性,包括在架构方面的新变化和新技术:Container DB和Pluggable DB,以及在信息生命周期方面的新技术。
12c架构方面最大变化
Oracle传统架构
Oracle数据库主版本从8i开始均带有一个字母:8i、9i、10g、11g、12c。根据Oracle公司官方解释:i代表Internet、Intellegence等,g则代表Grid Computing(网格计算),而c则是Cloud Computing(云计算)了。
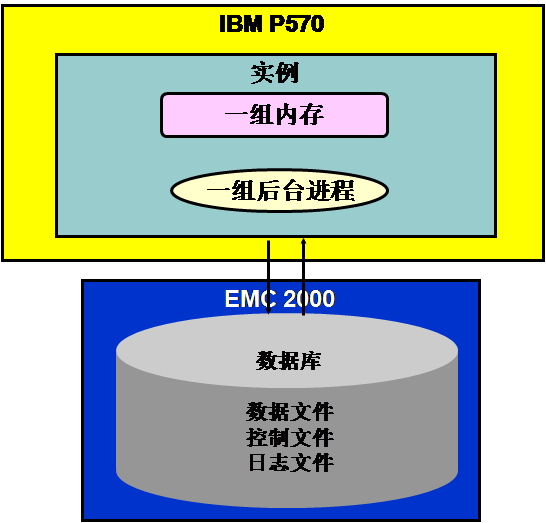
Oracle宣称12c版本为云计算平台,并非赶时髦,而的确是在架构层面大动干戈了!传统的Oracle架构中实例和数据库关系只有1对1关系和N对1关系。下图就是实例和数据库1对1关系的单机架构:
同时,Oracle还支持多个实例共享一个数据库的N对1关系,即如下图所示的RAC集群架构:

在12c之前的传统Oracle架构中,是不支持一个实例管理多套数据库的1对N关系的架构,即如下图所示:
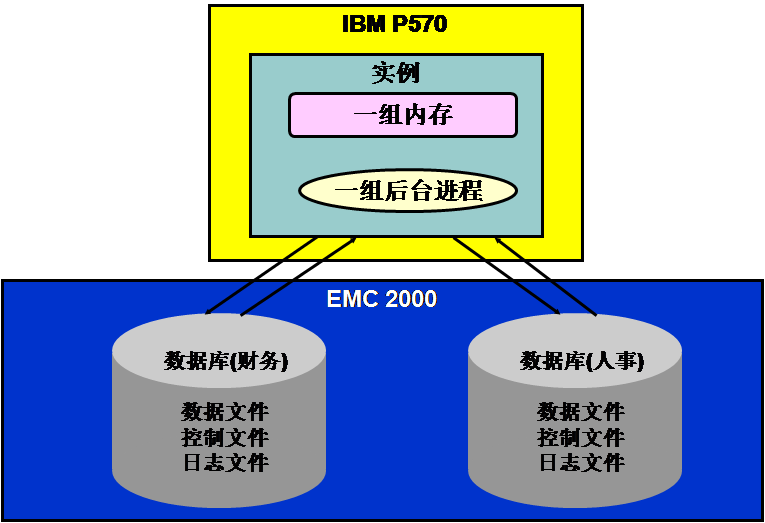
但是为适应云计算发展的需要,Oracle在12c中也支持这种架构了,也就是后面要详细描述的Container DB和Pluggable DB概念了。这就是本人觉得12c在架构方面最大的改变和新特性了。
Container DB和Pluggable DB基本概念
以下就是Container DB和Pluggable DB概念示意图:
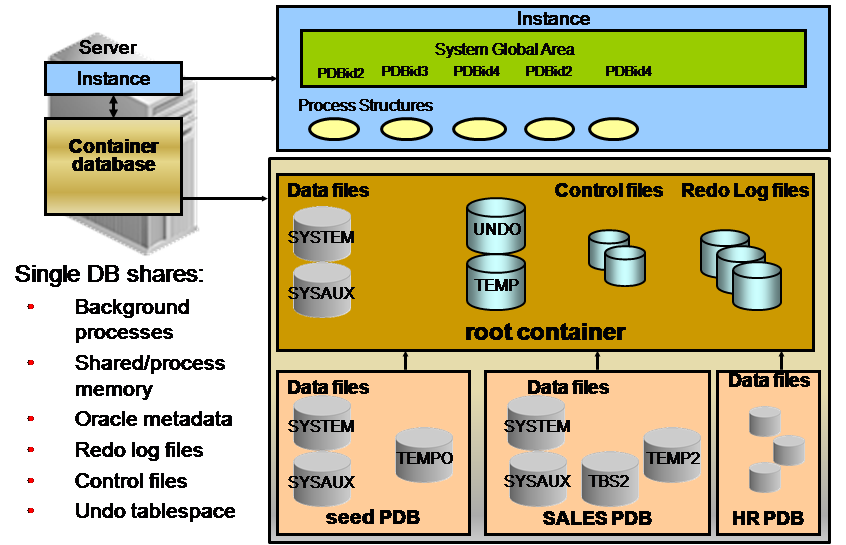
首先,在这种架构下只有一个数据库实例,即所有数据库共享一组后台进程和一组内存,包括SGA、PGA等。
其次,该实例可以管理多个数据库,即多个Container数据库。上图表示一个名为root 的Container数据库,简称CDB。而且包括3个类型为Pluggable的Container数据库,简称PDB。其中一个为Seed PDB(种子PDB),另外两个为SALES PDB和HR PDB应用数据库,也就是说CBD和所有PDB是父子关系,并且CBD和PDB数据库在一个实例下运行和管理。
再者,在CDB层面像传统数据库结构一样,包括SYSTEM、SYSAUX、UNDO、TEMP等系统表空间和应用表空间,以及控制文件和日志文件等。但在PDB层面则只有专属PDB的SYSTEM、SYSAUX系统表空间和应用表空间,而没有UNDO表空间、控制文件和日志文件。也就是说CDB的UNDO表空间、控制文件和日志文件是整个CDB所共享的。
CBD的临时表空间和临时表空间组可以为各PDB所共享,但是每个PDB也可拥有自己独立的临时表空间和临时表空间组。
最后,CDB的归档模式决定了所有PDB的归档模式。即所有CDB和PDB同为归档或非归档模式。
Container DB和Pluggable DB架构的好处
Oracle公司为什么在12c中推出这种实例和数据库为1对N关系的CDB和PDB架构?这就是为了满足云计算,特别是数据库整合的需要而应运而生的。我们还是先从现有IT 系统架构现状分析开始:
首先,出于业务、管理、安全等多方因素考虑,以及技术架构本身限制等,大多数企业存在大量部门级的小系统,这些典型的竖井式、孤岛式系统其实在平时资源利用率非常低。本人曾在国内某大型银行参与其全国大集中项目,发现大部分小系统都处于这种状态,如下图所示:
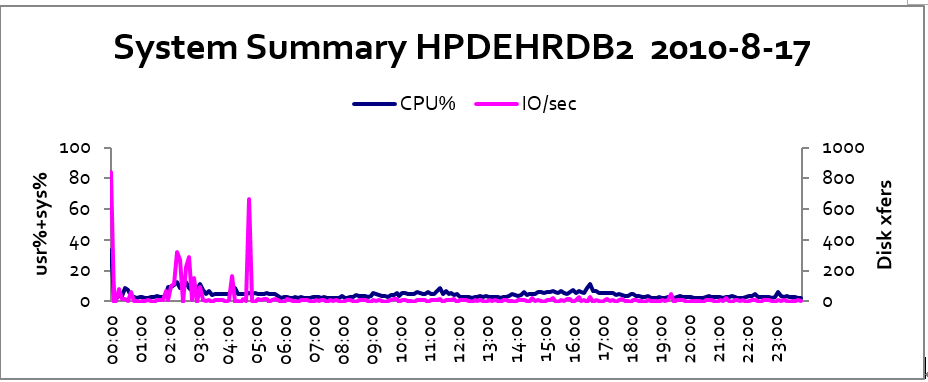
可见,除了晚上几个后台作业对资源有一定开销之外,大部分时间的资源利用率非常之低。
其次,这些系统其实应用并不复杂,但同样需要DBA去进行运行监控、性能分析、版本和补丁管理、备份恢复等各种管理工作。
再者,在Oracle现有技术架构层面,由于每个应用系统都需要自己的实例和数据库,尽管可以将多套系统部署在同一个物理服务器,但同样将导致过多的Oracle后台进程和内存的开销,以及数据字典数据的重复。
最后,就像上章所言,虽然基于11g的云计算可以在Schema级进行数据库的整合,但毕竟带来数据隔离性下降等客户顾虑的安全性问题。
如何能有效解决这一问题,特别是用更少的资源去管理更多的数据库,充分发挥硬件资源利用率、降低管理成本,同时又保障一定的数据隔离性呢?这就是Oracle 12c推出CDB和PDB的重要意图。具体而言,这种新型架构的好处如下:
- 有效提高资源利用率
首先,在这种架构下,更多应用数据库被整合到一个硬件环境,资源利用率得到有效提高。同时12c在CDB和PDB的不同层面可以进行资源管理的设计,这样也将有效解决不同数据库系统高峰期间的资源竞争问题。
- 有效降低资源开销
其次,由于一个数据库实例管理多套数据库,这样只有一套后台进程和内存开销,数据字典的冗余信息也降低,有效降低了整体资源开销。
- 管理成本下降
由于只要管理一个数据库实例,系统的日常监控、性能分析、版本和补丁管理、备份恢复等各种管理工作都简化,而且这种架构下通过克隆、复制等多种方式,PDB可快速、简洁地进行部署,同时对应用透明。因此,总体管理成本将下降。
- 有效的安全控制
在这种架构下,既可在CDB层面进行集中统一的安全控制管理,由于各个应用系统还是相对独立的PDB,又可在PDB层面进行安全控制管理,确保了一定的数据隔离性和职责分离性。
- 支持Oracle其它技术和架构
CDB/PDB架构支持RAC架构。在 RAC架构中,CDB作为一个整体而部署。这种架构也支持Data Guard架构,但也只能在CDB而不能在PDB级别进行部署和管理。
OEM也支持CDB和PDB的管理。在 OEM中,管理员既可直接通过身份认证连接到CDB进行整个CDB管理,也可连接到指定PDB,只对该PDB进行管理。
资源管理器也增强了对CDB和PDB的资源管理。例如,可根据各PDB的不同资源需求,在一个CDB内部的各PDB之间进行合理的资源分配。
CDB和PDB的创建、启动和关闭
管理CDB和PDB的方式
Oracle 12c中提供了管理CDB和PDB的多种访问方式和工具,如下所示:
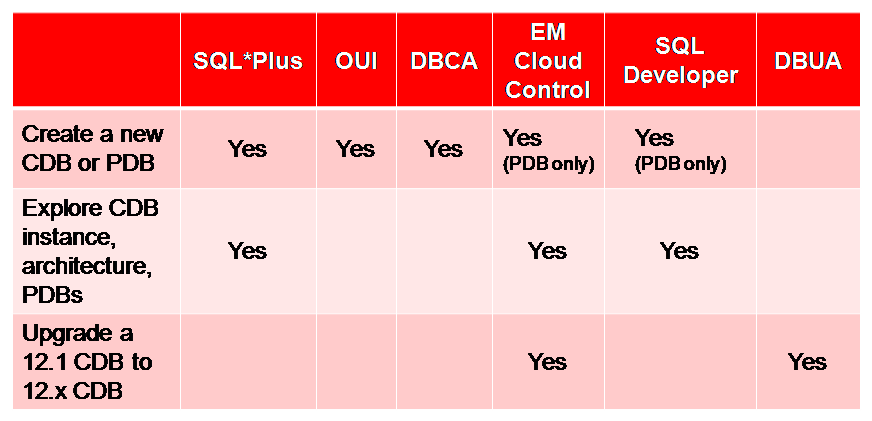
可见,创建 CDB和PBD就可以通过SQL*PLUS命令行,DBCA、EM、SQL Devloper等图形化工具等进行。本书限于篇幅,将主要介绍SQL*PLUS命令行进行 CDB、PDB创建和日常管理的基本操作。
创建CDB
创建CDB,主要分为如下四个步骤:
- 配置ora初始化文件
与创建正常数据库一样,首先需要配置init.ora初始化文件,包括设置ORACLE_SID、CONTROL_FILES、DB_NAME等参数。但欲创建CDB数据库,需要设置新的初始化参数ENABLE_PLUGGABLE_DATABASE = TRUE。
- 启动数据库实例
SQL> CONNECT / AS SYSDBA
SQL> STARTUP NOMOUNT
- 创建CDB数据库
SQL> CREATE DATABASE cdb1
2 USER SYS IDENTIFIED BY p1 USER SYSTEM IDENTIFIED BY p2
3 LOGFILE GROUP 1 ('/u01/app/oradata/CDB1/redo1a.log',
4 '/u02/app/oradata/CDB1/redo1b.log') SIZE 100M,
5 GROUP 2 ('/u01/app/oradata/CDB1/redo2a.log',
6 '/u02/app/oradata/CDB1/redo2b.log') SIZE 100M
7 CHARACTER SET AL32UTF8 NATIONAL CHARACTER SET AL16UTF16
8 EXTENT MANAGEMENT LOCAL DATAFILE
9 '/u01/app/oradata/CDB1/system01.dbf' SIZE 325M
10 SYSAUX DATAFILE '/u01/app/oradata/CDB1/sysaux01.dbf' SIZE 325M
11 DEFAULT TEMPORARY TABLESPACE tempts1
12 TEMPFILE '/u01/app/oradata/CDB1/temp01.dbf' SIZE 20M
13 UNDO TABLESPACE undotbs
14 DATAFILE '/u01/app/oradata/CDB1/undotbs01.dbf' SIZE 200M
15 ENABLE PLUGGABLE DATABASE
16 SEED FILE_NAME_CONVERT =
17 ('/u01/app/oradata/CDB1',
18 '/u01/app/oradata/CDB1/seed');
可见,与创建正常数据库语句类似,该语句在创建数据库过程中创建了一个SYS用户,并创建了两组、每组两个成员的联机日志文件,并且指定了数据库字符集为AL32UTF8,以及国家字符集为AL16UTF16,同时还创建了SYSTEM、SYSAUX、TEMPTS1、UNDO等系统级表空间。
但与传统创建数据库语句不同的是,ENABLE PLUGGABLE DATABASE短语表示创建的是CDB数据库。另外,SEED FILE_NAME_CONVERT = (‘/u01/app/oradata/CDB1’, ‘/u01/app/oradata/CDB1/seed’)表示该语句还将创建一个SEED PDB,而SEED PDB的数据文件将通过复制root CDB的文件而产生。
