SHOUG成员 – ORACLE ACS高级顾问罗敏
话说故障诊断
故障处理的确是一个涉及面既广又非常深入的领域。但Oracle数据库故障诊断就像世上其它领域的故障诊断一样,都遵循“获取故障现象和数据->故障原因分析->提供解决方案->解决方案测试->正式实施解决方案->故障处理后的评估分析”的通用思路。因此,只要心态平稳、方法得当,再复杂的故障都会找出问题端倪,并通过与各方协调,最终得到解决的。
本章首先将以若干故障诊断案例开始,介绍其中的经验和感悟。然后将介绍故障信息采集的重要性,特别是RDA、AWR、ADDM、DiagCollection.sql、RACCheck、Hanganalyze等数据库故障诊断基本工具的运用,最后又将回到案例,与各位共同分享故障诊断其中的苦与乐。
通过案例看故障诊断
其实,作为Oracle公司的解决方案顾问,我已经基本远离了故障诊断这样具体而富有挑战性的一线工作。但最近有幸为某客户的数据库升级和迁移提供现场技术支持服务,再次品味了现场故障诊断的那份紧张、刺激,甚至些许的成就感。下面通过该案例中几个具体故障的解决,与大家一块儿分享其中的经验、方法和规律,还有“痛并快乐着”的切身感受。
故障1:数据没装进去
- 故障现象
该系统投产前一天,应用开发商在进行正常的功能测试时,发现新系统中一张表的数据为空。由于该项目采取Exp/Imp方式进行升级和迁移,于是我让客户赶紧查一下Exp和Imp的日志文件。果然,在Imp日志文件中显示,该表在进行Imp操作时,出现如下一段错误信息,导致该表数据没有装进去。
IMP-00020: long column too large for column buffer size (number)
- 故障原因和解决方法
有病不可怕,就怕病人说不清自己的症状,也怕没有相关的检查报告和指标。同样地,数据库出故障也不可怕,只要有错误信息,就可追根溯源了。以下就是Oracle关于IMP-00020错误的原因分析和解决方法:
IMP-00020: long column too large for column buffer size (number) Cause: The column buffer is too small. This usually occurs when importing LONG data. Action: Increase the insert buffer size 10,000 bytes at a time (for example). Use this step-by-step approach because a buffer size that is too large may cause a similar problem.
原来是客户在进行数据导入Imp操作时,BUFFER参数设置过小了,特别是在加载LONG类型字段时容易触发该问题,但根据上述关于该错误的Oracle官方解释,BUFFER参数设置过大也会出现相似问题。于是,我建议客户将BUFFER 参数由当前的1G先调大到1.5G,并重新进行Imp操作,没想到问题很快得到解决了。
- 经验和体会
该问题从客户发现到找到原因和解决方法,前后不到5分钟,应该说非常快捷。这就是经验之一:出了问题别紧张,首先找问题错误信息,然后第一时间是在Oracle联机文档的错误信息手册《Oracle® Database Error Messages》中,去查找该错误信息的原因和解决办法,上述信息就是来自该手册。
经验:建议大家在自己笔记本中一定要安装Oracle不同版本的联机文档,看到错误信息,先查错误信息手册。Oracle联机文档的确是个宝藏,针对故障诊断也同样有效。甚至连网都不用上,错误信息手册是最快捷的故障诊断手段!
故障2:RAC安装不上
相比上述相对简单,而且影响面较小的故障,该项目面临的第一个也是影响更大的故障是:RAC安装不上!以下就是详细过程:
- 故障现象
更准确而言,客户是在安装CRS时就失败了,以下是安装程序(OUI)界面显示的错误:
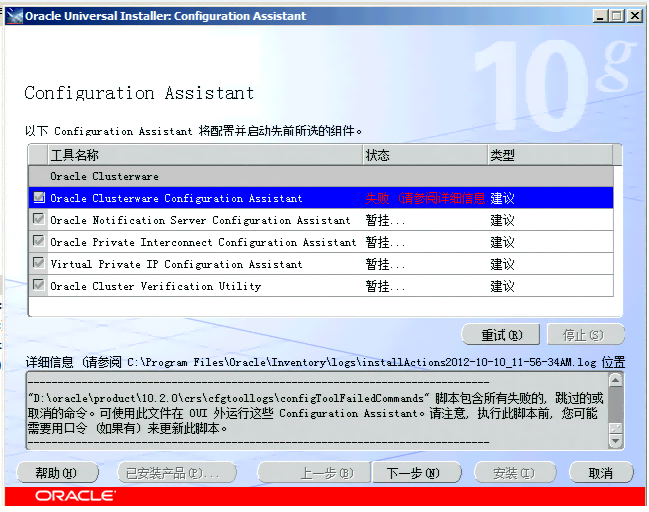
- 故障原因
显然,OUI图形界面上的信息不足以分析问题原因,但Oracle已经告诉我们去看’C:\Programs Files\Oracle\Inventory\logs\installActions2012-10-10_11-56-34AM’安装日志文件,了解更详细信息了。以下就是该文件最后的部分内容:
… … Command = C:\Windows\system32\cmd /c call D:\oracle\product\10.2.0\crs/install/crssetup.config.bat has failed Execution Error : failed waiting for completion of ocr configuration with CLSCFG [ 0 ] The operation completed successfully. … …
接下来,通过上述“Execution Error : failed waiting for completion of ocr configuration with CLSCFG”信息,我们在metalink中找到了文章:《CRS Installation Failed with “failed to configure Oracle Cluster Registry with CLSCFG, ret 9” [ID 851742.1]》
该文章对错误原因描述如下:
Cause: OUI did not handle the return code properly. The return code [0] "The operation completed successfully" is actually a successful message.
哦,原来OUI犯了一个小小的错误:本来返回值0是正常的,但OUI却以为安装过程出问题,而停止安装过程了。
- 解决办法
以下就是[ID 851742.1]给出的解决办法:
Solution: To workaround the issue:
-
Rerun $ORA_CRS_HOME\install\crssetup.config.bat from a command prompt window.
This will complete CRS service creation and bring up all CRS services on both nodes.
-
Continue to run commands listed in $ORA_CRS_HOME\cfgtoollogs\configToolFailedCommands to complete the installation.
-
The cluvfy command in the last step should return successful check result.
上述解决办法说白了,就是不使用OUI图形界面了,用户通过命令行方式一步一步进行手工安装,即可顺利安装成功。
- 经验和体会
解决问题关键的第一步就是找准问题症状。在该问题中,就是在installActions2012-10-10_11-56-34AM安装日志文件中找到了上述错误信息。因篇幅因素,本书并没有展开该日志文件,其实找到上述错误信息并不容易。
经验之一:从日志文件最后部分查起,并找到发生该错误的起始时间,再往下查询。经验之二:重点查找“Error”、“Failed”等关键词,根据这些关键词所在的信息去Metalink进行搜索。再次重复该问题的错误信息:“Execution Error : failed waiting for completion of ocr configuration with CLSCFG”。
Metalink是个浩瀚的知识海洋,但我们要学会正确、高效的检索方法。
更严重的问题:RAC频繁宕机!
相比前面两个问题,该项目发生的更严重问题是:投产之后,RAC的一个节点频繁宕机。该问题不仅现象严重,而且原因复杂,困扰我们好长时间,最后不得不求助于Oracle全球技术支持中心。但最终还是我们自己找到了问题的症结,并得到彻底解决。以下就是详细过程:
- 故障现象
该系统在投产之后第一天上午,客户突然反映应用程序连接不到第一个节点,我上去先通过crs_stat –t查询系统状态,果然发现第一个节点的ons、listener、数据库实例等状态为offline了。于是赶紧查询crsd.log日志,相关信息显示如下:
2012-10-23 02:04:13.452: [ CRSAPP][7404]32CheckResource error for ora.tjjm1.ons error code = 1 2012-10-23 02:04:13.452: [ CRSRES][7404]32In stateChanged, ora.tjjm1.ons target is ONLINE 2012-10-23 02:04:13.467: [ CRSRES][7404]32ora.tjjm1.ons on tjjm1 went OFFLINE unexpectedly 2012-10-23 02:04:13.467: [ CRSRES][7404]32StopResource: setting CLI values 2012-10-23 02:04:13.811: [ CRSRES][7404]32Attempting to stop `ora.tjjm1.ons` on member `tjjm1` 2012-10-23 02:04:56.305: [ CRSRES][7404]32Stop of `ora.tjjm1.ons` on member `tjjm1` succeeded. 2012-10-23 02:04:56.305: [ CRSRES][7404]32ora.tjjm1.ons RESTART_COUNT=0 RESTART_ATTEMPTS=3 2012-10-23 02:04:56.305: [ CRSRES][7404]32Restarting ora.tjjm1.ons on tjjm1 2012-10-23 02:04:56.461: [ CRSRES][7404]32startRunnable: setting CLI values 2012-10-23 02:04:56.461: [ CRSRES][7404]32Attempting to start `ora.tjjm1.ons` on member `tjjm1` 2012-10-23 02:05:55.196: [ CRSAPP][7404]32StartResource error for ora.tjjm1.ons error code = 1 2012-10-23 02:06:28.315: [ CRSRES][7404]32Start of `ora.tjjm1.ons` on member `tjjm1` failed. 2012-10-23 02:06:28.408: [ CRSRES][7404]32ora.tjjm1.ons failed on tjjm1 relocating. 2012-10-23 02:06:28.564: [ CRSRES][7404]32Cannot relocate ora.tjjm1.onsStopping dependents 2012-10-23 02:06:28.580: [ CRSRES][7404]32StopResource: setting CLI values 2012-10-23 02:18:35.794: [ CRSAPP][2732]32CheckResource error for ora.tjjm1.LISTENER_TJJM1.lsnr error code = 1 2012-10-23 02:18:35.810: [ CRSRES][2732]32In stateChanged, ora.tjjm1.LISTENER_TJJM1.lsnr target is ONLINE 2012-10-23 02:18:35.810: [ CRSRES][2732]32ora.tjjm1.LISTENER_TJJM1.lsnr on tjjm1 went OFFLINE unexpectedly 2012-10-23 02:18:35.810: [ CRSRES][2732]32StopResource: setting CLI values 2012-10-23 02:18:35.934: [ CRSRES][2732]32Attempting to stop `ora.tjjm1.LISTENER_TJJM1.lsnr` on member `tjjm1` 2012-10-23 02:20:58.161: [ CRSRES][2732]32Stop of `ora.tjjm1.LISTENER_TJJM1.lsnr` on member `tjjm1` succeeded. 