SHOUG成员 – ORACLE ACS高级顾问罗敏
本文永久地址:https://www.askmac.cn/?p=16572
请允许我重复在《品悟性能优化》中关于分区技术的一段叙述:“Oracle公司历史上第一位华裔高级副总裁(SVP)曾说:随着分区技术的出现,标志着Oracle公司真正成为了名符其实的企业级数据库软件供应商,Oracle数据库也真的具有海量数据处理能力了。”
正因为Oracle分区技术在满足海量数据处理的高性能、扩展性、数据可管理性、数据生命周期管理、数据备份恢复、高可用性等综合需求中,扮演着太重要的作用,分区技术又是那么地丰富多彩。因此,我们还是结合上一章某银行大集中项目,在本章对分区技术进行专题叙述。包括该系统现有分区方案的评估、大集中系统的分区方案,以及全局分区索引、11g分区新技术等专题技术的介绍。本章最后通过一个最新案例,介绍分区技术方案的实施过程和感悟。
现有系统分区方案分析
以下就是该银行系统现有的分区方案情况,以及我们项目组给出的相关评估分析:
现有系统分区状况
目前,现有系统进行了一定的分区工作,具体情况大致如下:
- 表分区
表分区情况如下:
PARTITI SUBPART COUNT(*) ------- ------- ---------- HASH NONE 62 RANGE NONE 46 RANGE HASH 6
- 即共有62个表进行了HASH分区,46个表进行了RANGE分区,6个表进行了RANGE-HASH复合分区。
- HASH分区主要按ACC(帐号)、(PAPER_TYPE,PAPER_NO)等字段进行了HASH分区,分区数为16、32个等。
- RANGE分区主要按TRAN_DATE等时间字段,按月进行分区。
- RANGE-HASH复合分区基本按TRAN_DATE等时间字段进行第一维分区,按ACC等字段进行HASH第二维分区。
- RANGE分区和RANGE-HASH分区部署在BIG_DT1、BIG_DT2等表空间。
- HASH分区均匀部署在HASH_DT01 … HASH_DT10等表空间。
- 索引分区
- 全部为Local分区索引。包括Local Prefixed Index和Local non-Prefixed Index。
- 分区索引部署在BIG_IDX1、BIG_IDX2,HASH_IDX01 … HASH_IDX10等表空间。
现有分区状况评估
现有系统分区状况,在如下方面值得进一步商榷和改进:
- TRAN_DATE等时间字段由于采取数字表示,分区方案的可读性和维护性不是非常好。
- 索引分区只考虑Local分区,而没有考虑Global分区索引,不能全面保障SQL语句对分区表的访问性能。
- 系统已经采用了ASM条带化技术,HASH分区已经部署在多个均匀分布的磁盘之上。目前多个HASH表空间设计(HASH_DT01 … HASH_DT10,HASH_IDX01 … HASH_IDX10),并不能提高性能,反而增加了运行维护和管理难度。
- 没有充分考虑通过分区技术,降低RAC节点间访问冲突。
写本书时的进一步评估
上述分析和评估是我们提交给客户的正式文档的部分内容,比较严谨,没有过度评述。以下将进行进一步的评估:
首先,该系统的现有表分区方案设计得非常漂亮。例如,账户、卡表等表通常按账号进行查询,但不需要进行大批量数据删除或变动,因此HASH分区能很好地满足这种需求。而大量交易明细表则主要通过(时间, 卡号/帐号)进行访问,而且存在按时间(天或月)进行大批量数据清理的需求,因此RANGE-HASH复合分区也能很好地满足需求。