当然,上述语句执行前必须先创建好’/u01/app/oradata/CDB1’和 ‘/u01/app/oradata/CDB1/seed’目录,并确保有足够的存储空间。
- 创建CDB数据库之后的操作
创建CDB数据库之后,主要需要创建相关数据字典:
SQL> CONNECT / AS SYSDBA SQL> alter session set "_oracle_script"=true; SQL> alter pluggable database pdb$seed close; SQL> alter pluggable database pdb$seed open; SQL> @?/rdbms/admin/catalog.sql; SQL> @?/rdbms/admin/catblock.sql; SQL> @?/rdbms/admin/catproc.sql; SQL> @?/rdbms/admin/catoctk.sql; SQL> @?/rdbms/admin/owminst.plb; SQL> @?/sqlplus/admin/pupbld.sql;
- 创建CDB数据库之后的结果
在创建CDB数据库之后,Oracle将创建root Container和Seed PDB两个数据库,并分别创建CDB和PDB两个Service。两个数据库也将分别创建SYS和 SYSTEM两个公用用户,并授予一些公用的访问权限和预定义角色,同时分别创建SYSTEM和SYSAUX表空间。
在设置环境变量ORACLE_SID=CDB之后,管理员通过“connect / as sysdba”将连接到CDB数据库,而欲连接到指定PDB,则通过“CONNECT username/password@pdb_net_service_name”进行连接。
创建PDB
Oracle 12c可以通过如下四种方式创建PDB,以下主要通过SQL*PLUS命令行方式,分别介绍这四种方式:
- 第一种:通过seed PDB进行复制
该方式非常简洁,具体操作先以SYS用户登录到CDB,然后执行通过seed PDB进行复制的命令:
SQL> CONNECT / AS SYSDBA;
SQL> CREATE PLUGGABLE DATABASE pdb1
2 ADMIN USER admin1 IDENTIFIED BY p1 ROLES=(CONNECT)
3 FILE_NAME_CONVERT = ('PDB$SEEDdir', 'PDB1dir');
上述命令将seed PDB数据库文件目录复制为pdb1的数据文件。
通过如下命令,可验证pdb1数据库是否成功创建:
SQL> CONNECT / AS SYSDBA SQL> SELECT * FROM cdb_pdbs; SQL> SELECT * FROM cdb_tablespaces; SQL> SELECT * FROM cdb_data_files; SQL> ALTER PLUGGABLE DATABASE pdb1 OPEN; SQL> CONNECT sys@pdb1 AS SYSDBA SQL> CONNECT admin1@pdb1
- 第二种:将一个传统非CDB数据库以PDB形式装载(Plug)到一个CDB
Oracle提供了三种方式,可将一个传统非CDB数据库以PDB形式装载(Plug)到一个CDB。第一种是通过表空间传输技术(TTS)、传输数据库技术(TDB)或者全库Export/Import技术。第二种是通过DBMS_PDB包,产生一个描述非CDB数据库的XML文件,再装载到CDB中。第三种则是通过 GoldenGate数据复制技术。
本书仅介绍第二种DBMS_PDB包方式,也是最简单的一种方式,但该方式必须假设非 CDB数据库为12.1版本以上。
- 连接到非 CDB数据库ORCL,并且将该数据库设置为READ ONLY状态。
- 执行如下脚本:
SQL> EXEC DBMS_PDB.DESCRIBE (‘/tmp/ORCL.xml’);
- 以SYS用户连接到目标CDB,并将ORCL装载到CBD中:
SQL> conn / as sysdba;
SQL> CREATE PLUGGABLE DATABASE PDB2 USING ‘/tmp/ORC.xml’;
- 执行如下脚本:
SQL> CONNECT sys@PDB2 AS SYSDBA;
SQL>@$ORACLE_HOME/rdbms/admin/noncdb_to_pdb
该脚本删除一些PDB SYSTEM表空间中一些不必要的信息。在第一次打开PDB2之前,必须运行该脚本。
- 打开并验证 PDB2
SQL> CONNECT / AS SYSDBA SQL> SELECT * FROM cdb_pdbs; SQL> SELECT * FROM cdb_tablespaces; SQL> SELECT * FROM cdb_data_files; SQL> ALTER PLUGGABLE DATABASE pdb2 OPEN; SQL> CONNECT sys@pdb2 AS SYSDBA
- 第三种:在一个CBD中,通过克隆(clone)现有一个PDB,创建一个新PDB
- 假设不使用OMF技术,设置初始化参数PDB_FILE_NAME_CONVERT= ‘PDB1dir’, ‘PDB3dir’
- 以SYS用户连接到CDB,并将 PDB1设置为READ ONLY状态:
SQL> conn / as sysdba; SQL> ALTER PLUGGABLE DATABASE pdb1 CLOSE; SQL> ALTER PLUGGABLE DATABASE pdb1 OPEN READ ONLY;
- 通过克隆(clone)PDB1,创建PDB3:
SQL> CREATE PLUGGABLE DATABASE pdb3 FROM pdb1 FILE_NAME_CONVERT=(’pdb1dir’,’ pdb3dir’);
- 打开并验证 PDB3
SQL> CONNECT / AS SYSDBA SQL> SELECT * FROM cdb_pdbs; SQL> SELECT * FROM cdb_tablespaces; SQL> SELECT * FROM cdb_data_files; SQL> ALTER PLUGGABLE DATABASE pdb3 OPEN; SQL> CONNECT sys@pdb3 AS SYSDBA
- 第四种:从一个CDB先卸载(Unplug)一个 PDB,再装载(Plug)到另一个CDB
该方式的示意图如下:
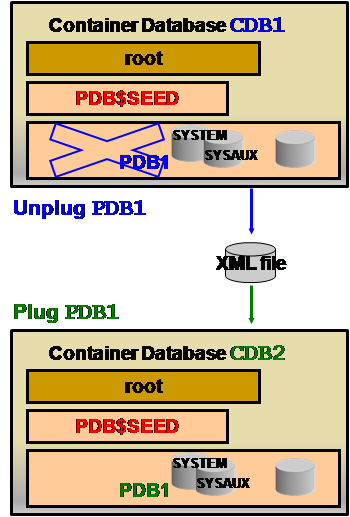
具体步骤如下:
- 以SYS用户连接到CDB1,并将 PDB1设置为READ ONLY状态:
SQL> conn / as sysdba;
SQL> ALTER PLUGGABLE DATABASE pdb1 CLOSE;
SQL> ALTER PLUGGABLE DATABASE pdb1 OPEN READ ONLY;
- 将PDB1卸载(unplug)为一个XML文件:
- 将PDB1卸载(unplug)为一个XML文件:
SQL> ALTER PLUGGABLE DATABASE pdb1 UNPLUG INTO ‘xmlfile1.xml’;
- 以SYS用户连接到CDB2,并检查PDB1与CDB2是否兼容:
SQL> conn / as sysdba;
SET SERVEROUTPUT ON DECLARE compat BOOLEAN;
BEGIN compat := DBMS_PDB.CHECK_PLUG_COMPATIBILITY( pdb_descr_file
=> '/disk1/usr/salespdb.xml', pdb_name => 'pdb1'); DBMS_OUTPUT.PUT_LINE('Is PDB compatible? = ' || compat);
END;
- 如果兼容,则通过如下命令将PDB1加载到CBD2:
SQL> CREATE PLUGGABLE DATABASE pdb1 USING ‘xmlfile1.xml’ NOCOPY;
- 在CDB2中打开并验证 PDB1
SQL> CONNECT / AS SYSDBA SQL> SELECT * FROM cdb_pdbs; SQL> SELECT * FROM cdb_tablespaces; SQL> SELECT * FROM cdb_data_files; SQL> ALTER PLUGGABLE DATABASE pdb1 OPEN; SQL> CONNECT sys@pdb1 AS SYSDBA
删除PDB
通过如下命令可删除指定的PDB:
SQL> CONNECT / AS SYSDBA SQL> ALTER PLUGGABLE DATABASE pdb1 CLOSE; SQL> DROP PLUGGABLE DATABASE pdb1 [INCLUDING DATAFILES];
该命令执行后, Oracle将自动将pdb1被删除信息记录在 CDB的控制文件之中。当指定INCLUDING DATAFILES选项时,pdb1数据库的所有数据文件将被删除掉。当未指定INCLUDING DATAFILES选项时,pdb1数据库的所有数据文件将保留,这种情况适合于从一个CDB先卸载(Unplug)一个 PDB,再装载(Plug)到另一个CDB的需要。
如何将12c版本之前的数据库迁移到12c CDB?