2012-10-23 02:20:58.161: [ CRSRES][2732]32ora.tjjm1.LISTENER_TJJM1.lsnr RESTART_COUNT=0 RESTART_ATTEMPTS=5 2012-10-23 02:20:58.161: [ CRSRES][2732]32Restarting ora.tjjm1.LISTENER_TJJM1.lsnr on tjjm1 2012-10-23 02:20:58.426: [ CRSRES][2732]32startRunnable: setting CLI values 2012-10-23 02:20:58.426: [ CRSRES][2732]32Attempting to start `ora.tjjm1.LISTENER_TJJM1.lsnr` on member `tjjm1` 2012-10-23 02:22:39.468: [ CRSAPP][2732]32StartResource error for ora.tjjm1.LISTENER_TJJM1.lsnr error code = 1 2012-10-23 02:25:01.475: [ CRSRES][2732]32Start of `ora.tjjm1.LISTENER_TJJM1.lsnr` on member `tjjm1` failed. 2012-10-23 02:25:01.663: [ CRSRES][2732]32ora.tjjm1.LISTENER_TJJM1.lsnr failed on tjjm1 relocating. 2012-10-23 02:25:01.741: [ CRSRES][2732]32Cannot relocate ora.tjjm1.LISTENER_TJJM1.lsnrStopping dependents 2012-10-23 02:25:01.756: [ CRSRES][2732]32StopResource: setting CLI values 2012-10-23 09:35:27.166: [ CRSRES][8028]32In stateChanged, ora.tjcshow.tjcshow1.inst target is ONLINE 2012-10-23 09:35:27.166: [ CRSRES][8028]32ora.tjcshow.tjcshow1.inst on tjjm1 went OFFLINE unexpectedly 2012-10-23 09:35:27.166: [ CRSRES][8028]32StopResource: setting CLI values 2012-10-23 09:35:27.400: [ CRSRES][8028]32Attempting to stop `ora.tjcshow.tjcshow1.inst` on member `tjjm1` 2012-10-23 09:39:57.875: [ CRSAPP][8028]32StopResource error for ora.tjcshow.tjcshow1.inst error code = 1 2012-10-23 09:39:58.015: [ CRSRES][8028][ALERT]32`ora.tjcshow.tjcshow1.inst` on member `tjjm1` has experienced an unrecoverable failure. 2012-10-23 09:39:58.015: [ CRSRES][8028]32Human intervention required to resume its availability. 2012-10-23 09:39:58.015: [ CRSRES][8028]32Resource failed into UNKNOWN, killing dependents 2012-10-23 09:39:58.015: [ CRSRES][8028]32ora.tjcshow.tjcshow1.inst experienced a failure ontjjm1. Stopping dependent resources. 2012-10-23 09:39:58.015: [ CRSRES][8028]32StopResource: setting CLI values 2012-10-23 09:39:58.015: [ CRSRES][8028]32Attempting to stop `ora.tjcshow.tjcshow1.inst` on member `tjjm1` 2012-10-23 09:41:59.914: [ CRSRES][8028]32Stop of `ora.tjcshow.tjcshow1.inst` on member `tjjm1` succeeded. 2012-10-23 09:57:34.360: [ CRSRES][5104]32CRS-1002: 资源 'ora.oracle2.db' 已在成员 'tjjm1' 上运行
上述日志信息表示,在2012-10-23 02:04:13.452开始,CRS检测出ora.tjjm1.ons服务状态错误,并异常宕机了。虽然经过几次重新启动,但依然失败了。然后,ora.tjjm1.LISTENER_TJJM1.lsnr监听服务和数据库实例ora.tjcshow.tjcshow1.inst均相继宕机,并且重起失败。
- 艰难的故障原因分析
是什么原因导致上述严重问题呢?我们马上检查了网络私网、交换机等硬件环境,一切正常。一时查不到原因,毕竟是已经投产的生产系统,时间紧迫,压力颇大。为加快问题解决,我们赶紧在Metalink创建了SR 3-6353478671,希望Oracle全球技术支持中心专家能与我们同步分析问题原因所在。
于是,象通常的SR处理流程一样,我们主动将crsd.log、ons.log等一大堆日志和配置文件都上传到SR中。但Oracle后台专家也一时一头雾水,只好让我们再设置相关跟踪标志,等待下次故障再次重现时,捕获更多信息。例如:
Please do the following the debug the ons - set ons tracing with crsctl debug log res "ora.tjjm1.ons:5" - change the loglevel in $CRS_HOME/opmn/conf/ons.config on both nodes to loglevel=9 - setup OSWatcher We need the output of the OSWatcher to monitor the OS resources and network statistics.
我的妈呀,又是设置ons的debug级别,又是设置ons日志级别,还要OSWatcher信息,Oracle后台专家自己把自己陷入信息的海洋了,呵呵。
Oracle后台专家毕竟不在现场,需要各种日志诊断信息的确正常。但我们自己在现场更熟悉情况,应该能更有效地抓取真正对问题诊断有价值的信息。
我突然想起来,应该查一下Windows的事件查看器,看看在2012-10-23 02:00前后系统有没有报什么错误信息,果然发现操作系统报了一个Event ID = 5719的错误。这是什么错误呢?于是,只好去微软的站点去查询了。客户系统管理员真给力,很快就查到微软一篇讲述Event ID = 5719的官方文章:http://support.microsoft.com/kb/310339。客户按照该文章给出的解决方案,将注册表中的一个参数MaxDgramBuffering扩大了,但仍然没有解决问题。
眼看要前功尽弃了。怎么办?于是我们再次分析微软的官方文章,仔细研究Event ID = 5719的如下错误原因:
No Windows NT or Windows 2000 Domain Controller is available for domain<domain name>. The following error occurred:
There are currently no logon servers available to service the logon request.
原来该错误与Windows的Domain Controller有关。再结合我们自己做过的工作,哦,突然想起来了!我们在安装RAC时,当时administrator用户并不在Windows Domain里,我们是以standalone方式安装的,安装之后才将administrator用户加入到Domain中的。RAC运行之后,一定是CRS需要与Windows Domain进行通信,但我们初始安装时并没有在Domain中进行相应的配置,所以通信失败,报错了。
- 解决办法
问题基本定位了,解决办法就简单了。由于已经投产,我们已经无法再重新安装系统了,于是只好将administrator用户退出Domain,将 RAC运行在最初安装时的状态。果然,之后再也没有出现Event ID = 5719错误了,更没有出现RAC的异常宕机了。
最后,我们将自己的分析结果和处理情况向Oracle后台专家沟通之后,也得到了专家的肯定。
- 经验和体会
各位看了上述叙述,一定感受到该问题的复杂性,涉及操作系统、数据库等多个层面。其实由于书的篇幅所限,我们并没有在书中展开ons、listener等更多的日志和配置信息。当时我们在这些信息中查找问题的蛛丝马迹,真的非常辛苦。值得总结的经验有:
- 还是要有分析问题的正确方法和思路。针对RAC问题,首先应通过‘crs_stat –t’去分析各服务的状态,然后应分析log日志信息,再查询ons等更细节的相关日志信息。
- 分析问题要全面。此故障的突破点就是查询了Windows的系统日志,特别针对RAC问题,一定要查询系统日志。
- 学会看日志文件。很多客户都不太愿意下功夫去仔细研究日志文件,其实看懂日志不仅是一门学问,而且是一个享受的过程。据说,Oracle很多后台专家就把研读日志文件作为一种享受。说实在的,读日志文件真有破案一样顺藤摸瓜的成就感。呵呵。
通过Meatalink的SR,借助Oracle后台专家的力量。虽然本故障最终是我们自己分析出原因并加以解决的,但Oracle后台专家在SR中还是给出了很多分析问题的思路和收集错误信息的方法,值得我们日后借鉴。
没完没了的收集数据
某日,作为服务解决方案顾问,为全面了解某大型国有银行客户对Oracle的使用情况,从而提出更有针对性的服务方案,本人通过Oracle一个后台系统对该客户在metalink中过去一年提交的SR(Service Requeset,服务请求)进行统计分析,分析的内容包括客户提交的各类SR 数量、 SR平均处理时长、Bug和非 Bug统计分析、按产品的SR分类统计等。
以下就是该客户2012年全年的1级问题处理时长统计分析图:
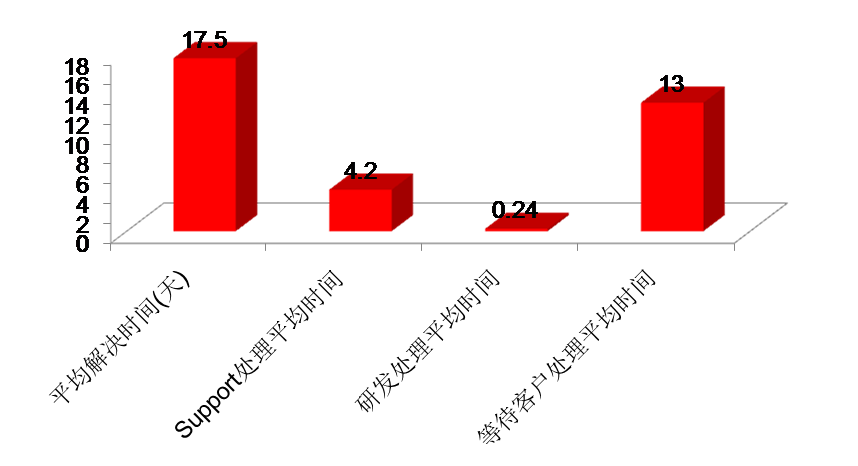
按照Oracle公司官方定义,1级问题是最严重的问题,包括数据库宕机、关键业务数据丢失等严重问题。从上述统计图可看出,该客户的1级问题平均解决时间达到了17.5天!难怪乎客户运维老总看到这组数字时,心惊肉跳地说:“幸亏去年的1级问题并不是导致业务彻底中断的真正1级问题,否则宕机17.5天,我的乌纱帽早就没了!”呵呵。
但大家通过仔细分析后发现,其实在17.5天中,等待客户处理的平均时间达到13天,也就是说Oracle公司包括Oracle Support部门和研发部门负责处理、需要承担责任的时间只有4天多,而主要责任在客户自己。客户需要在问题处理过程中承担什么责任呢?