其次,现有分区方案的问题主要是体现在两个方面:一是设计者可能不太了解Oracle Global分区索引的含义,因此没有设计这种对性能更有好处的索引。另一个是依然采用传统思维,以为表空间越多,数据能更均匀分布,对性能有更好的保障。这两个问题也是很多系统的物理设计所普遍存在的问题。关于全局分区索引,本章后面将专题讲述,而另一个问题在上一章的“表空间设计在性能方面已经不重要了”已经有所描述。
大集中系统分区方案
以下就是该银行新的全国大集中系统在充分借鉴现有分区方案基础上,与客户、开发商充分交流、权衡利弊之后,确定的新的分区方案。
卡/折等表分区方案
- 按卡号/帐号进行HASH分区
- 对应的卡号/帐号字段索引建立成Local prefixed Index
- 其它字段索引建立成Global Hash-Partitioned Index
交易明细、交易日志等表分区方案
- 按时间 + 卡号/帐号进行Range – HASH分区
- 对(时间, 卡号/帐号)建立Local Prefix Index
- 对其它索引也建立成Local partition Index。这样,索引可能为Local non-Prefix Index。
方案评估
- 卡/折表
对卡/折表的访问主要通过卡号/帐号进行,而卡号/帐号的Local prefixed Index将有效保证访问性能。
如果基于其它字段的访问,通过Global Hash-Partitioned Index进行访问,也将有效保证访问性能。
虽然卡/折表有不动户数据的清理需求,但不会存在按分区进行大批量数据清理的需求,因此,Global Hash-Partitioned Index不会存在索引不可用的情况。
- 交易明细、交易日志表
对交易明细、交易日志表的访问主要通过(时间, 卡号/帐号)进行,通过(时间, 卡号/帐号)建立的Local Prefix Index,将有效保证访问性能。
由于交易明细、交易日志表均存在按时间(天或月)进行大批量数据清理的需求,因此可通过按时间分区进行分区的Drop、Truncate等操作,能有效保证性能。而且所有索引为Local索引,将保证索引的高可用性。
- 问题1:索引访问效率问题及解决方式
如果对交易明细、交易日志表的访问不包括分区时间字段,此时Local non-prefixed partition index将会访问所有时间分区,执行计划为Index Full Scan,这样会导致性能问题。因此,需要与应用开发结合,对交易明细、交易日志表的访问一定要强制使用分区时间条件。
- 问题2:RAC节点间访问冲突问题及解决方式
该方案没有在分区层面充分考虑降低RAC节点间访问冲突。但根据应用开发人员介绍,在应用开发中将通过分析Oracle HASH算法,来选择连接的Oracle实例,这样可以达到数据访问节点分离的目的。
3.3深入探讨全局分区索引
根据个人实施经验,在 Oracle分区技术中,分区索引技术比分区表技术更深奥,也是令设计者更容易让犯错误的地方。例如,很多系统的分区方案没有设计全局分区索引。因此,我们首先回顾一下Oracle公司给出的分区索引设计流程图,然后再深入探讨全局分区索引。
分区索引设计宝典
以下就是Oracle公司给出的分区索引设计流程图,也可称之为分区索引设计宝典:
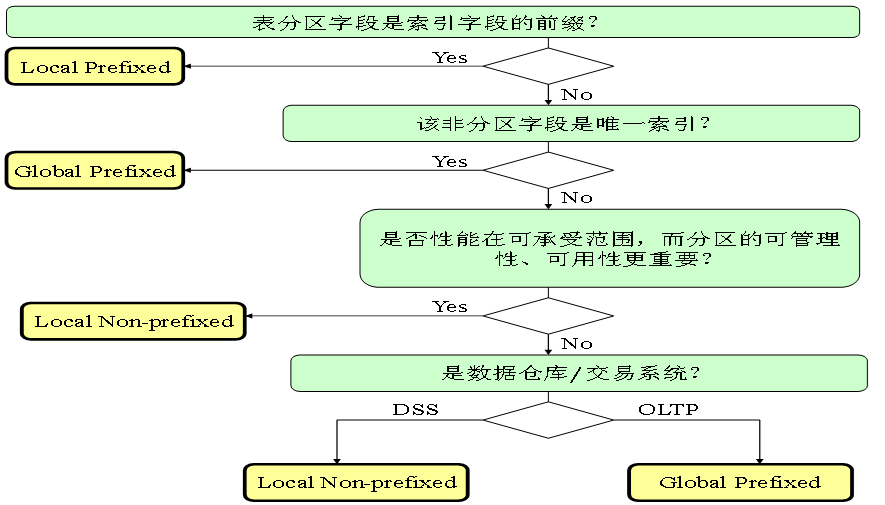
该图在《品悟性能优化》的第八章已经有专题描述,在此就不赘述。需要说明的是:通过上述设计流程图就可知道,针对不同的应用需求,Oracle各种分区索引都有一定的适用场景。而现有很多数据库系统全部设计成本地(Local)分区索引,一个全局(Global)分区索引都没有设计,显然是不正常的。
常言道:存在就是合理的。一定是设计者没有深入了解全局(Global)分区索引原理,才导致它的作用没有得到体现。
深入剖析Global分区索引
- Global分区索引的含义