总体而言,可通过如下两种方式,实现将12c版本之前的数据库迁移到12c CDB:
- 第一种:升级 + Plug
该方式示意图如下:
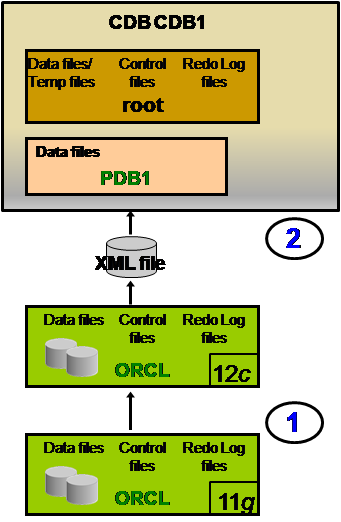
即首先将12c版本之前的数据库升级到12c,成为12c的非CBD数据库。其次,通过DBMS_PDB包,以XML方式,将非 CDB数据库加载(Plug)到CBD中。
- 第二种:创建PDB + 导入数据
该方式示意图如下:
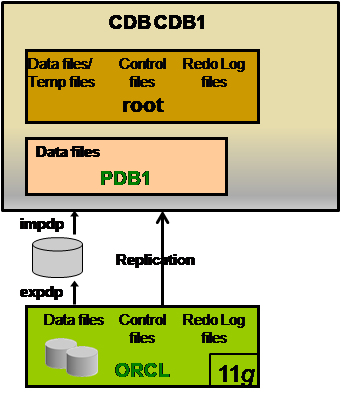
即首先在CDB1中创建一个PDB1,然后通过Data Pump技术进行数据导出/导入,或者通过GoldenGate数据复制技术实现数据迁移。
CDB和PDB数据库的启动和关闭
- 启动CDB实例和打开CDB数据库
以下是CDB和PDB数据库的启动各阶段示意图:
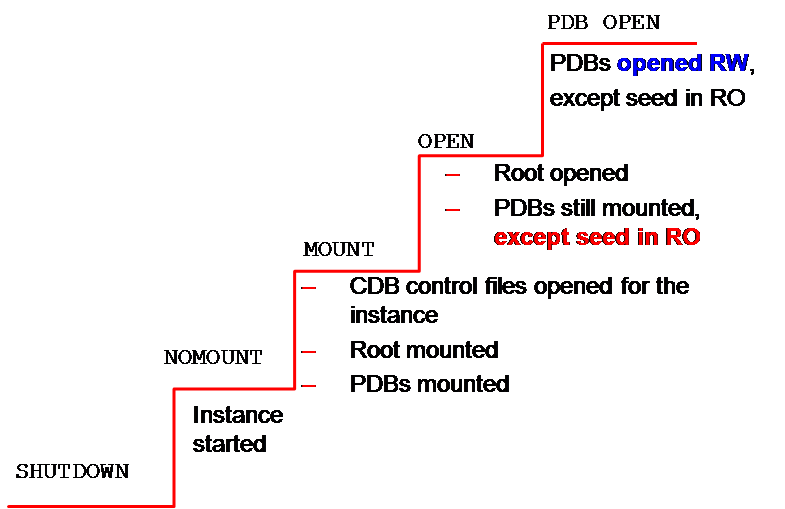
可见,CDB和PDB数据库的启动与传统数据库既有相似之处,也有一定的差异,下面详细介绍之。
通过如下命令,CDB数据库可启动为nomount状态:
SQL> CONNECT sys@CDB1 AS SYSDBA
SQL> STARTUP NOMOUNT;
此时,CDB数据库实例被启动。
通过如下命令,CDB数据库可启动为mount状态:
SQL> CONNECT sys@CDB1 AS SYSDBA
SQL> STARTUP MOUNT;
Or
SQL> CONNECT sys@CDB1 AS SYSDBA
SQL> STARTUP NOMOUNT;
SQL> ALTER DATABASE CDB1 MOUNT;
此时,不仅CDB数据库实例被启动,而且控制文件被打开,Root CDB和所有PDB处于Mount状态。
通过如下命令,CDB数据库可处于open状态:
SQL> CONNECT sys@CDB1 AS SYSDBA
SQL> STARTUP;
Or
SQL> CONNECT sys@CDB1 AS SYSDBA
SQL> STARTUP NOMOUNT;
SQL> ALTER DATABASE CDB1 MOUNT;
SQL> ALTER DATABASE CDB1 OPEN;
Or
SQL> CONNECT sys@CDB1 AS SYSDBA
SQL> STARTUP MOUNT;
SQL> ALTER DATABASE CDB1 OPEN;
此时,不仅CDB数据库实例被启动,而且控制文件、日志文件、数据文件被打开,Root CDB将处于Open状态。但Seed PDB将处于READ ONLY状态,而其它PDB将处于Mount状态。通过如下命令可确认之:
SQL> SELECT name,open_mode FROM v$pdbs; NAME OPEN_MODE ---------------- ------------- PDB$SEED READ ONLY PDB1 MOUNTED PDB2 MOUNTED
- 打开PDB数据库
通过如下命令,可手工打开指定或全部PDB数据库:
SQL> CONNECT sys@CDB1 AS SYSDBA
SQL> ALTER PLUGGABLE DATABASE pdb1 OPEN;
Or
SQL> ALTER PLUGGABLE DATABASE ALL OPEN;
如何实现打开CDB的同时,就自动打开所有或部分PDB?如下触发器将在打开CDB的同时就打开所有PDB:
SQL> CREATE TRIGGER Open_All_PDBs after startup on database begin execute immediate 'alter pluggable database all open'; end Open_All_PDBs; /
- 关闭PDB数据库
以下是PDB数据库的启动各阶段示意图:

通过如下命令,可根据不同需要关闭PDB数据库:
SQL> CONNECT / AS SYSDBA
SQL> ALTER PLUGGABLE DATABASE pdb1 CLOSE IMMEDIATE;
SQL> ALTER PLUGGABLE DATABASE ALL EXCEPT pdb1 CLOSE;
SQL> ALTER PLUGGABLE DATABASE ALL CLOSE;
其中第2条命令关闭pdb1数据库;第3条命令关闭除pdb1之外的所有PDB数据库;第4条命令关闭所有PDB数据库。
也可通过如下命令,连接到指定PDB,并进行关闭该PDB数据库的操作:
SQL> CONNECT sys@pdb1 AS SYSDBA SQL> ALTER PLUGGABLE DATABASE CLOSE; Or SQL> SHUTDOWN IMMEDIATE;
与传统数据库关闭不同的是,PDB数据库关闭只是将PDB的数据文件关闭了,但CDB的整个实例还没有关闭。因此PDB数据库关闭之后,将显示下述正常的错误信息:
SQL> SHUTDOWN IMMEDIATE;
ORA-65020: Pluggable database already closed
- 关闭CDB数据库
通过如下命令,可关闭整个CDB数据库和CBD实例:
SQL> CONNECT sys@CDB1 AS SYSDBA
SQL> SHUTDOWN IMMEDIATE
此时,所有PDB将被关闭,接下来CDB被关闭,最后整个CDB实例将被关闭。
CDB和PDB的日常管理
CDB和PDB中表空间的管理
与传统数据库一样,表空间的合理设计将有效提高数据的可管理性、可操作性和安全性。CDB和PDB概念的引入,使得表空间管理更有层次性,更能满足云计算环境下数据整合的需要。
以下就是在root CDB下创建表空间的范例:
SQL> CONNECT system@cdb1 SQL> CREATE TABLESPACE tbs_CDB_users DATAFILE 2 '/u1/app/oracle/oradata/cdb/cdb_users01.dbf' 3 SIZE 100M;
以下就是在PDB下创建表空间的范例:
SQL> CONNECT system@cdb1 SQL> CREATE TABLESPACE tbs_CDB_users DATAFILE 2 '/u1/app/oracle/oradata/cdb/cdb_users01.dbf' 3 SIZE 100M;
以下就是在PDB下创建表空间的范例:
SQL> CONNECT system@PDB1 SQL> CREATE TABLESPACE tbs_PDB1_users DATAFILE 2 '/u1/app/oracle/oradata/cdb/pdb1/users01.dbf' 3 SIZE 100M;
以下就是在root CDB下分配缺省表空间的范例:
SQL> CONNECT system@cdb1 SQL> ALTER DATABASE DEFAULT TABLESPACE tbs_CDB_users;
以下就是在PDB下分配缺省表空间的范例:
SQL> CONNECT pdb1_admin@pdbhr SQL> ALTER PLUGGABLE DATABASE DEFAULT TABLESPACE pdbhr_users;
以下就是在root CDB下分配缺省临时表空间的范例:
SQL> CONNECT system@cdb1 SQL> ALTER DATABASE DEFAULT TEMPORARY TABLESPACE temp_root;
以下就是在PDB下分配缺省临时表空间的范例:
SQL> CONNECT pdb1_admin@pdbhr SQL> ALTER PLUGGABLE DATABASE DEFAULT TEMPORARY TABLESPACE local_temp; Or SQL> ALTER DATABASE DEFAULT TEMPORARY TABLESPACE local_temp;
可见,CDB和PDB中表空间管理语句与传统语句其实一样,区别在于连接到CDB和PDB不同数据库而已,或者在 PDB级增加PLUGGABLE短语。
CDB和PDB的数据库备份
再次重复Oracle公司的一句名言:无论如何强调数据库的备份都不过分。在通过CDB和PDB架构下实现数据库整合之后,数据库的备份和恢复更加重要。为满足数据库整合备份恢复的更复杂需求,Oracle 12c提供了在CDB、PDB不同层面进行更灵活的备份和恢复技术。
以下就是对所有CDB和PDB进行备份的语句:
$ export ORACLE_SID=cdb1 $ rman TARGET / RMAN> BACKUP DATABASE;
以下就是对指定PDB进行备份的语句:
RMAN> BACKUP PLUGGABLE DATABASE hr_pdb, sales_pdb; RMAN> RECOVER PLUGGABLE DATABASE hr_pdb;
以下就是对指定PDB的表空间进行备份的语句:
RMAN> BACKUP TABLESPACE sales_pdb:tbs2;
CDB和PDB的数据库恢复
CDB和PDB的数据库恢复与传统数据库恢复既有相同之处,也有其特殊之处。以下介绍主要事故场景的恢复过程。
- 实例故障
与传统数据库恢复一样,当实例发生故障时,Oracle将在实例重启时,自动进行数据库的恢复,包括利用redo log日志进行向前恢复和利用UNDO信息进行向后恢复。
但不同之处在于,只有CDB可以进行实例恢复,而PDB是共享CDB实例的,因此PDB没有实例恢复一说。
- 临时表空间数据文件故障
无论是CDB或PDB的临时表空间数据文件出现故障,当SQL应用需要使用到临时表空间时,将出现相关错误。例如:
SQL> CONNECT / AS SYSDBA SQL> select * from DBA_OBJECTS order by 1,2,3,4,5,6,7,8,9,10,11,12,13; select * from DBA_OBJECTS order by 1,2,3,4,5,6,7,8,9,10,11,12,13 * ERROR at line 1: ORA-01565: error in identifying file '/u01/app/oracle/oradata/CDB1/temp01.dbf' ORA-27037: unable to obtain file status Linux Error: 2: No such file or directory
当启动CDB实例和打开CDB数据库时,Oracle都将自动创建这些出现故障的临时表空间数据文件。如果自动创建失败,则可以通过手工方式创建。例如:
SQL> ALTER TABLESPACE temp ADD TEMPFILE 2 '/u01/app/oracle/oradata/CDB1/temp02.dbf' SIZE 20M; SQL> ALTER TABLESPACE temp DROP TEMPFILE 3 '/u01/app/oracle/oradata/CDB1/temp01.dbf’;