在国内客户中,很多人提交SR之后,就以为万事大吉,坐等Oracle专家的灵丹妙药了。其实,Oracle专家也不是神仙,解决问题也有个逐步深入的过程,需要不断了解你的系统,甚至期待问题再次爆发,才能抓取更多信息,逐步定位问题并提供正确的解决方案。
在SR中有一个状态信息。分别表示该SR在等待Oracle Support工程师、Oracle研发团队进行处理,还是等待客户处理的状态。其中等待客户处理状态包括:CUS(等待客户回应)、WCP(等客户打补丁)、SLP(休眠,等待客户再启动)、LMS(留话/讯息)等。
在客户承担的责任中,一个重要工作就是负责收集和上传相关系统环境和出错信息,而为了得到这些信息,Oracle常见诊断工具的使用是必不可少的,例如RDA、AWR、OSWatch、DiagCollection等。该银行客户的SR等待客户处理平均时间达到13天,说明该客户一定不是非常熟悉这些工具的使用。也有另一种可能性:信息收集不全,或者Oracle Support工程师自身也缺乏经验,没有指导客户一次性收集全相关数据。于是,一遍又一遍、没完没了地收集数据,Oracle Suppot工程师就是给不出一个问题原因分析和解决建议,让该客户苦不堪言。
排除Oracle Support工程师自身原因,我们客户如何全面了解Oracle数据库常见诊断工具,特别是在故障发生时能主动、全面提供相关信息,无疑是提高故障处理效率的有效途径。凡事从自身做起,求人不如求自己。
下面就将介绍相关的Oracle数据库常见诊断工具的基本使用方法。
数据库常见诊断工具
RDA
RDA(Remote Diagnostic Agent)是Oracle Support部门为进行故障诊断分析,快速全面了解Oracle运行环境而提供的分析工具。RDA将采集硬件、操作系统、网络、数据库等各个层面的信息,RDA采集的信息将会为问题问题和故障诊断提供有力的帮助。
RDA工具只会查询Oracle运行环境的各类信息,不会去调整任何配置信息,因此不会对现有环境造成任何影响。
RDA支持各种主流平台,以及Oracle的数据库、RAC、ASM、Data Guard、Oracle应用服务器、ERP等各类产品。RDA的详细情况,请见RDA的最新文档:《Remote Diagnostic Agent (RDA) – Getting Started (Doc ID 314422.1)》。
- 安装RDA
- 在服务器上创建一个RDA目录,并保证有足够的空间。
- 将RDA压缩文件(tar or rda.tar.gz file)FTP到该目录。
- 解压RDA压缩文件。例如:
tar xvf rda.tar 或 gunzip rda.tar.gz tar xvf rda.tar
- 确保RDA相关命令的执行权限:
chmod +x <rda>
- 运行RDA及产生RDA报告
- 以Oracle用户,执行如下命令,进行初始的配置选择,确定信息采集范围:
$ ./rda.sh -S
- 以Oracle用户,执行如下命令:
$ ./rda.sh
- RDA产生的报告位于RDA output目录下,并以HTML文件形式存储。通过<output_directory>/<report_group>__start.htm可浏览RDA的相关内容。
- RDA产生的所有报告以压缩文件打包形式位于RDA output目录下,例如.zip, .tar, .tar.gz, 或 .tar.Z等后缀形式。如果RDA报告是针对某个具体的SR,请将该压缩文件上传到metalink的相关SR。
以下就是某系统RDA报告的首页:
建议在发生具体问题时,在Oracle Support要求和指导下,从metalink下载最新的RDA工具和ReadMe文档,运行RDA工具,并将相关RDA报告上传。
AWR
AWR(Automactic Workload Repository)是Oracle 10g的新特性之一。通过AWR,Oracle可自动采集、维护和使用数据库运行的相关统计信息,进行问题诊断和自我调整。
- Workload Repository的产生
缺省情况下,Oracle 10g每隔一个小时自动产生一个快照。通过如下命令可设置自动产生快照的频度:
SQL> EXEC DBMS_WORKLOAD_REPOSITORY.MODIFY_SNAPSHOT_SETTINGS(interval => 30);
如果设置interval为0,则系统将不自动产生快照。
通过如下命令,可手工产生快照:
SQL> EXEC DBMS_WORKLOAD_REPOSITORY.CREATE_SNAPSHOT;
- AWR报告的产生
通过如下脚本,并选择文件输出格式为文本或HTML、快照天数、起始快照号和结束快照号等信息,将产生需要的AWR报告。
SQL>?/rdbms/admin/awrrpt.sql
- AWR报告的分析
AWR报告包括了数据库运行的各个层面的大量信息,有效地利用AWR报告分析数据库运行状态以及进行故障诊断,是一项既需要扎实的数据库基础知识,又需要经验不断积累的过程。相关建议如下:
- 先看系统整体状态,例如:Load Profile、Instance Efficiency Percentages、Top 5 Timed Events
- 在RAC情况下,特别需要关注RAC Statistics中的Global Cache Load Profile、Global Cache Efficiency Percentages、Global Cache and Enqueue Services – Workload Characteristics、Global Cache and Enqueue Services – Messaging Statistics 等部分指标信息的变化情况。
- 重点对Top-N SQL的质量进行分析。根据时间消耗、内存消耗、物理I/O等排序情况,对相关SQL语句进行执行计划分析等质量评估。
- 对SGA的各种Buffer以及PGA等进行分析。
- 通过对表空间、数据文件I/O的分析,对应用软件设计和物理设计进行评估。
- 对Segment的逻辑读、物理读等进行分类分析,以确定系统的瓶颈。特别在RAC情况下,对Segments by Global Cache Buffer Busy、Segments by Current Blocks Received等内容的分析,可确定节点间通信和同步的对象。
- 如果采用service技术,通过对Service Statistics信息的分析,可了解以Service为单位进行的性能指标,特别是系统负载情况分析。
- 对其它可能造成数据库性能瓶颈的一些等待事件、Latch等进行分析。
ADDM
ADDM(Automatic Database Diagnostic Monitor)是Oracle 10g之后内置的自动进行问题分析的工具。ADDM利用Workload Repository存储的快照信息,可分析指定时间段的数据库各种问题。
- ADDM报告的产生
通过如下脚本,选择起始快照号和结束快照号,将产生需要的ADDM报告。
SQL>?/rdbms/admin/addmrpt.sql
- ADDM报告的分析
- ADDM报告将提供系统自动发现的相关问题以及供解决方案
- ADDM将对每类问题的根源进行分析,以及对系统的整体影响率,同时产生相关的优化建议
- ADDM也将对没有问题的领域进行分析,从而避免DBA对该领域做过多的分析,尽可能减少问题分析的时间和付出
同样地,ADDM报告的分析既需要扎实的数据库基础知识,又需要经验不断积累、不断实践。
DiagCollection.pl
Clusterware作为Oracle的集群管理软件,功能的确强大,具有集群管理(Cluster Management)、节点监控(Node Monitoring)、事件服务(Event Services)、时钟同步(Time Synchronization)、网络管理(Network Management)、高可用性(High Availability)等诸多领域的功能,分别涉及CRS、CSS、EVM、CTSS、ONS等不同组件和服务。正因为功能太强大、组件太多,一旦Clusterware出现问题和故障,其诊断和分析过程也够DBA和系统管理员喝一壶的,呵呵。尽管Oracle自称为Clusterware的日志文件设计了一个统一的日志文件目录结构,如下图所示:
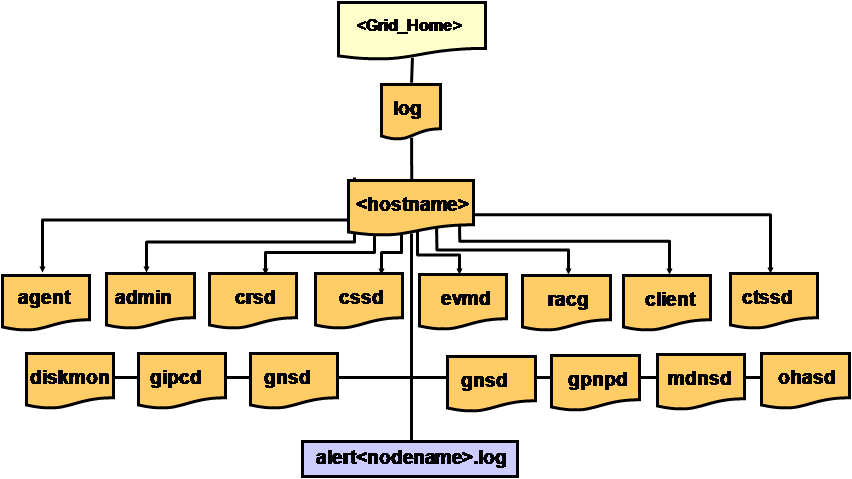
但DBA和系统管理员们从上述纷繁的日志目录结构中快速、准确地找到相关信息,并不是一件轻松的事情。这也是在与Clusterware相关的SR中,Oracle Support专家反复要求客户收集和上传日志信息,导致SR处理时间过长的一个重要原因。
幸亏Oracle 11g提供了一个diagcollection脚本,可以将上述Clusterware 日志统一打包成几个压缩文件,以便客户快速上传给Oracle Support部门,用于Clusterware相关SR 的快速、准确进行问题诊断和分析。相关技术细节如下:
- diagcollection脚本位置
diagcollection脚本(diagcollection.pl)位于<Grid_Home>/bin目录之下,并且必须以root用户进行运行。
- diagcollection脚本示例
以下为diagcollection脚本通过 “collect”选项进行clusterware日志文件收集,并在当前目录下生成4个打包和压缩文件的示例:
# /u01/app/11.2.0/grid/bin/diagcollection.pl --collect Production Copyright 2004, 2008, Oracle. All rights reserved Cluster Ready Services (CRS) diagnostic collection tool The following diagnostic archives will be created in the local directory. crsData_host01_20090729_1013.tar.gz -> logs,traces and cores from CRS home. Note: core files will be packaged only with the --core option. ocrData_host01_20090729_1013.tar.gz -> ocrdump, ocrcheck etc coreData_host01_20090729_1013.tar.gz -> contents of CRS core files osData_host01_20090729_1013.tar.gz -> logs from Operating System ...