首先,我们回顾一下Local分区索引的含义:所谓本地(Local)分区索引,是指索引的分区方法与对应表的分区方法一样。而全局(Global)分区索引,则是指索引的分区方法与对应表的分区方法是不一样的。例如:
假设表是按时间年度分区的,而地区字段的索引是按行政区划进行分区的,该全局范围分区索引创建语句如下:
CREATE index idx_txn_current_3 on TXN_CURRENT(area)
global partition by range(area)
(partition p1 values less than ('0572'), --- 表示杭州
partition p2 values less than ('0573'), --- 表示湖州
partition p3 values less than ('0574'), --- 表示嘉州
…
partition p13 values less than (MAXVALUE));
![]()
示意图如下:
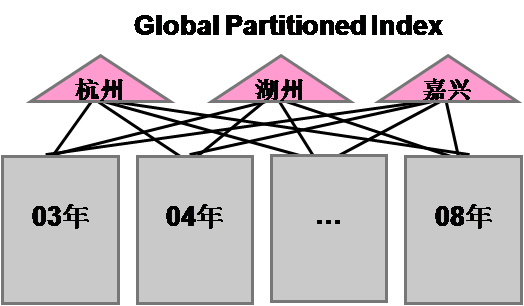
即全局分区索引与分区数据是多对多关系,也就是说每个年度都有各地区数据,每个地区数据都可能分布在各年度。
Oracle提供了两种全局分区索引,10g之前只有全局范围分区索引(Global Range – Partitioned Index),而10g之后又提供了全局哈希分区索引(Global Hash – Partitioned Index),即按索引字段的HASH值进行分区。例如,如下语句将创建一个4个分区的全局哈希分区索引:
CREATE index idx_txn_current_3 on TXN_CURRENT(area)
global partition by HASH(area) partitions 4;
- 为什么全局分区索引性能可能高于含义本地分区索引?
因为本地分区索引(Local)与表分区是一样的,分区数量也是相同的,而全局分区索引(Global)不依赖于表分区,所以全局分区索引可能比本地分区索引分得更细。例如,上述例子中,表分区可能只有03年,04年…08年等6个分区,本地分区索引也只有6个分区。而全局分区是按浙江省的地市进行分区,分区数量可能达到10余个。这样,全局分区索引比本地分区索引分得更细,每个索引分区所包含的记录数更少,索引树高度更低,因此访问性能更高。
尤其与本地非前缀索引(Local non-Prefixed Partitioned Index)相比,由于该索引可能需要访问所有分区,而全局分区索引利用分区裁剪功能(Partition Pruning)只访问若干分区索引,其性能优势将更为明显。
- 全局分区索引的不足
当表分区发生分区删除(Drop)、合并(Merge)、分离(Split)等维护操作之后,本地分区索引将自动进行维护,保持本地分区索引的可用性。而全局分区索引将失效,需要在这些分区维护操作完成之后,进行索引的重建。这就是全局分区索引存在可用性不好的问题。
- 全局分区索引的适用场景
既然全局分区索引存在上述典型的优缺点,那么扬长避短就是全局分区索引的适用场景了。当该表不存在分区维护操作,如分区删除操作,但需要通过指定字段特别是非分区字段进行高效访问,而且访问频度很高时,这就是全局分区索引的典型应用场景。例如,银行的账户表如果按账号进行HASH分区,银行账户信息是永久保存的,不可能按分区进行大批量数据删除,但需要按金融机构、地区等字段进行高效查询,这些字段就可建成全局分区索引。
案例:测试脚本带入生产系统
N年之前,某银行大型系统要进行压力测试了,为确保测试结果优异,特别是彻底打败Oracle的竞争对手,本人在分区索引设计方面做足了文章。也就是说,本人当年作足了“手脚”,呵呵。具体情况如下:
该项目最重要的交易明细表(TRADEINFO)按(CurMonth、PersonID)进行了Range – HASH分区,但应用需要按账号(Account)字段进行访问,为确保压力测试访问性能,本人决意将账号(Account)字段设计为全局分区索引。但当年的9i只有Global Range-Partitioned Index,也就是按Account字段值进行范围分区。为保证索引分区的均匀以及整体性能最佳,我当年把测试环境中某省数据的Account字段值分布进行了精心研究和计算,写出了如下的脚本:
create index credit.IDX_TRADEINFO_ACCOUNT on TRADEINFO(ACCOUNT)
global partition by range(ACCOUNT)
(partition p1 values less than ('bhw000000500000') tablespace TS_IND_QUERYRECORD_01,
partition p2 values less than ('bhw000001000000') tablespace TS_IND_QUERYRECORD_01,
partition p3 values less than ('bhw000010500000') tablespace TS_IND_QUERYRECORD_01,
partition p4 values less than ('bhw000011000000') tablespace TS_IND_QUERYRECORD_01,
partition p5 values less than ('bhw000020500000') tablespace TS_IND_QUERYRECORD_01,
partition p6 values less than ('bhw000021000000') tablespace TS_IND_QUERYRECORD_01,
partition p7 values less than ('bhw000030500000') tablespace TS_IND_QUERYRECORD_01,
partition p8 values less than ('bhw000031000000') tablespace TS_IND_QUERYRECORD_01,
partition p9 values less than ('bhw000040500000') tablespace TS_IND_QUERYRECORD_01,
partition p10 values less than (MAXVALUE) tablespace TS_IND_QUERYRECORD_01);
即按照上述分区,使得每个分区索引数据基本均匀。果然,测试结果非常棒。但这是针对某个省数据进行的设计,如果未来投入生产环境,应该全面研究全国范围的Account字段数据分布情况,重新设计该索引。于是在圆满完成测试任务之后,我提醒客户未来正式投产之前,一定要根据Account字段实际记录值分布情况,重新设计该索引。但也许是客户太满意测试结果,也许是客户对该索引原理理解本来就不够,总之,该索引的测试脚本居然直接带入生产环境,而且运行至今!也就是说,现在查询该省的数据会更快,而查询其它省的数据就会慢一些。呵呵。
当年还感慨,怎么Oracle不设计个Global HASH-Partitioned Index呢?Oracle通过HASH算法自动把索引打散不就好了吗?害得我和客户要对 Account字段值这么去费尽脑汁。Oracle 10g出来之后,本人的第一眼就是去看有这个东西没有,有了!太开心了。可惜,快10年过去了,该系统还运行在9i平台,还没有升级和改造,还在使用这个测试脚本。唉!