- 控制文件故障
如果控制文件损坏,由于控制文件属于CDB,因此整个CDB将出现宕机。恢复控制文件的最快捷方式应该是重新创建之。为此,建议当CDB出现大规模结构型变化时,通过如下命令进行控制文件的导出:
SQL> ALTER DATABASE BACKUP CONTROLFILE TO TRACE;
当出现控制文件故障时,并通过相关trace文件重新创建控制文件。
否则,需要如下命令进行整个数据库的恢复,将非常消耗时间和资源。
RMAN> CONNECT TARGET / RMAN> STARTUP NOMOUNT; RMAN> RESTORE CONTROLFILE FROM AUTOBACKUP; RMAN> ALTER DATABASE MOUNT; RMAN> RECOVER DATABASE; RMAN> ALTER DATABASE OPEN RESETLOGS; RMAN> ALTER PLUGGABLE DATABASE ALL OPEN;
- CDB的SYSTEM或UNDO表空间文件故障
与传统数据库恢复一样,当CDB的SYSTEM或UNDO表空间文件出现故障,整个CDB将在Mount状态下进行恢复,也意味着整个CDB和PDB将处于不可用状态。以下是UNDO表空间恢复过程:
RMAN> STARTUP MOUNT; RMAN> RESTORE TABLESPACE undo1; RMAN> RECOVER TABLESPACE undo1; RMAN> ALTER DATABASE OPEN; RMAN> ALTER PLUGGABLE DATABASE ALL OPEN;
- CDB的SYSAUX表空间文件故障
与传统数据库恢复一样,当CDB的SYSAUX表空间文件出现故障,只需将该表空间设置为OFFLINE状态,并进行恢复,而整个CDB和PDB将处于可用状态。以下是SYSAUX表空间恢复过程:
RMAN> ALTER TABLESPACE sysaux OFFLINE IMMEDIATE; RMAN> RESTORE TABLESPACE sysaux; RMAN> RECOVER TABLESPACE sysaux; RMAN> ALTER TABLESPACE sysaux ONLINE;
- PDB的SYSTEM表空间文件故障
当PDB的SYSTEM表空间文件出现故障,整个CDB将关闭并需要进行相关数据文件的恢复操作,在此期间,整个CDB和所有PDB将不可访问。以下就是指定PDB的SYSTEM表空间恢复过程:
RMAN> CONNECT TARGET / RMAN> STARTUP MOUNT; RMAN> RESTORE PLUGGABLE DATABASE sales_pdb; RMAN> RECOVER PLUGGABLE DATABASE sales_pdb; RMAN> ALTER DATABASE OPEN; RMAN> ALTER PLUGGABLE DATABASE ALL OPEN;
或者:
RMAN> CONNECT TARGET / RMAN> STARTUP MOUNT; RMAN> RESTORE TABLESPACE sales_pdb:system; RMAN> RECOVER TABLESPACE sales_pdb:system; RMAN> ALTER DATABASE OPEN; RMAN> ALTER PLUGGABLE DATABASE ALL OPEN;
- PDB的普通表空间文件故障
当PDB的普通表空间文件出现故障,只需对相关数据文件进行恢复操作。在此期间,除了该表空间之外,整个CDB和所有PDB都可访问。以下就是PDB的普通表空间恢复过程:
RMAN> CONNECT system@sales_pdb RMAN> ALTER TABLESPACE tbs2 OFFLINE IMMEDIATE; RMAN> CONNECT TARGET / RMAN> RESTORE TABLESPACE sales_pdb:tbs2; RMAN> RECOVER TABLESPACE sales_pdb:tbs2; RMAN> ALTER TABLESPACE tbs2 ONLINE;
CDB数据库的Flashback Database
Oracle 12c只能在CDB级进行Flashback Database操作。与传统数据库Flashback Database设置一样,CDB的Flashback Database配置过程如下:
/*+ 配置flash recovery area */ SQL> ALTER SYSTEM SET DB_RECOVERY_FILE_DEST_SIZE = 4G; SQL> ALTER SYSTEM SET DB_RECOVERY_FILE_DEST = '/oracle/frec_area'; /*+ 配置retention target参数 */ SQL> ALTER SYSTEM SET DB_FLASHBACK_RETENTION_TARGET=2880; /*+ 启动Flashback Database */ SQL> ALTER DATABASE FLASHBACK ON;
Oracle 12c可在CDB mount状态通过Flashback Database命令,将整个CDB和PDB快速闪回到指定SCN、过去某个时间点或日志序列号。例如:
SQL> SHUTDOWN IMMEDIATE SQL> STARTUP MOUNT SQL> FLASHBACK DATABASE TO SCN 10; SQL> ALTER DATABASE OPEN RESETLOGS; SQL> ALTER PLUGGABLE DATABASE ALL OPEN;
在数据库进行闪回期间,可通过如下命令将CDB和PDB以read only方式打开,并监控数据库闪回情况:
SQL> ALTER DATABASE OPEN READ ONLY; SQL> ALTER PLUGGABLE DATABASE ALL OPEN READ ONLY;
信息生命周期管理的挑战和12c解决方案
信息生命周期管理的挑战
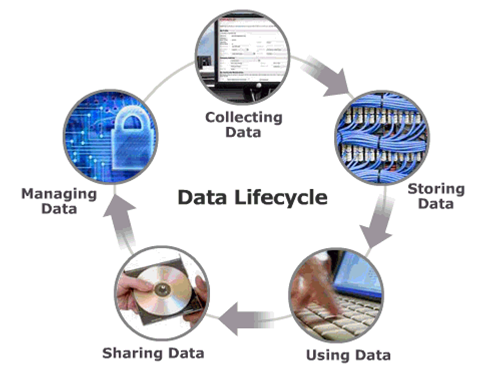
数据量的日益增长已成为IT系统发展的一个显著特征。如下图所示,数据从采集、存储到数据库中,到广泛、深入地被访问和共享,以及有效的管理,形成了一个完整的信息生命周期。信息生命周期管理(Information Lifecycle Management,简称ILM)实际上包括有效管理数据的一系列策略、过程和工具等,从而满足客户提高访问效率、降低存储开销、满足安全性和合规性要求等综合目标。
Oracle在12c之前已经为满足上述信息生命周期管理提供了大量技术,例如:在提高访问效率方面,Oracle已经提供了分区技术、迁移到高性能的表空间技术,将传统LOB字段迁移到性能更好的SecureFiles技术等。在降低存储开销方面,可采用11g提供的丰富多彩的数据压缩技术(Basic、OLTP、HCC、SecureFiles等),以及SecureFiles的去重技术,迁移到低成本存储表空间,删除过期数据等。在数据安全性管理方面,可采用传统的权限管理、视图设计,虚拟私有数据库(VPD)、基于标签数据库(OLS),采用普通审计和细粒度审计(FGA),以及Database Vault和Audit Vault等安全产品。
但是上述ILM管理中,都还是需要DBA或开发人员手工运用上述技术,并且进行大量针对ILM 的应用开发工作。在数据量、访问量日益增长的今天,这种手工方式很难满足需求的不断增长。Oracle是否有新的机制能自动分析数据访问情况,从而自动进行相关的ILM管理呢?例如自动将已经不访问或极少访问的数据进行压缩,或者迁移到低性能、廉价的存储上去呢?答案是有!这就是本章后面即将展开的Oracle 12c在ILM管理方面的新技术:Heap Mat、ADO、In-Database Archiving、Temporal Validity… …
Heat Map和ADO概述
所谓Heat Map,就是Oracle 12c提供的一种自动跟踪、分析和记录数据访问和数据变更情况的新技术,包括在Segment级别对数据访问和在数据块和Segment级别对数据访问变更情况的跟踪、分析,并将这些分析统计数据存储在位于SYSAUX表空间的相关系统数据字典表中。
为此,12c新增加了HEAP_MAP初始化参数。为启动Heat Map特性,可将HEAP_MAP初始化参数设置为ON,该参数缺省值为OFF,并且是动态参数。
SQL> ALTER SYSTEM SET heat_map = ON;
如果启动了Heat Map功能,Oracle将自动对除SYSTEM和SYSAUX之外所有数据对象的DML和访问操作进行跟踪、分析和保存。
所谓ADO,即Automatic Data Optimization(自动数据优化)技术,是指12c基于Heat Map的统计信息而创建一种策略,Oracle依据这种策略自动进行数据压缩和数据分层处理的新技术。
以下就是Heat Map和ADO技术结合使用的示意图:
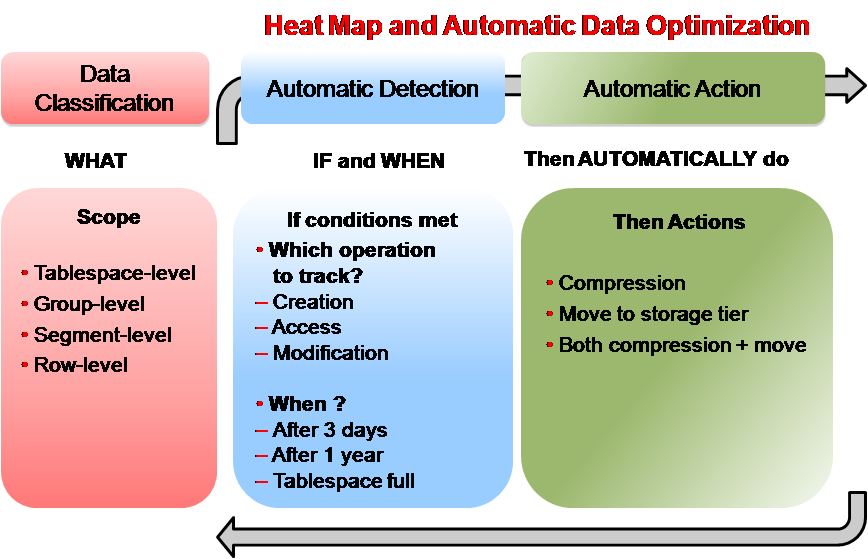
即在启动Heat Map技术之后,通过ADO首先可以在表空间、对象组、段、记录等不同级别定义相关的数据管理策略,当Oracle通过分析Heat Map统计信息,发现满足相关条件之后,Oracle接下来自动进行定义的数据管理动作,如:数据压缩、迁移数据到其它层级存储,或者二者兼有之。例如,当某个分区数据3天以上没有发生变更时,Oracle可自动对该分区数据进行压缩,免去了手工进行数据压缩的工作量。
Heat Map和ADO详细技术
Heat Map统计信息的查询
在启动Heat Map技术之后,可通过如下多种视图查询Heat Map统计信息:
- Segment级Heat Map统计信息
通过如下DBA_HEAT_MAP_SEG_HISTOGRAM、DBA_HEAT_MAP_SEGMENT等视图,可查询Segment级Heat Map统计信息。例如:
SQL> SELECT object_name, subobject_name, track_time, 2 segment_write WRI, full_scan FTS, lookup_scan LKP 3 FROM DBA_HEAT_MAP_SEG_HISTOGRAM; OBJECT_NAME SUBOBJECT_NAME TRACK_TIME WRI FTS LKP -------------- -------------- ---------- --- --- --- INTERVAL_SALES P1 02-JAN-12 YES YES NO INTERVAL_SALES P2 28-MAR-12 NO YES NO INTERVAL_SALES P3 28-MAR-12 NO NO YES I_EMPNO 07-dec-12 YES NO YES