- diagcollection脚本其它功能
通过“clean”选项,可以清除当前目录下上次收集的日志文件包:
# /u01/app/11.2.0/grid/bin/diagcollection.pl –clean
通过“colletion”和“crs”选项,只收集和打包与Oracle Clusterware相关的日志:
# /u01/app/11.2.0/grid/bin/diagcollection.pl –collection –crs
通过“colletion”和“core”选项,只收集和打包与core相关的日志:
# /u01/app/11.2.0/grid/bin/diagcollection.pl –collection –core
“–collection –all”将收集所有日志,“–all”是缺省配置。
Dynamic Debugging
以root用户运行如下脚本,可对整个Clusterware,EVM及相关resource动态采集debug信息。
例如,对整个Clusterware动态采集debug信息的命令如下:
crsctl debug log crs “CRSRTI:1,CRSCOMM:2”
对EVM动态采集debug信息的命令如下:
crsctl debug log evm “EVMCOMM:1”
对某个resource动态采集debug信息的命令如下:
crsctl debug log res “resname:1”
建议在发生具体问题时,在Oracle Support要求和指导下,启动debug状态,并将相关日志和debug信息上传。
Component Level Debugging
以root用户运行如下脚本,可对整个CRS daemon,EVM及相关module采集debug信息。
crsctl debug log module_name component:debugging_level
其中:
- debugging_level取值为1到5
- module_name 为crs, evm, or css的模块名。运行如下命令,可得到crs, evm, or css的模块名:
crsctl lsmodules module_name
建议在发生具体问题时,在Oracle Support要求和指导下,启动相关模块的debug状态,并将相关日志和debug信息上传。
RACCheck
- 概述
RACCheck工具全称叫做:RAC Configuration Audit tool,主要用于检查和审计RAC、Clusterware、ASM及GI环境的配置信息。检查和审计的领域包括:操作系统核心参数、操作系统Package、与RAC相关的操作系统其它配置信息、CRS/Grid Infrastructure、RDBMS、ASM、数据库参数、与RAC相关的数据库其它配置信息、11.2.0.3升级就绪评估。
- 什么时候该运行RACCheck工具?
在《RaccheckUserGuide_v2_2_2》手册中,Oracle公司建议在如下几种情况下,应运行RACCheck工具:
- 在RAC首次安装之后。
- 在计划性地进行系统维护之前。例如,修改公网IP、数据库补丁安装等变更操作之前。
- 在计划性地进行系统维护之后。例如,修改公网IP、数据库补丁安装等变更操作之后。
- 每三个月一次。
- 为解决与RAC相关问题,应Oracle Support工程师之建议。
- RACCheck快速指南
以下是RACCheck工具使用的快速指南,RACCheck工具下载方式请见《RACcheck – RAC Configuration Audit Tool (Doc ID 1268927.1)》,详细操作说明请见《RaccheckUserGuide_v2_2_2》。
- 若安装了Oracle产品,则以Oracle RDBMS安装用户登录系统。否则,以root用户进行登录。
- 将zip包上传到需要进行检查的节点的某个目录。
- 解压(Unzip)zip包。
- 确认raccheck的权限为755(-rwxr-xr-x)。否则,执行如下命令:
$ chmod 755 raccheck
- 执行raccheck:
$ ./raccheck
请根据提示回答相关问题,以下是该工具执行的相关片断内容:
CRS stack is running and CRS_HOME is not set. Do you want to set CRS_HOME to /oragi/11.2.0.3/grid?[y/n][y]y Checking ssh user equivalency settings on all nodes in cluster Node ratlnx02 is configured for ssh user equivalency for oracle user Searching for running databases . . . . . List of running databases registered in OCR
-
maadb
-
None
Select respective number to choose database for checking best practices. For multiple databases, select 1 for All or comma separated number like 1,2 etc [1-2][1].1 . . Checking Status of Oracle Software Stack - Clusterware, ASM, RDBMS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ------------------------------------------------------------------------------------------------------- Oracle Stack Status Host Name CRS Installed ASM HOME RDBMS Installed CRS UP ASM UP RDBMS UP DB Instance Name ratlnx01 Yes Yes Yes Yes Yes Yes maadb1 ratlnx02 Yes Yes Yes Yes Yes Yes maadb2 9 of the included audit checks require root privileged data collection . If sudo is not configured or the root password is not available, audit checks which require root privileged data collection can be skipped.
-
Enter 1 if you will enter root password for each host when prompted
-
Enter 2 if you have sudo configured for oracle user to execute root_raccheck.sh script
-
Enter 3 to skip the root privileged collections
-
Enter 4 to exit and work with the SA to configure sudo or to arrange for root access and run the tool later.
Please indicate your selection from one of the above options[1-4][1]:- Note: If you chose option 1, to provide root password when prompted, you will be prompted once for each node during the data collection phase for the nodes (unless expect is installed). If you do not enter the root password in a timely way (within RACCHECK_TIMEOUT) then the root privileged collections and audit checks for that node will be skipped. For functionality of parallel execution of RACcheck on all cluster nodes, the expect utility MUST be installed. For this reason it is highly recommended that the expect utility be installed on the systems. Please indicate your selection from one of the above options[1-4][1]:- 1Is root password same on all nodes?[y/n][y]y Enter root password :- *** Checking Best Practice Recommendations (PASS/WARNING/FAIL) *** Log file for collections and audit checks are at /home/oracle/raccheck/raccheck_120211_112221/raccheck.log . . . . . . . . . . . . . . .
- raccheck工具执行完之后,将显示如下类似内容:
Detailed report (html) – /home/oracle/raccheck/raccheck_ratlnx01_120211_114104/raccheck_ratlnx01_120211_114104.html
UPLOAD(if required) – /home/oracle/raccheck/raccheck_ratlnx01_120211_114104.zip
- 此时,可通过查看raccheck产生的上述html文件,了解RAC环境检查结果。或者将上述zip文件上传到相关SR,提供给Oracle Support工程师进行分析。
10046 event的设置
10046 event的设置等同于设置SQL_TRACE = TRUE,即主要针对存在性能问题的SQL语句收集跟踪信息。与设置SQL_TRACE = TRUE不同的是,设置10046 event时,可根据需要设置不同的跟踪级别,从而收集更详细的信息。例如:
- Level = 1:启动标准的SQL_TRACE功能,该值为缺省值。
- Level = 4:除Level = 1的功能之外,增加对BIND变量值的跟踪分析。
- Level = 8:除Level = 1的功能之外,增加对wait等待事件的跟踪分析,例如对latch wait等待事件的跟踪分析。
在11g中,增加如下Level值:
- Level = 16:针对SQL语句的每次执行过程,产生统计信息(STAT line dumps)
- Level = 32:针对SQL语句的每次执行过程,不产生统计信息。
在11.2.0.2之后,增加如下Level值:
- Level = 64:针对SQL语句的每次执行过程,自适应地产生统计信息。在这种设置下,假设语句执行时间超过1分钟,将产生统计信息。这样,Oracle自动针对资源消耗过大语句的执行过程收集更多统计信息。
在11g中,通过设置SQL_TRACE及选项方式,也可实现过去由设置10046和相关Level的功能。例如:
alter session set events ‘sql_trace wait=false, bind=true’;’
以下就是10046的不同Level值与11g中SQL_TRACE相关选项的对应关系:
| Level | 11g SQL_TRACE的选项 |
| 1 | N/A |
| 4 | bind=true |
| 8 | wait=true |
| 16 | plan_stat=all_executions |
| 32 | plan_stat=never |
| 64 | plan_stat=adaptive |
以下就是一些设置例子,在会话级进行如下设置:
alter session set events ‘10046 trace name context forever’;
alter session set events ‘10046 trace name context forever, level 8’;
alter session set events ‘10046 trace name context off’;
在11g中,针对上述设置可进行如下设置:
alter session set events ‘sql_trace’;
alter session set events ‘sql_trace wait=true’;
alter session set events ‘sql_trace off”;
在初始化参数中,可进行如下设置:
event=”10046 trace name context forever,level 4″
此时Oracle将对所有会话的SQL语句进行跟踪信息收集,因此建议谨慎为之,避免系统产生大量无用的跟踪信息。
在设置10046事件或SQL_TRACE=TRUE之后,系统将在udump目录产生相应的Trace文件。通常,Trace文件是上传给SR,供Oracle Support工程师分析的。若我们自己要分析Trace文件,则需要在相关文档的帮助下方能读懂。有兴趣的读者请参考《Interpreting Raw SQL_TRACE output (Doc ID 39817.1)》,本人就不在这里堆积这么晦涩难懂的东西了。呵呵。
数据库挂起(HANG)诊断信息的收集
可怕的数据库Hang
“数据库Hang住了,连 sqlplus 都进不去了!”这是数据库运行过程中,比较常见、也是比较难于处理的一类故障。
根据Oracle官方的解释,所谓数据库挂起(Hang),通常而言是因为某些进程可能正在非常繁忙地工作而没有释放相关资源,而其它进程被迫处于等待之中。其实导致数据库Hang的原因多种多样:某些应用性能差,把资源耗尽,可能导致数据库Hang;归档日志文件区满,会导致数据库Hang;NFS服务器宕机,或者连接NFS服务器的网络中断,将导致包括Oracle数据库在内的应用都出现Hang;Oracle数据库软件本身的Bug可能导致Hang… …。而且,数据库Hang与数据库运行缓慢并不是同一回事。
本节、本章,甚至本书都无法穷尽各种数据库Hang的故障及解决办法,但就像看病先要进行各种诊断一样,本节我们重点介绍数据库出现Hang时,如何进行诊断信息的收集。虽然下面介绍的一些诊断信息的获取,并不一定马上就能找到Hang的根源,但这些诊断信息不仅有助于问题的分析,而且至少能帮助我们排除一些问题原因,例如是不是应用问题,甚至帮我们避免类似问题的再次发生。
Hanganalyze和Systemstate Dumps信息的收集
Oracle公司建议针对数据库Hang,从如下三个方面进行信息的收集:
- Hanganalyze和Systemstate Dumps
- AWR/Statspack
- RDA
AWR/Statspack、RDA就不赘述了。以下重点介绍Hanganalyze和Systemstate Dumps信息的收集。
Hanganalyze和Systemstate Dumps都可在指定时间段内提供数据库进程的相关信息。Hanganalyze用于判断数据库是处于Hang状态,还是运行时间很慢,并收集处于 Hang状态中的进程信息。而Systemstate Dumps则针对数据库所有进程进行信息的收集。
为收集Hanganalyze和Systemstate Dumps信息,首先需以如下方式连接到Oracle:
sqlplus ‘/ as sysdba’
如果无法登录10gR2以上版本,则尝试如下的preliminary方式登录:
sqlplus –prelim ‘/ as sysdba’
实际上,preliminary方式并没有创建Session,仅仅是连接到数据库,但能有限制地访问SGA等,从而收集Systemstate Dumps等诊断信息。
需要说明的是,在11.2.0.2以上版本,如果以preliminary方式登录系统,由于Hanganalyze需要进程状态对象和Session状态对象,而如上所述,preliminary方式并没有创建Session,因此,并不能收集到Hanganalyze信息,并报如下错误:
HANG ANALYSIS:
ERROR: Can not perform hang analysis dump without a process state object and a session state object.