系统被挂死了
某移动公司在某年9月1日出现了核心业务系统被挂死(Hang)的严重故障。以下就是详细情况:
- 问题现象
该移动公司为推广业务,针对每年入学的新生推出了学生卡业务。由于9月1日新生开学集中办理业务,核心系统批量开户数急剧增加,导致业务响应慢,数据库出现被挂死(Hang)的严重故障。当时数据库后台表现为:enqueue等待事件非常高。
- 问题原因
这是由于大量并发Insert操作,导致与Sequence相关的主键等索引单调增长,出现热块和I/O竞争。 例如,用户表的主键为普通索引、其它为Local non-prefixed Partition索引 ,大量Insert操作导致这些索引出现热点块竞争。示意图如下:
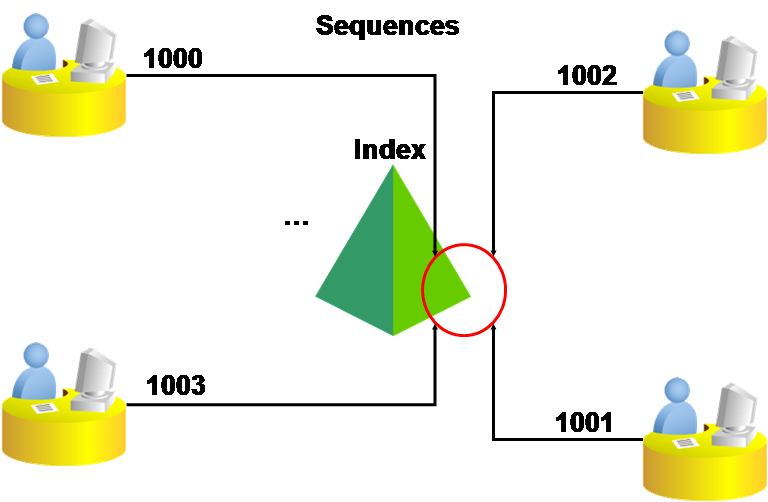
- 临时解决方式
使用Sequence生成主键,在大批量数据加载情况下出现热块和竞争,这是非常普遍的一类问题。如何解决?当时客户DBA采取了将该表索引重新创建为反转(Reverse key) 方式,缓解了该问题,确保了系统正常运行。所谓反转索引,就是将被索引字段值从右往左进行颠倒,例如1002变成2001,1010变成0101…,这样原来单调增长的主键就被打散、变成无序的了。但反转索引有很多使用上的限制,例如不支持范围查询(Between, like等)。因此,这只能是一种临时解决方式。事实上,在度过9月1日的业务高峰期后,该移动公司DBA又将该索引恢复成普通索引了。
- 问题的深层次分析
如果排除9.2.0.8版本存在相关Bug的可能性,该问题其实是在现有9i平台无法根本解决的问题。如下图所示:
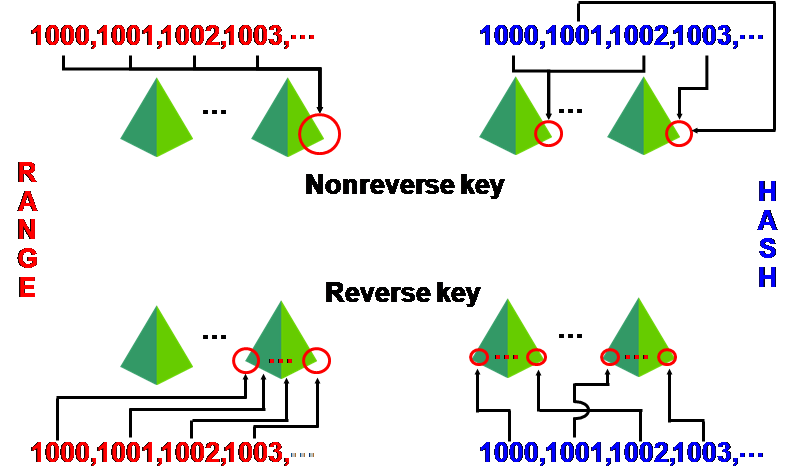
即在现有9i平台(图左部),无论索引是否分区,都会存在索引单调增长而带来的竞争问题。而且即便采用了反转索引,也只能在一个分区内将竞争缓解。
有效的解决方式应该是10g以上的Hash–Partitioned Global Index技术(图右部),这样Oracle将索引分布到不同分区,有效降低I/O竞争,消除热点。如果采取Hash–Partitioned Global Reverse Index,将进一步在分区内降低竞争。因此,该问题应该是升级到10g/11g之后,通过新的分区索引技术才能加以有效解决。
总之,全局分区索引在提高访问性能、降低热点数据冲突方面是大有作为的,唯一的缺陷是分区维护操作之后,该类索引将失效。其实建立在分区表上的普通非分区索引在分区维护操作之后,也同样失效。因此,根据应用场景,合理设计全局分区索引将对海量数据处理大有益处。
11g分区新技术
黔驴技穷了
某年去国税行业提供分区方案改造的技术支持。在总结以前若干次分区方案经验教训基础上,客户、开发商和我们自己都对此次改造工作提出了更全面的目标。例如通过分区技术满足日常访问性能、提高历史数据清理能力、提高数据高可用性等。