其中:
- TRACK_TIME:该segment被访问时的系统时间。
- SEGMENT_WRITE:该segment是否有写操作。
- FULL_SCAN:该segment是否有全表扫描操作。
- LOOKUP_SCAN:该segment是否有按索引访问操作。
- DBA_HEAT_MAP_SEGMENT视图包括了Segment最新访问情况。
例如:
SQL> SELECT object_name, 2 segment_write_time WRITE_T, segment_read_time READ_T, 3 full_scan FTS_T, lookup_scan LKP_T 4 FROM DBA_HEAT_MAP_SEGMENT; OBJECT_NAME WRITE_T READ_T FTS_T LKP_T ----------- --------- --------- --------- --------- EMP 07-dec-12 T1 07-dec-12 08-dec-12 EMPLOYEE 07-dec-12 08-dec-12 08-dec-12 I_EMPNO 07-dec-12 08-dec-12
其中:
- SEGMENT_WRITE_TIME:该Segment最新写操作时间。
- SEGMENT_READ_TIME:该Segment最新读操作时间。
- FULL_SCAN字:该Segment最新全表扫描操作时间。
- LOOKUP_SCAN:该Segment最新按索引访问操作时间。
Oracle 12c后台NMON进程定期将保存在SYS.HEAT_MAP_STAT$ 、V$HEAT_MAP_SEGMENT等表和视图的Heat Map统计信息刷新到上述视图中。
- Block级Heat Map统计信息
通过DBMS_HEAT_MAP.BLOCK_HEAT_MAP表函数,可查询指定Segment的Block级Heat Map统计信息,例如:
SQL> SELECT segment_name, tablespace_name, block_id, writetime
2 FROM table(dbms_heat_map.block_heat_map
3 ('SCOTT','EMPLOYEE',NULL,8,'ASC'));
SEGMENT_ TABLESPACE_NAME BLOCK_ID WRITETIME
-------- ---------------- ---------- ---------
EMPLOYEE LOW_COST_STORE 196 12-DEC-12
EMPLOYEE LOW_COST_STORE 197 12-DEC-12
EMPLOYEE LOW_COST_STORE 198 12-DEC-12
其中输入参数如下:
- Owner:Segment所属用户
- Segment_name:Segment名称,例如普通非分区表名。如果是分区表,则该参数为空。
- Partition_name:分区名称。如果是普通非分区表,则该参数为空。
- Sort_columnid:字段排序号。取值范围:1到9。
- Sort_order:排序方式。取值:ASC、DESC
其中输出参数如下:
- Owner:Segment所属用户
- Segment_name:Segment名称,例如普通非分区表名。如果是分区表,则该参数为空。
- Partition_name:分区名称。如果是普通非分区表,则该参数为空。
- Tablespace_name:包含该Segment的表空间名称。
- File_id:包含该Segment的绝对文件名称。
- Relative_fno:包含该Segment的相对文件名称。
- Block_id: Block_id号。
- Writetime:Block的最新写操作时间。
- Extent级Heat Map统计信息
通过DBMS_HEAT_MAP.EXTENT_HEAT_MAP表函数,可查询出指定Segment的Extent级Heat Map统计信息,并且包括最小、最大修改时间。例如:
SQL> SELECT segment_name, block_id, blocks, max_writetime
2 FROM table(dbms_heat_map.extent_heat_map
3 ('SCOTT','EMPLOYEE'));
SEGMENT_ BLOCK_ID BLOCKS MAX_WRITETIME
-------- ---------- ---------- ------------------
EMPLOYEE 136 8 12-DEC-12 12:58:46
EMPLOYEE 144 8 12-DEC-12 12:58:46
EMPLOYEE 256 128 12-DEC-12 12:58:47
EMPLOYEE 384 128 12-DEC-12 12:58:47
其中输入参数如下:
- Owner:Segment所属用户
- Segment_name:Segment名称,例如普通非分区表名。如果是分区表,则该参数为空。
- Partition_name:分区名称。如果是普通非分区表,则该参数为空。
其中输出参数如下:
- Owner:Segment所属用户
- Segment_name:Segment名称,例如普通非分区表名。如果是分区表,则该参数为空。
- Partition_name:分区名称。如果是普通非分区表,则该参数为空。
- Tablespace_name:包含该Segment的表空间名称。
- File_id:包含该Segment的绝对文件名称。
- Relative_fno:包含该Segment的相对文件名称。
- Block_id: Block_id号。
- Blocks:该extent的Block数量。
- Min_writetime:Block最小修改时间。
- Max_writetime:Block最大修改时间。
- Avg_writetime:Block平均修改时间。
压缩策略的定义
在启动Heat Map技术之后,ADO流程的第二步就是根据不同条件,定义压缩和数据迁移策略。本节我们主要通过例子来介绍各级别压缩策略的定义和相关概念。
- 表空间级压缩
SQL> ALTER TABLESPACE tbs1 DEFAULT ILM ADD POLICY 2 ROW STORE COMPRESS ADVANCED 3 SEGMENT AFTER 30 DAYS OF LOW ACCESS;
该语句表示当30天后,如果tbs1表空间数据处于低访问(LOW ACCESS)状态,则tbs1表空间将自动按ROW STORE COMPRESS ADVANCED算法进行压缩。
所谓LOW ACCESS状态,是指Oracle自动根据ROWID访问量(按索引访问)、全表扫描量、DML操作量等统计值进行加权计算,而得到的一个综合指标。该指标与不同压缩算法相关,例如若采用ARCHIVE HIGH压缩算法,则ROWID访问量(按索引访问)和DML操作量的权重较高,而全表扫描量权重较低。至于该指标的详细计算公式,Oracle并没有公开,我们也就不深究了。
另外,所谓ROW STORE COMPRESS ADVANCED算法,也称之为Advanced Compression Option(简称ACO),实际上就是11g的OLTP压缩算法。
- Group级压缩
SQL> ALTER TABLE tab1 ILM ADD POLICY 2 ROW STORE COMPRESS ADVANCED 3 GROUP AFTER 90 DAYS OF NO MODIFICATION;
该语句表示当90天后,如果tab1表数据没有修改(NO MODIFICATION)时,则tab1表数据将自动按ROW STORE COMPRESS ADVANCED算法进行压缩。
另外,该语句指定了GROUP短语,表示该表的SecureFiles LOB字段也将进行相应的压缩。与表的ROW STORE COMPRESS ADVANCED压缩算法相对应的SecureFiles LOB压缩级别是LOW,而COLUMN STORE COMPRESS FOR QUERY LOW/QUERY HIGH和COLUMN STORE COMPRESS FOR ARCHIVE LOW/ARCHIVE HIGH压缩算法相对应的SecureFiles LOB压缩级别是MEDIUM。
同时,GROUP短语还表示该表进行压缩时,对应的Globle Index将自动进行维护。
再看如下语句:
SQL> ALTER TABLE tab2 MODIFY PARTITION p1 ILM ADD POLICY 2 COLUMN STORE COMPRESS FOR ARCHIVE HIGH 3 GROUP AFTER 6 MONTHS OF NO ACCESS;
该语句表示当6个月后,如果tab2表数据没有访问(NO ACCESS)时,则tab2表的p1分区数据将自动按COLUMN STORE COMPRESS FOR ARCHIVE HIGH算法进行压缩。
另外,GROUP短语表示p1分区的SecureFiles LOB字段也进行相对应级别的压缩,此时是MEDIUM级别压缩。
- Segment级压缩
SQL> ALTER TABLE tab4 ILM ADD POLICY 2 COLUMN STORE COMPRESS FOR QUERY HIGH 3 SEGMENT AFTER 90 DAYS OF NO MODIFICATION;
该语句表示当90天后,如果tab4表数据处于无修改(NO MODIFICATION)状态,则tab4表数据将自动按COLUMN STORE COMPRESS FOR QUERY HIGH算法进行压缩。
SQL> ALTER TABLE tab5 ILM ADD POLICY 2 COLUMN STORE COMPRESS FOR ARCHIVE HIGH 3 SEGMENT AFTER 6 MONTHS OF LOW ACCESS;
该语句表示当6个月后,如果tab5表数据处于低访问(NO MODIFICATION)状态,则tab5表数据将自动按COLUMN STORE COMPRESS FOR ARCHIVE HIGH算法进行压缩。
SQL> ALTER TABLE tab6 ILM ADD POLICY 2 ROW STORE COMPRESS ADVANCED 3 SEGMENT AFTER 6 MONTHS OF NO ACCESS;
该语句表示当6个月后,如果tab6表数据处于无访问(NO MODIFICATION)状态,则tab6表数据将自动按ROW STORE COMPRESS ADVANCED算法进行压缩。
- 行级压缩
SQL> ALTER TABLE tab1 ILM ADD POLICY 2 ROW STORE COMPRESS ADVANCED 3 ROW AFTER 30 DAYS OF NO MODIFICATION;