( process=(nil), sess=(nil) )
在单机情况下,当数据库出现Hang或运行特别缓慢时,按如下方式进行Hanganalyze信息的收集:
sqlplus ‘/ as sysdba’
oradebug setmypid
oradebug unlimit
oradebug hanganalyze 3
— 收集第二个hanganalyze信息之前,等待至少1分钟
oradebug hanganalyze 3
oradebug tracefile_name
exit
按如下方式进行Systemstate Dumps信息的收集:
sqlplus ‘/ as sysdba’
oradebug setmypid
oradebug unlimit
oradebug dump systemstate 266
oradebug dump systemstate 266
oradebug tracefile_name
exit
在RAC环境下,首先有两如下两个Bug与Hanganalyze和Systemstate Dumps信息收集相关,这两个Bug会导致level 266或267的收集工作非常缓慢:
Document 11800959.8 Bug 11800959 – A SYSTEMSTATE dump with level >= 10 in RAC dumps huge BUSY GLOBAL CACHE ELEMENTS – can hang/crash instances
Document 11827088.8 Bug 11827088 – Latch ‘gc element’ contention, LMHB terminates the instance
因此,强烈建议先检查是否安装这两个Bug的补丁。如果安装了这两个补丁,则以如下方式进行Hanganalyze和Systemstate Dumps信息收集:
sqlplus ‘/ as sysdba’
oradebug setorapname reco
oradebug unlimit
oradebug -g all hanganalyze 3
oradebug -g all hanganalyze 3
oradebug -g all dump systemstate 266
oradebug -g all dump systemstate 266
exit
如果没有安装这两个补丁,则以如下方式进行Hanganalyze和Systemstate Dumps信息收集:
sqlplus ‘/ as sysdba’
oradebug setorapname reco
oradebug unlimit
oradebug -g all hanganalyze 3
oradebug -g all hanganalyze 3
oradebug -g all dump systemstate 258
oradebug -g all dump systemstate 258
exit
在RAC环境下,将在每个实例的DIAG跟踪文件中产生相应的dump信息。
上述Hanganalyze的level设置成 3,表示在11g以上版本中,只针对被 Hang住的进程收集short stack信息。
Systemstate Dumps的level设置成258,表示一种快速收集方式,并可能丢失某些锁的信息。而Systemstate Dumps的level设置成266,则将收集更多信息,包括缓冲区、锁等信息。
11g的v$wait_chains
从11g开始,Oracle的后台进程dia0开始收集hanganalyze信息,并保存在所谓的“hang analysis cache”中,也就是v$wait_chains动态视图中。dia0每隔3秒采集本地实例的hanganalyze信息,每隔10秒采集Global,也就是RAC的hanganalyze信息。
这些信息对数据库出现Hang和资源竞争的诊断分析非常有用,Oracle内部很多工具也在运用这些信息,包括:Hang Management, Resource Manager Idle Blocker Kill, SQL Tune Hang Avoidance和PMON cleanup等。同样地,一些诸如Procwatcher的外部工具也在运用运用这些信息。
以下就是v$wait_chains视图的结构:
SQL> desc v$wait_chains Name Null? Type ----------------------------------------- -------- ---------------------- CHAIN_ID NUMBER CHAIN_IS_CYCLE VARCHAR2(5) CHAIN_SIGNATURE VARCHAR2(801) CHAIN_SIGNATURE_HASH NUMBER INSTANCE NUMBER OSID VARCHAR2(25) PID NUMBER SID NUMBER SESS_SERIAL# NUMBER BLOCKER_IS_VALID VARCHAR2(5) BLOCKER_INSTANCE NUMBER BLOCKER_OSID VARCHAR2(25) BLOCKER_PID NUMBER BLOCKER_SID NUMBER BLOCKER_SESS_SERIAL# NUMBER BLOCKER_CHAIN_ID NUMBER IN_WAIT VARCHAR2(5) TIME_SINCE_LAST_WAIT_SECS NUMBER WAIT_ID NUMBER WAIT_EVENT NUMBER WAIT_EVENT_TEXT VARCHAR2(64) P1 NUMBER P1_TEXT VARCHAR2(64) P2 NUMBER P2_TEXT VARCHAR2(64) P3 NUMBER P3_TEXT VARCHAR2(64) IN_WAIT_SECS NUMBER TIME_REMAINING_SECS NUMBER NUM_WAITERS NUMBER ROW_WAIT_OBJ# NUMBER ROW_WAIT_FILE# NUMBER ROW_WAIT_BLOCK# NUMBER ROW_WAIT_ROW# NUMBER
Oracle没有提供gv$wait_chains视图,因为 v$wait_chains已经包含了RAC环境下多实例的信息。
以下是一个简单查询的例子:
SQL> SELECT chain_id, num_waiters, in_wait_secs, osid, blocker_osid, substr(wait_event_text,1,30) FROM v$wait_chains; 2 CHAIN_ID NUM_WAITERS IN_WAIT_SECS OSID BLOCKER_OSID SUBSTR(WAIT_EVENT_TEXT,1,30) ---------- ----------- ------------ ------------------------- ------------------------- ------------------------------ 1 0 10198 21045 21044 enq: TX - row lock contention 1 1 10214 21044 SQL*Net message from client
以下是查询前100个Hang chain进程的脚本:
set pages 1000 set lines 120 set heading off column w_proc format a50 tru column instance format a20 tru column inst format a28 tru column wait_event format a50 tru column p1 format a16 tru column p2 format a16 tru column p3 format a15 tru column Seconds format a50 tru column sincelw format a50 tru column blocker_proc format a50 tru column waiters format a50 tru column chain_signature format a100 wra column blocker_chain format a100 wra SELECT * FROM (SELECT 'Current Process: '||osid W_PROC, 'SID '||i.instance_name INSTANCE, 'INST #: '||instance INST,'Blocking Process: '||decode(blocker_osid,null,'<none>',blocker_osid)|| ' from Instance '||blocker_instance BLOCKER_PROC,'Number of waiters: '||num_waiters waiters, 'Wait Event: ' ||wait_event_text wait_event, 'P1: '||p1 p1, 'P2: '||p2 p2, 'P3: '||p3 p3, 'Seconds in Wait: '||in_wait_secs Seconds, 'Seconds Since Last Wait: '||time_since_last_wait_secs sincelw, 'Wait Chain: '||chain_id ||': '||chain_signature chain_signature,'Blocking Wait Chain: '||decode(blocker_chain_id,null, '<none>',blocker_chain_id) blocker_chain FROM v$wait_chains wc, v$instance i WHERE wc.instance = i.instance_number (+) AND ( num_waiters > 0 OR ( blocker_osid IS NOT NULL AND in_wait_secs > 10 ) ) ORDER BY chain_id, num_waiters DESC) WHERE ROWNUM < 101;
以下是上述脚本的一个范例:
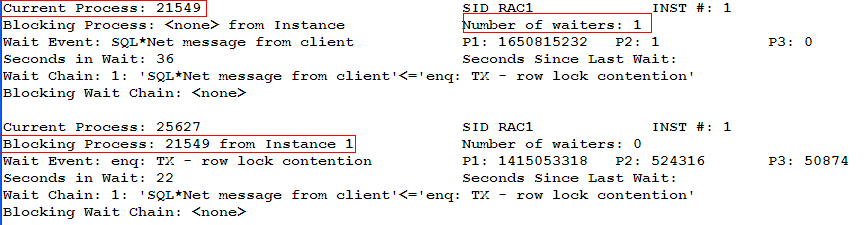
该范例表示进程25627正处于TX行级锁等待,并被进程21549锁住,而21549处于空闲等待“SQL*Net message from client”事件之中,也就是等待应用提供信息或处于网络等待之中。
在11.2以上版本中,在v$session视图中增加了一个字段:final_blocking_session,该字段表示在hang等待链中的根进程。例如,如下脚本可查询出final_blocking_session:
set pages 1000 set lines 120 set heading off column w_proc format a50 tru column instance format a20 tru column inst format a28 tru column wait_event format a50 tru column p1 format a16 tru column p2 format a16 tru column p3 format a15 tru column Seconds format a50 tru column sincelw format a50 tru column blocker_proc format a50 tru column fblocker_proc format a50 tru column waiters format a50 tru column chain_signature format a100 wra column blocker_chain format a100 wra SELECT * FROM (SELECT 'Current Process: '||osid W_PROC, 'SID '||i.instance_name INSTANCE, 'INST #: '||instance INST,'Blocking Process: '||decode(blocker_osid,null,'<none>',blocker_osid)|| ' from Instance '||blocker_instance BLOCKER_PROC, 'Number of waiters: '||num_waiters waiters, 'Final Blocking Process: '||decode(p.spid,null,'<none>', p.spid)||' from Instance '||s.final_blocking_instance FBLOCKER_PROC, 'Program: '||p.program image, 'Wait Event: ' ||wait_event_text wait_event, 'P1: '||wc.p1 p1, 'P2: '||wc.p2 p2, 'P3: '||wc.p3 p3, 'Seconds in Wait: '||in_wait_secs Seconds, 'Seconds Since Last Wait: '||time_since_last_wait_secs sincelw, 'Wait Chain: '||chain_id ||': '||chain_signature chain_signature,'Blocking Wait Chain: '||decode(blocker_chain_id,null, '<none>',blocker_chain_id) blocker_chain FROM v$wait_chains wc, gv$session s, gv$session bs, gv$instance i, gv$process p WHERE wc.instance = i.instance_number (+) AND (wc.instance = s.inst_id (+) and wc.sid = s.sid (+) and wc.sess_serial# = s.serial# (+)) AND (s.final_blocking_instance = bs.inst_id (+) and s.final_blocking_session = bs.sid (+)) AND (bs.inst_id = p.inst_id (+) and bs.paddr = p.addr (+)) AND ( num_waiters > 0 OR ( blocker_osid IS NOT NULL AND in_wait_secs > 10 ) ) ORDER BY chain_id, num_waiters DESC) WHERE ROWNUM < 101;