但我们在运用9i、10g的分区技术对最重要的SB_ZSXX(申报_征收信息)表进行分区方案设计时,却遇到了难以克服的技术难题。首先为实现上述多重目标,我们决定按时间(月)- 税务机关进行组合分区。第一维按时间(月)分区,是为了满足按月或年进行历史数据清理的需要,第二维按税务机关进行二级分区,是为了按税务机关进行访问和大批量数据管理的需要。但9i、10g的组合分区只有两种:Range–Hash和Range–List。
显然Range–Hash满足不了需求,因为第二维将税务机关按Oracle HASH算法进行分区,用户无法知晓某个税务机关数据落在哪个具体分区,无法实现按税务机关进行访问和大批量数据管理的需要。
如果采用Range–List呢?由于税务机关代码采用了国家行政区域分层编码,并一直到税务所一级,而客户只希望分区到地市级,但9i又不支持将基于函数的分区,例如substr函数。怎么办?难道再增加一个地市字段?多烦啊。还要通过应用程序或写Trigger维护这个地市字段。
当时我就想,如果Oracle支持基于函数的分区技术多好,而且如果有Range – Range复合分区技术多好。唉,当时的9i都没有,黔驴技穷了,这次只好放弃复合分区,而只采用了按时间进行的一维分区方案,这也意味着客户部分需求没有充分满足。
10g出来了,我便查看有无这些新技术,遗憾,还是没有。11g出来了,新特性课程有一章专门讲解分区技术,我赶紧扫了一眼,我的妈呀,太震撼了!不仅有我期待的基于函数的分区技术(11g称之为基于虚拟列分区技术),更有让我眼晕的若干新复合分区技术,还有未曾想到的间隔分区、引用分区、系统分区技术等等。
复合分区大大增强
在11g中,组合分区技术大大增强,结合新的间隔(Interval)分区,Oracle现在共有9种组合分区技术,如下图所示:
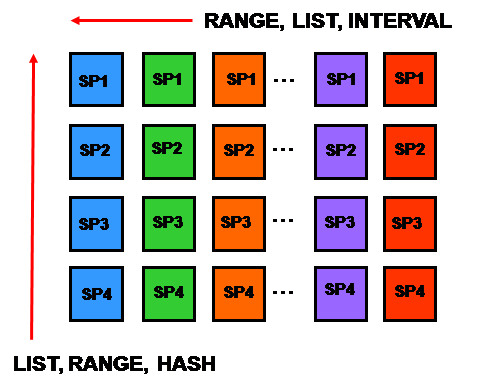
即:Range – List, Range – Range, Range – HASH,List – List, List – Range, List – HASH, Interval – List, Interval – Range和Interval – HASH。也就是说,只要HASH不是第一维,其它组合都可以。而且还可以与虚拟列分区相结合。
如此丰富的组合分区技术,应该能满足客户对海量数据处理的绝大部分需求。
引用(Reference)分区技术
首先,我们先看如下例子,一个订单表(ORDER)和订单明细表(ORDER_ITEMS),二者通过订单号字段(ORDER_ID)形成主从关系,即一个订单可能包括多个所订产品。
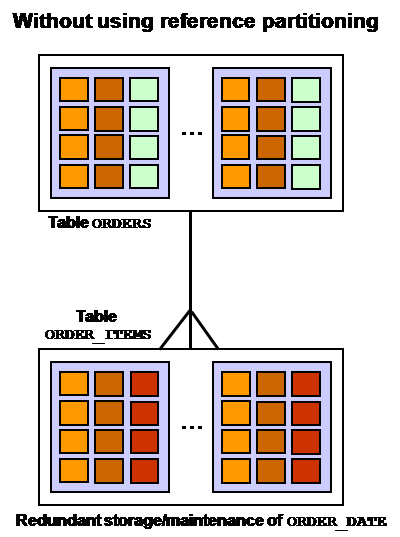
如果采取11g之前的分区技术,ORDER表按订单日期(ORDER_DATE)字段进行范围分区,假设也想让ORDER_ITEMS表进行同样的分区,则需要在ORDER_ITEMS表中增加订单日期(ORDER_DATE)字段。显然该字段是冗余的,是不符合规范化设计的。而且两个表独立设计和管理,还可能带来数据的不一致,甚至产生垃圾数据。例如假设ORDER表按ORDER_DATE进行了历史数据清理,而ORDER_ITEMS没有进行相同的操作,则ORDER_ITEMS相关数据将成为垃圾数据,谁也不会去访问这些数据了。