该语句表示当30天后,如果tab1表数据处于无修改(NO MODIFICATION)状态,则tab1表数据将自动按ROW STORE COMPRESS ADVANCED算法进行行级(Row-level)压缩。
需要说明的是,行级压缩只能采用ROW STORE COMPRESS ADVANCED压缩算法。
数据层级策略的定义
所谓数据层级策略(Tiering Policy),是指当指定表空间达到一个阀值时,ADO自动将该表空间或该表空间对象迁移到其它存储设备的表空间的一种策略和技术。例如:
SQL> ALTER TABLE tab6 MODIFY PARTITION p1 ILM ADD POLICY
2 TIER TO low_cost_storage;
该语句表示当tab6表的p1分区所在的表空间达到Oracle缺省指定的阀值时,p1分区数据将自动迁移到low_cost_storage表空间。
所谓Oracle缺省指定的阀值是指如下两个参数:
SQL> SELECT * FROM dba_ilmparameters;
NAME VALUE
————————- ———-
TBS PERCENT USED 85
TBS PERCENT FREE 25
即分别表示表空间使用率(TBS PERCENT USED)达到85%,或者表空间空闲率(TBS PERCENT FREE)低于25%。
通过如下语句可定制化这两个参数值:
SQL> EXEC DBMS_ILM_ADMIN.CUSTOMIZE_ILM(DBMS_ILM_ADMIN.TBS_PERCENT_USED,90);
SQL> EXEC DBMS_ILM_ADMIN.CUSTOMIZE_ILM(DBMS_ILM_ADMIN.TBS_PERCENT_FREE,15);
如果实施了数据层级的某表空间达到了表空间使用率阀值(TBS PERCENT USED),例如85%,假设该表空间有多个数据对象,Oracle如何进行数据迁移,从而使得该表空间空闲率(TBS PERCENT FREE)降到25%?答案是Oracle采用最少访问表迁移的策略(The Least Recently Access)。例如,假设某个表空间包含T1,T2, T3表,分别在上周、今天和昨天被访问过,该表空间假设达到了表空间使用率阀值,则T1表首先被迁移走。如果表空间空闲率仍然没有降到25%,则T3表被迁移走,直至表空间空闲率降到25%。
根据ILM管理需求,很多历史数据不仅需要迁移到低端存储,而且这些数据可能不需要改动了。为此,ADO提供了如下语句:
SQL> ALTER TABLE tab7 ILM ADD POLICY
2 TIER TO tablespace_tbs
3 READ ONLY;
SQL> ALTER TABLE sales MODIFY PARTITION HY_2010 ILM ADD POLICY
2 TIER TO tablespace_tbs
3 READ ONLY;
即第一个语句将tab7数据迁移到tablespace_tbs表空间,并且设置为只读状态。第二个语句将sales表的HY_2010分区数据迁移到tablespace_tbs表空间,并且设置为只读状态。
客户化策略的定义
除了上述Oracle内置提供的压缩和数据层级策略定义之外,用户还可以通过自定义函数的方式,来客户化定义策略,从而满足更复杂的ILM管理需求。
例如,如下语句假设创建了一个返回TRUE或FALSE的函数:
SQL> CREATE FUNCTION CUSTOM_ILM_RULES
2 (objn IN NUMBER)
3 RETURN BOOLEAN …
n /
如下语句可引用上述函数,达到客户化定义策略的目的:
SQL> ALTER TABLE EMP ILM ADD POLICY
2 ROW STORE COMPRESS ADVANCED
3 SEGMENT ON CUSTOM_ILM_RULES;
SQL> ALTER TABLE sales MODIFY PARTITION before_jan_2005
2 ILM ADD POLICY
3 TIER TO history ON CUSTOM_ILM_RULES;
21.7 数据归档新技术
In-Database Archiving(数据库内部归档)技术
- 数据归档的常规做法和问题
在Oracle 12c之前,当数据库的数据规模日益增长而不堪重负之后,IT系统管理者和技术人员通常想到的就是数据库瘦身计划,即把已经极少访问的历史数据进行归档,例如迁移到磁带或磁带库中,从而达到降低生产系统数据规模,提高生产系统数据库访问性能的目的。
但这种策略带来的问题也非常明显,如果需要查询归档数据,开发人员和管理员又不得不编写程序将需要的数据从磁带或磁带库中折腾回数据库内部,这种归档数据的往返迁移的确增加了管理和开发人员的负担。
12c针对这种数据归档的常规做法有什么新技术,并有效解决常规做法的问题呢?有,答案就是:In-Database Archiving技术,翻译过来叫数据库内部归档技术。
- In-Database Archiving技术细节
我们通过如下例子来介绍In-Database Archiving技术:
SQL> CREATE TABLE emp
2 (EMPNO NUMBER(7), FULLNAME VARCHAR2(40),
3 JOB VARCHAR2(9), MGR NUMBER(7))
4 ROW ARCHIVAL;
上述语句不仅创建emp表,而且定义该表采用In-Database Archiving技术,即使用ROW ARCHIVAL技术。通过该技术,用户可根据记录的访问情况确定其状态: Active 或non_Active。该技术实际上在表中增加了一个内部字段:ORA_ARCHIVE_STATE。
缺省情况下,当记录第一次插入时,该字段值为‘0’,表示为Active状态。随着时间的延长,当记录已经极少被访问也没有修改时,客户可将该字段值设置为非‘0’状态,比如‘1’,表示该记录为non-Active状态了。
用户只有在明确指定ORA_ARCHIVE_STATE字段的情况下,方能看到该字段内容,例如:
SQL> SELECT ORA_ARCHIVE_STATE, fullname FROM emp;
ORA_ARCHIVE_STATE FULLNAME
—————– ——————
0 JEAN <—- Active
1 ADAM <—- Non-Active
1 TOM <—- Non-Active
1 JIM <—- Non-Active
通过如下方式可手工设置记录的活跃状态:
/* 将指定记录设置为non-Active状态*/
SQL> UPDATE emp
2 SET ORA_ARCHIVE_STATE = DBMS_ILM.ARCHIVESTATENAME(1)
3 WHERE empno < 100;
/* 将指定记录恢复为Active状态*/
SQL> UPDATE emp
2 SET ORA_ARCHIVE_STATE = DBMS_ILM.ARCHIVESTATENAME(0);
通常缺省情况下,在会话级用户只能看到Active数据,例如:
SQL> SELECT ORA_ARCHIVE_STATE, fullname FROM emp;
ORA_ARCHIVE_STATE FULLNAME
—————– ——————
0 JEAN <—- Active
如果欲查询到所有数据,则可在会话级设置如下参数:
SQL> alter session set ROW ARCHIVAL VISIBILITY = ALL;
SQL> SELECT ORA_ARCHIVE_STATE, fullname FROM emp;
ORA_ARCHIVE_STATE FULLNAME
—————– ——————
0 JEAN <—- Active
1 ADAM <—- Non-Active
1 TOM <—- Non-Active
1 JIM <—- Non-Active
正因为In-Database Archiving技术的存在,使得当前和归档数据实际上仍然保存在生产系统数据库中。这样,应用软件能很好地控制是否需要只查询当前数据或查询归档数据。当访问当前数据时,Oracle能自动过滤掉归档数据,确保访问的高性能。当需要访问归档数据时,又不需要编写程序将数据从磁带或磁带库重新加载,而只需要设置一个Session级的ROW ARCHIVAL VISIBILITY 参数为 ‘ALL’即可。
欲关闭In-Database Archiving技术,也非常简单。如下所示:
SQL> ALTER TABLE emp NO ROW ARCHIVAL;
该语句将自动删除emp表隐藏的ORA_ARCHIVE_STATE字段。
Temporal技术
除了上述In-Database Archiving(数据库内部归档)技术,12c在数据归档方面还提供了所谓的Temporal技术。由于在笔者写作此章时,12c尚未正式发布,Temporal技术也没有官方的中文术语,暂且就不翻译了。
Temporal技术又分为Temporal Validity和Temporal History技术。其中Temporal History技术就是11g的FDA技术,或Total-Recall技术,本书第12章已有讲述。虽然12c在Temporal History技术方面有所新特性增强,但限于篇幅,我们就不讲述了。而Temporal Validity则是12c纯新技术,我们下面将重点讲述。
我们同样通过如下例子来讲述Temporal Validity技术:
SQL> CREATE TABLE emp
2 ( empno number, salary number, deptid number,
3 name VARCHAR2(100),
4 user_time_start DATE, user_time_end DATE,
5 PERIOD FOR user_time (user_time_start,user_time_end));
上述语句除创建emp表之外,还通过PERIOD FOR短语表示该表采用了Temporal Validity技术。所谓emporal Validity技术,就是指表记录的可视性将由PERIOD FOR指定的时间维度字段的范围而定,只有落在时间字段范围之内的记录,相关SQL语句才可看见这些记录,而落在时间字段范围之外的记录,相关SQL语句则无法访问这些记录。而记录的时间范围则完全由应用程序来控制。例如,应用程序插入如下数据:
SQL> INSERT INTO emp (empno, salary, deptid, name,
2 user_time_start, user_time_end)
3 VALUES (1,1000,20, ‘John’, to_date(’01-JAN-1990′,’DD-MON-YYYY’), to_date(’31-DEC-2010′,’DD-MON-YYYY’));