以下是上述脚本的一个范例:
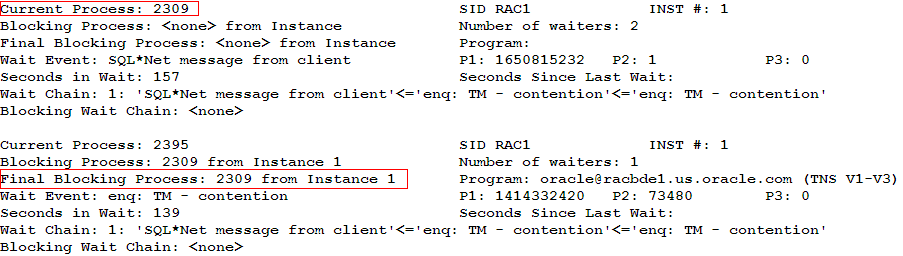
可见,进程号2309是hang等待链中的根进程,杀掉该进程将解除该hang等待链。
主动进行Hang信息收集的方法
在很多情况下,当Hang发生时,DBA已经难于捕获相关诊断信息,如下一些主动进行Hang信息收集的方法值得一试:
- HANGFG script
与上述手工收集Hanganalyze信息不同的是,HANGFG是Oracle提供的一套自动进行Hanganalyze信息收集的脚本。HANGFG的详细情况请见Oracle文档:《Document 362094.1 HANGFG User Guide》
- LTOM
LTOM(The Lite Onboard Monitor)是Oracle提供的一个基于Java的实时信息诊断程序,并部署于客户端,LTOM以主动方式、自动地进行实时问题诊断和数据手机。HANGFG的详细情况请见Oracle文档:《Document 352363.1 LTOM – The On-Board Monitor User Guide》
- Procwatcher
Procwatcher是Oracle提供的一个用于定期检查和监控数据库和Clusterware进程的工具。如下Oracle文档详细介绍了Procwatcher及在故障诊断中的运用:
《Document 459694.1 Procwatcher: Script to Monitor and Examine Oracle DB and Clusterware Processes》
《Document 1352623.1 How To Troubleshoot Database Contention With Procwatcher》
- OS Watcher Black Box
OS Watcher Black Box是Oracle提供的一个用于自动进行 CPU、内存、I/O和网络数据采集和分析的工具。当数据库出现问题包括Hang时,该工具可在操作系统层面进行分析,并且开销很低,因此, Oracle建议尽量安装并运行该工具。OS Watcher Black Box的详细情况请见Oracle文档:《Document 301137.1 OSWatcher Black Box User Guide (Includes: [Video])》。
一些“自主知识产权”脚本
罗老师神秘的脚本
N年之前,我与一位第三方公司的同行一同在客户现场进行工作,由于每次我都运用自己编写的一些脚本进行问题分析和诊断,并且效果不错,引得他已经“觊觎”了很长时间。这天,他终于忍不住,对我提出如下要求:
“罗老师,能不能把你一些神秘的脚本发给我一下?”,他语气中带有点哀求。
“对不起,我这可是自有知识产权的,不能随便给人。”我和他调侃道。
看他一脸的失望,我又继续认真地解释道:“我这些脚本都很个性化,很凌乱,没有好好梳理,也没有什么注释,可能只有我自己才能看得懂。”但是,那次我还是非常仗义地将部分脚本,特别将容易看得懂的脚本,甚至加了若干注释之后发给了他,希望对他日后的工作有所帮助。
我的脚本从何如来?一方面是自己在学习和研究Oracle一些专题技术时,随时将相关命令和脚本整理成一个个文件。另一方面,也是在实际工作中,不仅自己编写了很多实用的脚本,也从Metalink、其它Oracle站点、网上论坛、其他同事,甚至客户那儿吸收了不少。于是,分门别类地就有了有关性能优化、故障诊断、分区、备份恢复、并行处理、10g、11g、12c、ASM、Clusterware、表在线重定义、Flashback、快速增量备份、压缩、坏块处理、DUL、碎片处理、健康检查、资源管理、TimesTen、GoldenGate等林林总总的脚本文件。其实,大家一看就知道,虽然有了分类,但未必科学合理。不过,在很多情况下,毕竟是自己梳理的,找起来非常方便,还非常实用,最终也解决了很多实际问题。
在此也建议读者自己也养成一个良好习惯,那就是在学习和工作中随时进行积累,日积月累地反复总结和提高,我们都会成为技术高手和专家的。只要功夫深,铁杵也能磨成针。
今天,也借写作此书的机会,将我这些“自主知识产权”的东西进行进一步的梳理,限于篇幅,摘取部分常用脚本奉献给诸位。
数据库空间使用情况脚本
/*+ 数据库总使用空间 */ select sum(bytes)/(1024*1024*1024) from dba_data_files; /*+ 数据库空闲空间 */ select sum(bytes)/(1024*1024*1024) from dba_free_space; /*+ 按表空间显示的使用空间 */ select tablespace_name,sum(bytes)/(1024*1024) from dba_data_files group by tablespace_name order by 1; /*+ 按表空间显示的空闲空间 */ select tablespace_name,sum(bytes)/(1024*1024) Free_M from dba_free_space group by tablespace_name order by 1 ; /*+ 按表空间显示的空间使用率 */ SELECT a.tablespace_name, sum(a.avail) "Total(Mb)", sum(nvl(b.free,0)) "Free(Mb)", nvl(round(((sum(nvl(b.free,0))/sum(a.avail))*100),2),0) "Free%" from (select tablespace_name, substr(file_name,1,45) file_name, file_id, round(sum(bytes/(1024*1024)),3) avail from sys.dba_data_files group by tablespace_name, substr(file_name,1,45), file_id) a, (select tablespace_name, file_id, round(sum(bytes/(1024*1024)),3) free from sys.dba_free_space group by tablespace_name, file_id) b where a.file_id = b.file_id (+) group by a.tablespace_name … …
与性能相关的脚本
/*+ 查询当前正在运行的长事务(超过6秒)*/
select sid,sofar,totalwork, opname,target,time_remaining,elapsed_seconds,sql_hash_value
from v$session_Longops
where sofar <> totalwork
order by totalwork desc
/*+ 查询上述长事务的SQL语句文本 */
select * from v$sqltext where HASH_VALUE=3500072035 order by piece;
/*+ 查询所有长事务的SQL语句 */
select distinct hash_value,piece,sql_text from v$sqltext, V$session_Longops order by HASH_VALUE,piece;
/*+ 查询某表的索引设计情况 */
select table_owner,index_name,column_name,column_position from dba_ind_columns where table_name=upper('OP_INJ_WELL_DAILY') order by index_name,column_position;
/*+ 查询某个会话的当前SQL语句 */
select sid,sql_textfrom v$sqltext,v$session where v$sqltext.address=v$session.sql_address and sid=6 order by piece;
/*+ 查询重复分析的SQL语句 */
Select sql_text from v$sqlarea where executions = 1 order by UPPER(sql_text);
… …
与故障诊断相关的脚本
/*+ 查询系统最高的等待事件 */
select * from v$system_event order by total_waits Desc;
/*+ 某个等待事件的当前语句 */
select sql_text
from v$sqlarea
where address in
(select sql_address
from v$session
where sid in (select sid
from v$session_wait
where event like '%db file scattered read%'))
/*+ 查询导致cache buffers chains事件的最热对象 */
select *
from (select c.owner, c.object_name, sum(a.tch)
from x$bh a, v$latch_children b, dba_objects c
where a.hladdr = b.addr
and a.obj = c.object_id
and b.name = 'cache buffers chains'
and c.owner <> 'SYS'
group by c.owner, c.object_name
order by sum(a.tch) desc)
where rownum <= 25;
/*+ 根据PID查询SID */
select a.sid,a.serial#,a.status,a.machine,a.program,a.sql_address,a.command from v$session a,v$process b where
a.paddr=b.addr and b.spid='5926'
/*+ 根据等待事件查询SID信息 */
select a.sid,b.event, b.p1, b.seq#, b.p2, b.p3, substr(a.program, 1, 20) program, substr(a.machine, 1, 10) machine
from v$session a, v$session _wait b
where a.sid = b.sid
and b.event not like 'SQL%'
and b.event not like '%time%'
and b.event not like '%message%'
order by 2
/*+ 根据transaction号查询sid信息 */
select a.sid, a.serial#,a.username,a.status,a.machine,a.program,a.sql_address,a.paddr
from v$session a, v$transaction b
where a.taddr = b.addr
and b.xidsqn = &sqn
/*+ 查询当前SGA使用情况 */
select * from v$sgastat;
/*+ 查询SGA动态分配情况 */
select component,current_size/(1024*1024) from v$sga_dynamic_components;
select * from V$SGA_DYNAMIC_FREE_MEMORY;
/*+ 查询当前PGA的使用情况 */
select * from v$pgastat;
select name, sum(value / (1024 * 1024)) "Value - MB"
from v$statname n, v$session s, v$sesstat t
where s.sid = t.sid
and n.statistic# = t.statistic#
and s.type = 'USER'
and s.username is not NULL
and n.name in ('session pga memory', 'session pga memory max',
'session uga memory', 'session uga memory max')
group by name;
/*+ 按小时统计日志产生量 */
select to_char(FIRST_TIME, 'yyyy-mm-dd hh24'), count(*)
from v$log_history
where thread# = 1
group by to_char(FIRST_TIME, 'yyyy-mm-dd hh24')
order by to_char(FIRST_TIME, 'yyyy-mm-dd hh24');
/*+ 打开trace */
Exec dbms_session.set_sql_trace(True);
/*+ 对某个Session打开Trace */
Exec dbms_session.set_sql_trace_in_session(sid,serial#,True);
… …
与分区相关的脚本
/*+ 查询当前分区表设计总体情况 */
select partitioning_type, subpartitioning_type, count(*)
from dba_part_tables
where owner not in ('SYSTEM', 'SYS', 'GLOBAL', 'SH')
group by partitioning_type, subpartitioning_type;
/*+ 查询当前分区表设计详细情况 */
select *
from dba_tab_partitions
where table_owner not in ('SYSTEM', 'SYS', 'GLOBAL', 'SH')
Order By TABLE_OWNER, TABLE_NAME, PARTITION_NAME;
/*+ 查询当前分区表的分区字段 */
select * from dba_PART_KEY_COLUMNS Where object_type='TABLE' and owner not in ('SYSTEM','SYS','GLOBAL','SH');
/*+ 查询当前分区索引设计总体情况 */
select *
from dba_part_indexes
where owner not in ('SYSTEM', 'SYS', 'GLOBAL', 'SH');