现在到了11g,通过引用(Reference)分区技术,可以有效解决该问题,示意图如下:
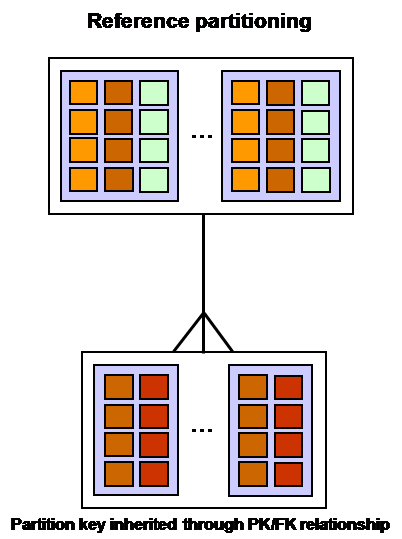
脚本如下:
CREATE TABLE orders
( order_id NUMBER(12) , order_date DATE,
order_mode VARCHAR2(8), customer_id NUMBER(6),
order_status NUMBER(2) , order_total NUMBER(8,2),
sales_rep_id NUMBER(6) , promotion_id NUMBER(6),
CONSTRAINT orders_pk PRIMARY KEY(order_id)
)
PARTITION BY RANGE(order_date)
(PARTITION Q105 VALUES LESS THAN (TO_DATE(‘1-4-2005′,’DD-MM-YYYY’)),
PARTITION Q205 VALUES LESS THAN (TO_DATE(‘1-7-2005′,’DD-MM-YYYY’)),
PARTITION Q305 VALUES LESS THAN (TO_DATE(‘1-10-2005′,’DD-MM-YYYY’)),
PARTITION Q405 VALUES LESS THAN (TO_DATE(‘1-1-2006′,’DD-MM-YYYY’)));
CREATE TABLE order_items
( order_id NUMBER(12) NOT NULL, line_item_id NUMBER(3) NOT NULL,
product_id NUMBER(6) NOT NULL, unit_price NUMBER(8,2),
quantity NUMBER(8),
CONSTRAINT order_items_fk
FOREIGN KEY(order_id) REFERENCES orders(order_id)
) PARTITION BY REFERENCE(order_items_fk);
上述ORDER表的分区采用常规技术,按ORDER_DATE进行范围分区。而ORDER_ITMES表首先没有了ORDER_DATE字段,其次,该表采用了REFERENCE分区,即通过外键(order_items_fk)进行分区,使得ORDER_ITMES子表采取与父表ORDER相同的分区方法。这样,主表和子表在分区管理上也是一体的。主表增加一个分区,子表自动增加一个分区。主表删除一个分区,子表也自动删除一个分区。
因此,通过引用(Reference)分区技术,将不仅简化海量数据管理,而且提高了数据一致性。
感慨:很多系统不愿意设计表间外键关系,设计者自称担心性能,甚至自己都无法道出原因。殊不知,这种粗放的设计方式,失去了多少运用好技术的可能性。唉!