SQL> INSERT INTO emp (empno, salary, deptid, name,
2 user_time_start, user_time_end)
3 VALUES (2,1500,10, ‘Scott’, to_date(’01-JAN-1991′,’DD-MON-YYYY’), to_date(’31-DEC-2012′,’DD-MON-YYYY’));
… …
SQL> INSERT INTO emp (empno, salary, deptid, name,
2 user_time_start, user_time_end)
3 VALUES (10,800,30, ‘Kim’, to_date(’01-JAN-1994′,’DD-MON-YYYY’), to_date(’30-JUN-1994′,’DD-MON-YYYY’));
当使用如下新的PERIOD FOR短语,执行如下查询:
SQL> select * from hr.emp as of PERIOD FOR user_time
2 to_date(’01-DEC-1992′, ‘dd-mon-yyyy’) ;
Oracle将只返回第一条John和第二条Scott记录,而不会返回第三条Kim记录,因为Kim的User_time有效期为1994年1月1日至1994年6月30日,不包括上述查询语句指定的1992年12月1日。
当使用如下新的VERSIONS PERIOD FOR短语,执行如下查询:
SQL> SELECT * FROM hr.emp VERSIONS PERIOD FOR user_time
2 BETWEEN to_date(’31-DEC-2011′,’DD-MON-YYYY’)
3 AND to_date(’31-DEC-2012′,’DD-MON-YYYY’);
Oracle将只返回第二条Scott记录,因为只有Scott的User_time有效期在上述查询语句指定的2011年12月31日至2012年12月31日之间。
用户也可通过如下语句使用Temporal Validity技术:
SQL> CREATE TABLE emp2
2 ( empno number, salary number, deptid number,
3 name VARCHAR2(100),
3 PERIOD FOR user_time);
即在表字段定义不用指定时间维度字段,而只要在PERIOD FOR短语中指定时间维度名称user_time。Oracle将自动创建user_time_start和user_time_end两个时间维度字段。
Oracle 12c还提供了DBMS_FLASHBACK_ARCHIVE包来控制记录的可视性。例如:
SQL> exec DBMS_FLASHBACK_ARCHIVE.ENABLE_AT_VALID_TIME(‘ASOF’,
(to_timestamp(’29-SEP-10 05.44.01 PM’))
当在某会话中执行上述语句后,表明该Temporal Validity表的记录只有落在29-SEP-10 05.44.01 PM之内,才能被该会话中的正常SQL和DML操作看见。
如下语句:
SQL> exec DBMS_FLASHBACK_ARCHIVE.ENABLE_AT_VALID_TIME(‘CURRENT’);
则表明Temporal Validity表的记录只有落在当前时间之内,才能被该会话中的正常SQL和DML操作看见。
如下语句:
SQL> exec DBMS_FLASHBACK_ARCHIVE.ENABLE_AT_VALID_TIME(‘ALL’);
则表明将Temporal Validity表的记录全部可视,这也是Temporal Validity表的缺省设置。
需要说明的是,DBMS_FLASHBACK_ARCHIVE包只能控制查询和DML语句,而DDL语句将能访问所有记录。例如:CTAS、alter table move、在线重定义等操作。
采用Oracle 12c新技术还是应用程序
在目前的技术条件下,大部分应用开发人员基本都通过编写应用程序来进行数据归档。其好处在于可有效实现数据归档的各种复杂业务逻辑,而且由于运用成熟技术,稳定性较好。但缺点是不仅数据归档应用程序本身复杂,而且由于归档数据脱离了生产环境,给归档数据的访问带来很大不便,应用开发人员又不得不编写将归档数据加载回生产系统的程序,同时也给归档数据和当前数据的共同访问和计算带来麻烦。
如果采用上述Oracle 12c的数据归档新技术In-Database Archiving和Temporal Validity呢?好处不言而喻,由于归档数据其实还保存在生产系统数据库中,不仅不用编写数据归档程序了,也确保生产系统应用的性能得到提升,而且对归档数据的访问也非常便利。但是,新技术的有效性和稳定性如何呢?只有不断去尝试,并且在Oracle不断丰富、完善之后才可考虑这些技术的使用范围和深度了。但不管怎样,Oracle 12c的这些数据归档新技术,的确为满足海量数据管理,特别是数据生命周期管理提供了新的技术手段和思路。不妨一试。
21.8 “貌合神离,貌离神合”
各行各业数据中心建设如火如荼,但到底是建成大一统的架构,还是将大系统又拆分成若干分离的系统?这是困扰IT系统决策部门和架构设计人员的重大问题。正如古语:“合久必分、分久必合”一样,很多IT系统也一直处于先进行整合,然后又进行拆分等纠结和矛盾之中。这种分分合合的行为,一方面与业务发展和需求相关,另一方面也是与IT技术,特别是IT架构技术发展相关。
为满足IT系统发展需求,Oracle公司在数据库架构技术方面一直处于不断的推陈出新之中。Oracle传统的RAC、ASM、资源管理、Service等技术,为数据库整合提供了技术基础架构和多种技术手段。Oracle 12c在数据库云计算架构和信息生命周期管理方面推出了更多新技术,这些又为企业数据中心架构设计提供了新的思路。
“貌合神离”
数据库云计算和资源整合一个重要目标就是将现有大量独立的竖井式系统整合成一个资源共享池,从而达到降低IT系统成本、提高资源利用率、降低IT系统复杂性、提高IT系统灵活性、提高IT系统服务质量等目的。如下图所示:
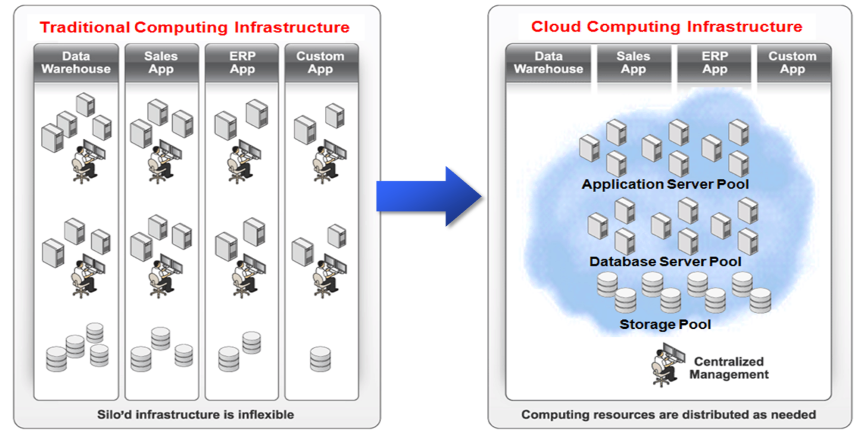
但这种大一统架构又给IT部门领导和技术人员带来新的忧虑:如何在这个大资源池中,对众多数据和应用进行精细化的管理?如何确保某个不良应用不要耗尽资源,更不要对其它正常应用产生不良影响?如何在尽量不停机情况下下,进行各种数据库维护操作?如何加强数据安全性管控?… …
好在Oracle早就提供了Service、资源管理(Resource Manager)、各种在线操作技术,以及Database Vault等数据库安全性产品,这些都能有效解决上述客户的疑虑。例如,根据各业务特征设计相应的Service,这样就可以按Service来进行应用部署、性能监控、作业调度、高可用性切换等,从而达到对众多应用进行精细化管理和运行的目的。
这就是所谓的“貌合神离”,即看似数据库都集中、整合了,但实际上仍然可以通过多种技术手段进行分门别类的精细化管理。
“貌离神合”
大部分行业的IT系统特别是核心生产系统,在天长地久的运行之后,都出现了应用越来越复杂,数据量越来越庞大的臃肿现象,也带来了性能、稳定性等多方面问题。于是,除了硬件扩容、应用优化、数据压缩等各种措施之外,IT决策者们都在试图对这些系统进行消肿,例如,将运行了过多应用的大系统拆分成若干系统,将堆积了过多信息,特别是访问频度很低的历史数据迁移到专门的历史数据库之中。
但这种系统和数据的拆分操作又带来了新的问题:系统拆分之后,不是又回到传统竖井式架构带来的资源浪费、管理复杂等问题吗?另外,假设历史数据迁移出去了,我们又想查询历史数据,例如将历史数据与当前数据进行对比分析、汇总统计等操作,怎么办?再将需要的数据迁移回生产系统,还是专门写程序进行跨库操作?这些都是我们在拆迁之前必须面对的问题。
好在作为IT基础架构供应商的Oracle公司,在Oracle 12c中推出的CDB、PDB架构,以及数据库内部归档(In-Database Archiving)等数据生命周期管理方面的新技术,为解决上述如何消肿的问题,提供了新的思路。
以某移动公司为例。该移动公司拟将现有CRM按应用功能和模块拆分成若干系统,我们能否采用12c的CDB、PDB架构,做到“貌离神合”呢?以下就是示意图:
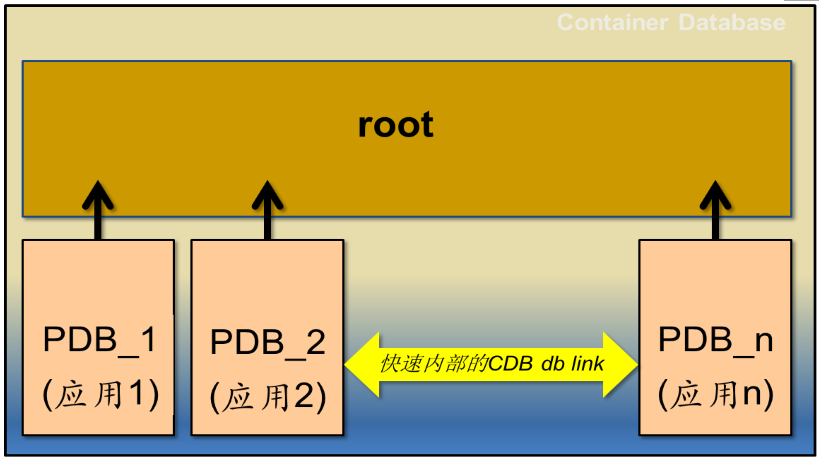
也就是说,将现在CRM一个大数据库在现有平台上按照应用和数据分类,拆分成多个PDB。这样,将现在按Schema、表进行分离的数据,以PDB形式进行重新部署,既提高了不同应用和数据之间的隔离性,也降低了不同应用之间的相互影响,同时还提高了管理的灵活性,并降低了故障影响范围。另外,由于仍然是在一个平台、一个实例上运行,这种架构仍然能充分体现资源共享、管理简化等云计算基本特征。这就是在应用层面的“貌离神合”。
这种“貌离神合”策略相比将系统拆分成若干绝对隔离的物理系统,更为先进和有益,绝对隔离架构又回到了硬件资源增加、资源利用不均衡、架构复杂、运维工作量大、库与库互操作效率低等老路。以库与库互操作为例,传统的DB-link技术存在性能低、无法使用并行处理技术等缺陷,而12c的 PDB之间是采用内部的快速DB-link技术,实际上是在一个CDB内部的互操作,与传统DB-link操作的性能不可同日而语。
再从该移动公司的历史数据迁移需求来诠释“貌离神合”的理念。所谓历史数据迁移就是通过创建一个历史库,并将业务上定义为历史数据、访问频度很低的数据从生产系统迁移到历史库中。在技术层面,针对大批量数据迁移需求,Oracle已经提供了大量成熟的先进技术,例如并行导出和导入、表空间迁移等。但在历史数据管理中,其实最让客户困惑的是业务层面问题:“如何确定历史数据标准?”,“如何同时操作当前数据和历史数据?”…为回答这些问题,其实我们应从源头分析历史数据迁移的动机:我们进行历史数据迁移不就是为了对生产系统瘦身,最终目的是为了提高应用的访问性能吗?让我们反向思维:假设不进行历史数据迁移,但Oracle自己能识别出哪些数据访问频度很低,并自动设置为历史数据,这样当前应用就访问不到这些历史数据,性能不就提高了吗?同时操作当前数据和历史数据也不是问题了。这就是Oracle 12c的 数据库内部归档技术(In-Database Archiving)!
通过In-Database Archiving技术,使得当前和历史数据实际上仍然保存在生产系统数据库中,应用软件却能很好地控制是否需要只查询当前数据或查询历史数据。当访问当前数据时,Oracle能自动过滤掉历史数据,确保访问的高性能。当需要访问历史数据时,不需要编写程序将数据从历史库重新加载,或者编写跨库操作的应用,而只需要进行某些参数设置即可。
这样,不仅提高了应用访问性能,而且也免去了专门建设历史库、专门开发应用之苦。况且历史库建设还不一定能真正满足业务需求。既然当前数据和历史数据难以区分,为什么一定要去分呢?