/*+ 查询当前分区索引设计详细情况 */
select *
from dba_ind_partitions
where index_owner not in ('SYSTEM','SYS','GLOBAL','SH')
Order By INDEX_OWNER,INDEX_NAME,PARTITION_NAME,TABLESPACE_NAME
… …
限于篇幅,上述分区脚本没有罗列子分区的脚本,请在上述脚本中进行适当的修改即可,例如dba_tab_partitions修改为dba_tab_subpartitions。详细视图名称请见Oracle相关参考手册。
与RAC相关的脚本
/*+ RAC实例情况 */
select * from gv$active_instances order by inst_id,inst_number,inst_name;
/*+ 分析与GCS有关的等待事件 */
SELECT inst_id, event, p1 FILE_NUMBER, p2 BLOCK_NUMBER, WAIT_TIME
FROM gv$session_wait
WHERE event in (‘buffer busy global cr’, ‘global cache busy’,
‘buffer busy global cache’);
/*+ 一致性读(CR)效率分析,AVG RECEIVE TIME (ms)低于10ms表示一致性读(CR)效率正常 */
SELECT b1.inst_id,
b2.value “RECEIVED”,
b1.value “RECEIVE TIME”,
((b1.value / b2.value) * 10) “AVG RECEIVE TIME (ms)”
FROM gv$sysstat b1, gv$sysstat b2
WHERE b1.name = ‘global cache cr block receive time’
AND b2.name = ‘global cache cr blocks received’
AND b1.inst_id = b2.inst_id;
/*+ 当前块传输(Current Block Transfer)效率分析,AVG RECEIVE TIME (ms)低于15ms表示当前块传输效率正常 */
SELECT b1.inst_id,
b2.value “RECEIVED”,
b1.value “RECEIVE TIME”,
((b1.value / b2.value) * 10) “AVG RECEIVE TIME (ms)”
FROM gv$sysstat b1, gv$sysstat b2
WHERE b1.name = ‘global cache current block receive time’
AND b2.name = ‘global cache current blocks received’
AND b1.inst_id = b2.inst_id;
/*+ 当前块传输(Current Block Transfer)效率分析,AVG RECEIVE TIME (ms)低于15ms表示当前块传输效率正常 */
SELECT b1.inst_id,
b2.value “RECEIVED”,
b1.value “RECEIVE TIME”,
((b1.value / b2.value) * 10) “AVG RECEIVE TIME (ms)”
FROM gv$sysstat b1, gv$sysstat b2
WHERE b1.name = ‘global cache current block receive time’
AND b2.name = ‘global cache current blocks received’
AND b1.inst_id = b2.inst_id;
/*+ 当前块服务(Current Block Service)效率分析,Current Blk Service Time (ms)低于10ms表示当前块服务效率正常 */
SELECT a.inst_id “Instance”,
(a.value + b.value + c.value) / d.value “Current Blk Service Time”
FROM GV$SYSSTAT A, GV$SYSSTAT B, GV$SYSSTAT C, GV$SYSSTAT D
WHERE A.name = ‘global cache current block pin time’
AND B.name = ‘global cache current block flush time’
AND C.name = ‘global cache current block send time’
AND D.name = ‘global cache current blocks served’
AND B.inst_id = A.inst_id
AND C.inst_id = A.inst_id
AND D.inst_id = A.inst_id
ORDER BY a.inst_id;
/*+ 全局缓冲转换和获取(Global Cache Convert and Get)分析,Avg Cache Conv. Time(ms)和Avg Cache Get Time(ms)低于10ms表示全局缓冲转换和获取(Global Cache Convert and Get)效率正常 */
SELECT A.inst_id “Instance”,
A.value / B.value “Avg Cache Conv. Time”,
C.value / D.value “Avg Cache Get Time”,
E.value “GC Convert Timeouts”
FROM GV$SYSSTAT A, GV$SYSSTAT B, GV$SYSSTAT C, GV$SYSSTAT D, GV$SYSSTAT E
WHERE A.name = ‘global cache convert time’
AND B.name = ‘global cache converts’
AND c.name = ‘global cache get time’
AND D.name = ‘global cache gets’
AND E.name = ‘global cache convert timeouts’
AND B.inst_id = A.inst_id
AND C.inst_id = A.inst_id
AND D.inst_id = A.inst_id
AND E.inst_id = A.inst_id
ORDER BY A.inst_id;
/*+ 全局缓冲区延迟服务(Global Cache Defers)性能分析,上述指标小于0.3为正常值。该指标值高表示事例间由于数据访问集中,导致全局缓冲区出现大量延迟服务 */
SELECT a.inst_id “Instance”,
a.value “Defers”,
b.value “Current Blks Served”,
(a.value) / b.value “Current Blk Service Time”
FROM GV$SYSSTAT A, GV$SYSSTAT B
WHERE A.name = ‘global cache defers’
AND B.name = ‘global cache current blocks served’
AND B.inst_id = A.inst_id
ORDER BY a.inst_id;
… …
一个项目中的故障诊断
项目概述
数年前,作为Oracle技术咨询顾问,本人为国家某信息安全项目提供了相关服务。该项目数据量高达数百TB,并且需要具有全文检索功能。因此,海量数据的分区方案设计和相关技术应用、Oracle全文索引(Oracle Text)的运用等成为该项目的显著技术特点和难点。而且,为满足海量数据处理需求,当年Oracle刚刚出炉的ASM、Clusterware、大表空间、临时表空间组等新技术也在该项目中初露锋芒。总体而言,我们为该项目提供了如下方面的服务内容:
- 参与该项目数据库物理设计,特别是分区和ASM方案设计
- 参与该项目RAC架构设计和高可用性方案设计
- 参与该项目数据加载方案设计
- 为该项目提供故障诊断服务
- 该为项目提供其它技术咨询和支持服务
当年该项目是部署在Oracle刚推出的10.1版本之上,大量运用了很多新技术和新特性,并且也使用到很多应用场景并不多的技术,如Oracle Text。这些都像一把双仞剑,既给该项目带来了鲜明技术特点和先进性,也同时带来了很多风险和问题。因此,本人在该项目前期参加完总体技术方案和关键技术方案设计之后,进入到项目详细实施阶段,则故障不断。这也回到了本章的主题:故障诊断。以下摘取当年一些典型故障,供大家参考。
下面的描述我们基本采取原汁原味方式,一方面大家可体会到当年客户的不满、抱怨等情绪,的确很多故障是Oracle新产品、新技术的Bug问题,但另一方面也有些是客户自己在设计和使用过程中的一些细节问题。这些问题毕竟是在当年的10.1版本,很多已经时过境迁了,但本人依然希望让大家感受一下当年问题的多样性和处理问题的思路。
Oracle Text索引空间不够问题
客户的问题描述如下:
“目前我们的索引表空间存在下述问题:
我们的表索引建在表空间idx上,每天(含48个表分区)的索引分别建在表空间idx01,idx02,…上,然后进行分区交换。按道理说idx应该是空的,因为每个分区的索引都建在其它表空间上。但我们在测试中发现idx的被大量占用,而且这个表空间如果小了根本就不能工作。这个问题应该如何解释?我们建的表空间都采用类似下面的语句:
CREATE BIGFILE TABLESPACE “DATA20050408” NOLOGGING
DATAFILE’+DISKGROUP1′ SIZE 68G REUSE
EXTENT MANAGEMENT LOCAL UNIFORM SIZE 64M SEGMENT SPACE MANAGEMENT AUTO ;
由于我们每天要给表增加新的分区,增加分区时索引空间就会扩展。”
- 错误现象2
客户的问题描述如下:
“我们在做分区交换时报下列错误:
SQL> alter table wyh exchange partition p5 with table wyh_stage5 including indexes * ERROR at line 1: ORA-29955: error occurred in the execution of ODCIINDEXEXCHANGEPARTITION routine ORA-20000: Oracle Text error: DRG-50857: oracle error in drvxtab.exchange_index_tables User-Defined Exception DRG-50857: oracle error in drvxtab.swap_index_temp_tables ORA-00942: table or view does not exist ORA-06512: at "CTXSYS.DRUE", line 160 ORA-06512: at "CTXSYS.TEXTINDEXMETHODS", line 804 ORA-06512: at line 2
相关信息:
怀疑该问题与回收站有关。清空回收站后第一次运行脚本没有错误,第二次运行就报该错误。再次清空回收站后又能工作。”
上述错误的原因在于数据装载脚本,而不是ASM存储管理的问题。具体原因如下:
- 现有脚本将主要业务表(BD_DXX)设计为按时间进行分区。初始建表时建立在缺省的数据表空间和索引表空间(IDX00)上。
- 当通过add partition命令增加分区时,Oracle自动维护Local索引。但此时Oracle是将增加分区的索引建立在缺省表空间IDX00上。
- 由于IDX00非常小,因空间不够,导致了上述错误:“IDX00被大量占用”以及表空间交换错误。注意:exchange的出错信息均是与索引表相关。
- 解决办法
在每次执行add partition命令之前,增加如下命令,强制将分区索引建立在指定的索引表空间中:
exec ctx_ddl.drop_preference('store_20050425');
begin
ctx_ddl.create_preference('store_20050425', 'BASIC_STORAGE');
ctx_ddl.set_attribute('store_20050425', 'I_TABLE_CLAUSE','tablespace IDX20050425 storage (initial 1M)');
ctx_ddl.set_attribute('store_20050425', 'K_TABLE_CLAUSE','tablespace IDX20050425 storage (initial 1M)');
ctx_ddl.set_attribute('store_20050425', 'R_TABLE_CLAUSE','tablespace IDX20050425 storage (initial 1M) lob (data) store as (disable storage in row cache)');
ctx_ddl.set_attribute('store_20050425', 'N_TABLE_CLAUSE','tablespace IDX20050425 storage (initial 1M)');
ctx_ddl.set_attribute('store_20050425', 'I_INDEX_CLAUSE','tablespace IDX20050425 storage (initial 1M) compress 2');
ctx_ddl.set_attribute('store_20050425', 'P_TABLE_CLAUSE','tablespace IDX20050425 storage (initial 1M)');
end;
alter index idx_bf_dxx rebuild partition P200504250000 parameters(‘REPLACE STORAGE store_20050425’)
这样每次增加的索引都落在指定时间段的表空间中,不会都存储在缺省表空间(IDX00)上而导致上述问题。
诊断该问题之前,开发人员已经将IDX00扩大到100G,已经绕开上述问题。从另一个角度说明,如果分区索引建立在其对应的表空间,就能从根本上解决上述问题。
Oracle Text索引交换问题
- 错误现象
开发人员按如下流程在进行数据的装载和Oracle Text索引的创建,出现如下错误:
- drop table test_stage;
- Create a non-partition table ‘test_stage’