这就是所谓的数据层面“貌离神合”:看似数据划分成当前数据和历史数据了,但实际上仍然存储在一起,应用也仍然是一个整体。
12c实施案例
12c才刚出来个第一版,就有人要吃螃蟹了!在本人最近负责提供服务的几个移动运营商客户分别结合自身业务需求,提出了在12c平台建设新系统的项目计划。这种驱动力一方面来自于移动集团对各省公司的创新激励机制,另一方面也是各省公司在仔细研究12c架构新特性,并分析各自业务需求之后,提出的有针对性的建设方案。—- 不能为了创新而创新。
当然,12c的确是新出炉的第一版产品,Bug、问题肯定少不了。为稳妥期间,这些客户实际上都是将非核心的外围系统部署在12c平台,而且在本人写作此章的2013年12月,这些项目还处于初步酝酿和环境搭建之中。以下就介绍2个案例。
地市统一支撑云平台建设
- 现状及需求
目前,XX移动各地市均部署了相应的数据库系统和应用系统,虽然基本了满足各地市的业务需求,但这种分离的架构也给各地市的运行维护、数据资源共享和交换等带来了困难。
为此,XX移动拟基于云平台技术,在 IaaS、PaaS、SaaS三个层面进行数据和应用的整合,以下就是其“地市统一支撑云平台”的基本框架和建设思路:
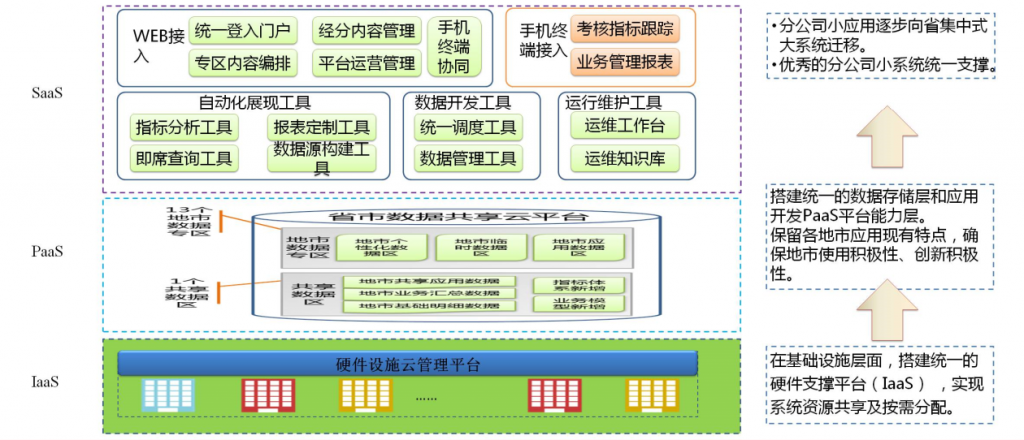
- 数据库云平台建设思路
以下就是基于12c架构开展的数据库云平台建设思路
- 在省公司部署一套基于X86平台的多节点12c RAC环境。
- 利用12c的CDB、PDB架构,对各地市数据库进行部署。
- 共享数据区部署在CBD库中。包括地市共享应用数据、地市业务汇总数据、地市基础明细数据、指标体系新增、业务模型新增等。
- 地市数据专区则部署在CDB库中。包括地市个性化数据区、地势临时数据区、地市应用数据区等。
- 通过CDB、PDB、Service、资源管理等技术实现精细化的管理,达到“貌合神离”的效果。
- 利用集中统一的整合平台,降低数据库运行维护工作量,提高数据资源共享和交换能力,达到“貌离神合”的效果。
- 利用12c在数据生命周期管理方面的若干新技术、新特性,开展各地市历史数据管理实施工作。
- 在基于12c整合的平台,尤其是利用12c相关新特性,开展各地市系统的优化和整改工作。
- 实施计划
以下就是我们为该项目在PaaS层面提供的12c服务计划:
| 阶段 | 主要任务 | 详细内容 |
| 需求系统设计 | 各地市现有系统调研工作 | 调研各地市现有系统平台、版本、架构、数据库字符集、性能等总体情况 |
| 地市资源池架构设计工作 | 在12c平台,开展地市资源池架构设计工作,包括12c RAC架构设计;CDB、PDB架构设计;版本和补丁方案设计等 | |
| 12c日常运维管理方案设计 | 包括12c Clusterware、ASM、RAC、CDB、PDB日常运维方案和操作。例如CDB和PDB启动和关闭、CDB和PDB的数据库备份和恢复等。 | |
| 资源池迁移方案设计 | 针对各地市系统的不同需求,开展“升级 + Plug”、“创建PDB + 导入数据”等迁移方案设计 | |
| 12c RAC高可用性方案设计 | 针对具体应用开展高可用性方案设计,例如负载均衡、TAF、Failover、Service等设计,同时开展各种软、硬件的故障模拟案例设计 | |
| 12c RAC变更管理方案设计 | 开展Clusterware、ASM、RAC等变更管理方案,例如如何进行公网、私网的变更,如何进行补丁实施,如何进行ASM磁盘的增加、删除等。 | |
| 历史数据管理方案设计 | 针对各地市系统的不同需求,开展基于12c的Heat Map和ADO、数据库内部归档 (In-Database Archiving)等技术的历史数据管理方案设计工作 | |
| 其它整改和优化方案设计 | 针对各地市系统的不同需求,基于12c整合的平台,尤其是利用12c相关新特性,开展各地市系统的优化和整改方案设计工作 | |
| 12c技术交流和知识转移 | 开展12c技术交流和知识转移工作 | |
| 环境建立 | 硬件环境准备的技术支持和环境检查 | 提供硬件系统环境需求,例如操作系统补丁、包的需求,网络配置需求等,并进行环境检查和确认 |
| 地市资源池数据库系统软件的安装、配置和调试 | 安装12c RAC软件及相关补丁 | |
| 创建CDB、PDB数据库,加载数据 | 针对典型地市,创建CDB、PDB数据库,并加载相关模拟数据 | |
| 系统备份环境搭建的技术支持 | 为物理备份环境的搭建提供技术支持,同时开展Catalog数据库创建、与磁盘或磁带库的连接等实施工作 | |
| 系统测试 | 12c日常运维管理方案测试 | 开展12c Clusterware、ASM、RAC、CDB、PDB日常运维方案测试工作。例如CDB和PDB启动和关闭、CDB和PDB的数据库备份和恢复等。 |
| 资源池迁移方案测试 | 针对各地市系统的不同需求,开展“升级 + Plug”、“创建PDB + 导入数据”等迁移方案测试工作 | |
| 12c RAC高可用性方案测试 | 针对具体应用开展高可用性方案测试工作,例如负载均衡、TAF、Failover、Service等设计,同时开展各种软、硬件的故障模拟案例测试 | |
| 历史数据管理方案测试 | 针对各地市系统的不同需求,开展基于12c的Heat Map和ADO、数据库内部归档 (In-Database Archiving)等技术的历史数据管理方案测试工作 | |
| 其它整改和优化方案测试 | 针对各地市系统的不同需求,基于12c整合的平台,尤其是利用12c相关新特性,开展各地市系统的优化和整改方案测试工作 | |
| 上线阶段 | 正式环境上线前封装检查 | 针对地市资源池生产系统,进行封装检查 |
| 上线前性能基线收集 | 针对地市资源池生产系统,进行上线前性能基线收集 | |
| 正式迁移割接 | 针对地市资源池生产系统,正式迁移割接 | |
| 上线后性能监控 | 针对地市资源池生产系统,进行上线后性能监控 | |
| 上线后支持阶段 | 上线后的技术支持服务 | 上线值守 |
| 上线后数据库性能调整优化 | 后期优化调整 | |
| 项目管理 | 项目管理 | 项目计划、文档管理等 |
综合日志库的建设
就像大多数企业客户一样,XX移动公司拥有IBM、HP、EMC、思科、华为等数以千计的硬件设备,还拥有Oracle、DB2、SYBASE、TERADATA、TimesTen、HADOOP、MySQL、WebLogic等系统软件。这些软硬件都会产生大量的后台日志,这些日志对故障分析、事件跟踪、安全审计等方面都有重要意义。
随着运行时间的增长,这些日志也会急剧膨胀,消耗大量存储资源。面对这种情况,系统管理员、DBA的通常做法就是将这些日志文件分门别类归档之后,然后清空当前日志。这种现状带来的问题是由于缺乏统一的日志管理平台,导致日志文件管理存在散、乱,不利于综合利用和分析等问题,也导致运维工作量的增加。
为解决这种问题,XX移动公司提出了综合日志库的建设项目。即将操作系统、数据库、应用服务器等多个技术层面的日志信息进行集中管理,同时覆盖CRM、计费、账务、经分等多套业务系统。
如何在技术架构上加以实现呢?12c的CDB、PDB再适合不过了。以下就是初步的架构示意图:
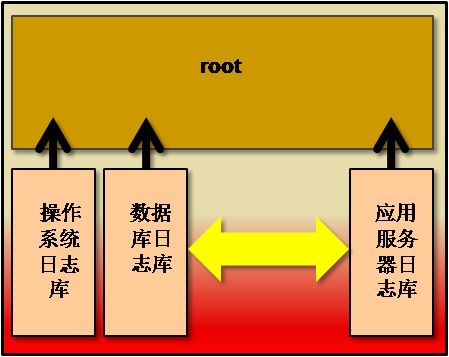
即以IT技术层面进行CDB和PDB的设计,例如按操作系统、数据库、应用服务器、网络分类进行PDB设计。当然也可考虑按业务系统划分,例如按CRM、计费、账务、经分等分类进行PDB设计。
据客户初步估算,该综合日志库初始容量就将达到10TB,而且还将高速增长。日志信息如何有效进行数据生命周期管理?如何压缩、如何分层管理?12c的Heat Map和ADO技术、In-Databaes Archiving技术、Temporal技术等将发挥重要作用。
究竟如何设计CDB/PDB架构?如何有效进行日志信息的自动化管理?在笔者写作之时,项目仍然在初步运筹和环境搭建之中。欲知实际实施效果,且等笔者新作了,呵呵。
21.10本章参考资料及进一步读物
本章参考资料及进一步读物:
| 序号 | 资料类别 | 资料名称 | 资料概述 |
| 1. | Oracle 12c联机文档 | 《Oracle® Database New Features Guide》 | 就像Oracle以前每个新版本一样,这是一本描述Oracle 12c新特性的专门文档,DBA和开发人员都应该先睹为快。 |
| 2. | Oracle 12c联机文档 | 《Oracle® Database Administrator’s Guide》Part VI“Managing a Multitenant Environment” | 这是Oracle 12c联机文档中,最集中、最全面讲述多租户环境即CDB/PDB的地方。 |
| 3. | Oracle 12c联机文档 | 《Oracle® Database VLDB and Partitioning Guide》第五章“Managing and Maintaining Time-Based Information” | 这是Oracle 12c联机文档中,最集中、最全面讲述信息生命周期管理的地方:Heat Map、ADO、In-Database Archiving、Temporal Validating… … |
| 4. | Oracle大学培训教材 | 《Oracle Database 12c:New Features for Administrators》 | Oracle大学全面系统进行12c新特性培训的教材,参加该课程培训,一定物超所值!呵呵。 |
| 5. | My Oracle Support | 《Master Note for the Oracle Multitenant Option (Doc ID 1519699.1)》 | 有关12c多租户即CDB/PDB的资料汇集地:联机文档、白皮书、论坛、最佳实践经验等。 |
| 6. | My Oracle Support | 《How to migrate an existing pre12c database(nonCDB) to 12c CDB database ? (Doc ID 1564657.1)》 | 如何将传统非CDB数据库升级/迁移到12c CDB?本文档给出了相关技术方案。 |
| 7. | My Oracle Support | 《Oracle Multitenant Option – 12c : Frequently Asked Questions (Doc ID 1511619.1)》 | 什么叫CDB/PDB?CDB/PDB的好处何在?如何实施 CDB/PDB?这些林林总总的问题,基本都能在这篇文档中找到答案。 |
| 8. | My Oracle Support | 《Information Lifecycle Management (ILM), Heat Map, Automatic Data Optimization (ADO) (Doc ID 1612385.1)》 | 这是一片简要讲述ILM、Heat Map、ADO的官方文档,帮助大家快速了解这些12c的重要新特性。 |
| 9. | Oracle白皮书 | 《 Automatic Data Optimization with Oracle Database 12c》 | 这是Oracle技术网站(http://otn.oracle.com)中有关12c ADO技术的白皮书。链接是:http://www.oracle.com/technetwork/database/enterprise-edition/automatic-data-optimization-wp-12c-1896120.pdf |
| 10. | My Oracle Support | 《12c: In-Database Archiving And Compression (Doc ID 1592186.1)》 | 如何将非活动数据进行压缩并进行数据库内部归档,而将当前活动数据保持为非压缩状态?本文档给出了一个详细脚本案例。 |
Leave a Reply