- Load huge data by sql*loader into ‘test_stage’
- Create a text index on ‘test_stage’
- Exchange test_stage with a partition table ‘test’
alter table test exchange partition <> with table test_stage including
indexes;
ORA-38301:can not perform DDL/DML over objects in Recycle Bin
这是由于Oracle 10g中一个新特性所诱发。在10g中为了有效地保护数据,减少用户意外操作所导致的数据损失。增加了回收站(recycle bin)的技术。在drop 一张表之后,系统并没有真正删除,而是进入了recycle bin。而为了用户能恢复数据,上述exchange操作仍然在操作recycle bin。而实际上recycle bin中的数据只能进行查询操作,DML、DDL等均不能进行。因此出现了上述ORA-38301错误,无法完成exchange操作。
该问题是否是Oracle产品的bug,Oracle技术支持部门和研发部门正在深入研究之中。
- 解决办法
我们建议:在确定是否是bug之前,先采取饶开问题(Workaround)的方式。即强制不使用Oracle的recycle bin技术。在drop语句之后加上一个选项purge.例如:
drop table test_stage purge;
ASM空间管理问题
- 错误现象
开发人员按如下流程进行操作:
- 重新建立1T容量的Disk Group。
- 第一次建立800G左右表空间时,v$disk_asm正常显示200M左右的free_mb。
- 在经历了一段时间的create partition table, exchange partition, create Text index等操作后,v$disk_asm显示free_mb为0。
- 但此时用户还能在剩余空间内继续创建新的表空间或者扩充现有表空间。
- 所有ASM数据文件的autoextenion参数设置为NO。
- 错误原因分析1
为解决该问题,我们特意创建了一个SR:4376391.995
经Oracle技术支持人员分析,该问题可能与如下3个bug有关:
3416266:
Abstract: DISKGROUP SPACE EXHAUSTED ERROR DESPITE HAVING SPACE
4112580
Abstract: FREE_MB OF V$ASM_DISK INCORRECT AFTER 2 DISKS DROPPED
4128156
Abstract: ASM FREE SPACE NOT USED WHEN TABLESPACE CREATION USES MANY, SMALLER FILES
- 错误原因分析2
通过Oracle内部文档《Note:294325.1:“free_mb for v$asm_disk or v$asm_diskgroup reports 0 if queried from db instance”》,上述现象的另一种解释如下:
Oracle在db instance中显示free_mb为0,但在asm instance中则能正常显示free_mb的实际值。Oracle的解释这是产品的正常现象,原因是为了降低db和asm两个instance之间的通信量。但在10g第二版中可能会修改此功能,即db instance中的v$asm_disk也会正常显示free_mb值。
非常遗憾,针对上述三个bug,Oracle均没有在Linux Itanium平台单独开发patch。而是包含在10.1.0.5 patchset之中。
解决办法一:向Oracle技术支持和研发部门申请单独的Patch。Oracle称之为backport。
解决办法二:等待9月份发布的10.1.0.5 patchset for Linux Itanium。
- 第二种原因
可以忽略。或者通过Grid Control来显示正常值。
ASM扩盘问题
- 错误现象
4月4日,Oracle顾问在北京的测试现场进行增加磁盘操作时,由于系统使用了缺省的ASM_POWER_LIMIT=1,导致磁盘的rebalance过程非常长。因此,对正在rebalance的盘进行了drop操作。Drop命令成功之后,v$asm_disk仍然显示DISKGROUP1包含该磁盘。而且ASM事例系统后台出现如下错误:
ORA-7445: CORE DUMP [KFGPPARTNERS()+264] WHEN DOING REBALANCE
- 错误原因分析和解决办法
针对上述问题1,Oracle顾问建立了SR:4376391.995。根据Oracle技术支持部门的分析,确认该问题是Bug:3631330。详细情况如下:
Abstract: ORA-7445: CORE DUMP [KFGPPARTNERS()+264] WHEN DOING REBALANCE Details: Internal ASM state does not properly reflect a disk drop. v$asm_disk then contains disks that do not belong to a diskgroup after the drop.Subsequent operations may also dump (eg: in kfgpPartners) The bug is fixed in 10.1.0.4. There is no workaround mentioned in the bug.
从Oracle内部站点了解到,Oracle针对Linux Itanium只提供10.1.0.5 patchset。根据初步计划,该patchset将在2005.8.29才提供。而且没有Bug: 3631330的单独patch。
实际上,我们按正常操作次序,重新建立了DISK GROUP,一切正常。即该问题是一种特定情况下才会发生。
数据库core文件问题
- 错误现象
在数据库运行期间,在RAC1和RAC4两组RAC环境中,均出现如下现象:在$ORACLE_HOME/bin目录下每隔10分钟,出现一个core文件,大小为81M左右。消耗了大量/home区的本地磁盘资源,当磁盘资源消耗到100%之后,导致数据库崩溃。
- 错误原因分析
通过 SR : 4441689.993,15406066.6分析,该问题是与如下两个bug有关:
Bug 4401180 – ONS CORES DUMP IN MALLOC_Y
Bug 3924540 – ONS PROCESS CRASHES EVERY 10 MINS
- 解决效果
在6月29日和6月30日分别对RAC1和RAC4的8台数据库安装该patch之后,没有再出现core文件。该问题已经得到解决。
ORA-12805错误
- 错误现象
在测试期间进行查询操作的时候,会比较频繁地出现ORA-12805: parallel query server died unexpectedly。
- 原因分析和解决办法
该错误有两种原因:
- 原因1:属于正常现象
在此情况下,是将RAC环境配置成了一个或多个并行节点组,实现节点间的并行处理。主要是通过instance_groups、parallel_instance_group参数进行这种设置。
当并行节点组内的一个节点的Oracle事例被关闭时,在正常工作的节点会出现ORA-12805: parallel query server died unexpectedly错误。该现象是正常情况。Oracle的TAF只能提供当客户端到服务器端出现故障时,进行透明的切换。而服务器和服务器之间的并行处理作业出现故障时,不能提供透明切换功能。
该错误的解决办法是重新执行一遍查询语句。或不启动并行操作。
详情请见:《A Parallel Query Errors Out With ORA-12805 When The Other Node Crashes in RAC or OPS (Doc ID 200260.1)》
- 原因2:Bug 3649839
第二种原因是Bug 3649839导致。即:Intermittent ORA-12805 on internode parallel create/rebuild index
可惜Oracle没有在10.1.0.3中提供独立的patch 3649839。而是含在2005年8月份发布的10.1.0.4中。
根据测试环境的实际配置,我们认为该错误是第二种原因所导致。我们会根据客户需要,请求Oracle研发部门在10.1.0.3中提供相关patch。
10.7本章参考资料及进一步读物
本章参考资料及进一步读物:
| 序号 | 资料类别 | 资料名称 | 资料概述 |
| 1. | Oracle 11g R2联机文档 | 《Oracle® Database Administrator’s Guide》 | 该文档是DBA必读文档,涵盖了DBA日常运维管理工作的方方面面。作为DBA,故障诊断是其重要工作职责,此文档也提供了与日常运维管理相关的诸多常见故障的处理过程。 |
| 2. | Oracle 11g R2联机文档 | 《Oracle® Database Performance Tuning Guide》 | DBA的一项重要工作就是性能分析和优化。该文档是Oracle联机文档中有关优化的专著,不仅有优化方法论,也有多种性能诊断工具和优化方法的介绍。 |
| 3. | My Oracle Support | 《CRS Installation Failed with “failed to configure Oracle Cluster Registry with CLSCFG, ret 9” [ID 851742.1]》 | 这就是本章第一节案例中,CRS无法安装的原因分析和解决过程的文档。 |
| 4. | My Oracle Support | 《Remote Diagnostic Agent (RDA) – Getting Started (Doc ID 314422.1)》 | 介绍RDA的标准文档。什么是RDA?如何下载?如何使用?如何上传RDA报告?…… |
| 5. | My Oracle Support | 《Automatic Workload Repository (AWR) Reports – Start Point (Doc ID 1363422.1)》 | 了解AWR的入门文档,也是深入了解AWR的起点。 |
| 6. | My Oracle Support | 《How to Use AWR Reports to Diagnose Database Performance Issues (Doc ID 1359094.1)》 | AWR报告一个重要作用就是用于诊断性能问题。该文档包括了更多通过AWR报告分析性能问题的文档。 |
| 7. | My Oracle Support | 《How To Investigate Slow or Hanging Database Performance Issues (Doc ID 1362329.1)》 | 数据库慢或挂起了,怎么办?别着急,先分清楚究竟是慢还是挂起,然后通过10046、AWR、Errorstack、ADDM等去收集数据,进行诊断。 |
| 8. | My Oracle Support | 《Best Practices: Proactive Data Collection for Performance Issues (Doc ID 1477599.1)》 | 解决性能问题最有效的办法就是主动预防和提前诊断。该文档从方法论,到诊断工具等,相信大家从中收获不少。 |
| 9. | My Oracle Support | 《FAQ: Database Performance Frequently Asked Questions (Doc ID 1360119.1)》 | 数据库发生性能问题涉及太多方面了。如何诊断和分析?该文档介绍了Oracle的最佳实践经验,例如如何主动进行避免性能问题,也介绍了100046、systemstates、Errorstack等诊断工具,以及Log File Sync、Cache Buffers Chains Latch等与性能相关的等待事件的处理。 |
| 10. | My Oracle Support | 《Oracle Clusterware 10gR2/ 11gR1/ 11gR2/ 12cR1 Diagnostic Collection Guide (Doc ID 330358.1)》 | 这是一篇专门介绍如何收集Clusterware诊断信息的工具DiagCollection的文档,就在整理该文档时,才发现该工具过时了,应该采用新的TFA Collector工具。这就是日新月异的IT行业,呵呵。 |
| 11. | My Oracle Support | 《TFA Collector – Tool for Enhanced Diagnostic Gathering (Doc ID 1513912.1)》 | TFA Collector是Oracle最新的诊断信息收集工具,比DiagCollection功能更强、更有效。大家慢慢开始学会使用这个新工具吧。 |
| 12. | My Oracle Support | 《RACcheck – RAC Configuration Audit Tool (Doc ID 1268927.1)》 | 又一个被新工具替换的工具。新工具叫做:ORAchk |
| 13. | My Oracle Support | 《EVENT: 10046 “enable SQL statement tracing (including binds/waits)” (Doc ID 21154.1)》 | 专门讲述设置10046事件的文档。 |
| 14. | My Oracle Support | 《Interpreting Raw SQL_TRACE output (Doc ID 39817.1)》 | 如何看懂像天书一样的SQL_TRACE输出文件?请看这篇文档吧。 |
| 15. | My Oracle Support | 《How to Collect Diagnostics for Database Hanging Issues (Doc ID 452358.1)》 | 如何诊断数据库挂起问题?一个首要工作就是收集相关信息。 |
| 16. | My Oracle Support | 《Troubleshooting Database Contention With V$Wait_Chains (Doc ID 1428210.1)》 | 这就是有关11g v$wait_chains的官方详细文档。 |
Leave a Reply