再次品味分区的甜与苦
分区实施可不简单
2013年中,我应某客户要求,对其一个非常重要的生产系统设计和实施分区方案。从我1995年第一次听说Oracle将推出分区技术,到1998年第一次接触分区技术,再到2013年,已经与分区技术打了10多年交道了,深深感受到Oracle分区技术博大精深。分区技术可不是只对几个大表进行分区设计,然后把数据一倒,就简单完事了。
为圆满完成此次分区工作,我特别与客户事前商量了如下详细的3天实施计划:
| 时间 | 工作项目 | 详细内容 |
| 第一天上午 | 基准数据采集及调研分析 | nmon采集现有系统操作系统数据
statspack数据收集 确定分区方案原则 确定分区表 分区表语句行为分析 |
| 第一天下午 | 分区方案设计 | 表分表方案设计
索引分区方案设计 分区表空间方案设计 分区实施方案设计 分区方案测试 |
| 第一天晚上
第 天上午 |
分区方案实施 | 分区方案实施 |
| 实施后技术支持及基准指标采集 | 实施后技术支持
nmon数据采集 statspack数据收集 nmon数据对比分析 Statspack报告对比分析 |
|
| 第二天下午 | 指标对比分析及方案善后工作 | 实施后技术支持
单个SQL语句性能对比分析 分区维护方案设计 应用改造建议 文档整理 |
| 第三天上午 | 技术支持、对比分析和工作汇报 | 实施后技术支持
nmon和statspack采集和对比分析 分区技术和实施工作汇报 其它技术交流工作。如11g升级技术等 |
如上表显示,在分区方案设计和实施中,不仅应进行基准数据的采集,还应有分区原则的设计、分区表方案设计、分区索引方案设计等,更应有测试和实施后效果对比等。可见,在Oracle技术领域,任何技术的实施都应有全面的方案设计和实施计划。
出师不利
第一天白天,在经过调研分析,通过如下语句查询出存储空间最大的前20张表:
Select * from (Select * from dba_segments where segment_type=’TABLE’ order by bytes desc) where rownum <= 20;
按照Oracle公司空间大于1GB、记录数超过1千万的分区标准,先初步确定前8个表为分区表。
再通过如下语句,研究应用SQL语句对这些大表的访问特征:
Select * from (Select * from v$sqlarea
where upper(sql_text) like ‘%PC_PRO_WELL_VOL_DAILY%’ order by buffer_gets desc) where rownum <= 20;
经过对这些SQL语句的分析,我们发现该系统日常联机查询和大批量数据处理基本都包含时间条件,因此,本次分区我们将以各表的时间字段进行范围分区。
分区索引方面,则考虑该单位技术人员力量不强,应尽量确保索引的可用性,降低运维人员工作量。因此,初步决定采用可维护性更好的Local索引。包括Locl Prefixed分区索引和Locl non-Prefixed分区索引。
在白天与客户确定分区方案之后,下班后我们开始以如下流程进行分区方案实施:
- 干净地停止数据库和Listener
- 重起数据库实例,并打开数据库
- 建分区表,同时导入数据
- 删除原表
- 将新分区表更名为原表名
- 为字段添加注释
- 重建分区索引、限制等
- 重新采集统计信息
在我按上述流程正常进行了2个表的分区之后,客户DBA要求自己完成第三个表的实施。
一切似乎都很正常,在晚上9:00多完成第一批3个表的分区之后,应用开始功能验证和性能验证了。结果应用人员很快反应:一个前台录入界面出现空白!如何诊断?前台就一个大白屏幕,什么错误信息都没有,数据库日志也没记录什么信息。我也不会看应用服务器的日志,就这么胡折腾了2个多小时,实在没办法,只好进行回退了。
第二天上午在应用人员支持下,在应用服务器日志中终于找到了有价值的错误信息。通过在互联网搜索,发现与此错误信息相关的问题是统计信息不准确,导致语句执行计划出现问题,从而使得语句性能低下。详细检查前晚实施情况,我们发现客户DBA在实施第3张表分区时,的确忘了最后一步:采集该表的统计信息。因此,导致Oracle优化器产生非最优的执行计划,使得语句性能低下,最终导致应用超时,连接中断,界面出现白屏。
解决起来很简单:重新实施第3张表分区操作,并采集和更新该表统计信息之后,确保Oracle优化器产生最优执行计划,问题得到有效解决。
感慨一下:老革命这次遇到老问题了,又是统计信息问题,呵呵。这次难的是不懂应用服务器知识,不能在应用服务器日志中有效找到出错信息,然后去刨根问底。
继续受挫
在第二天下午重新实施第3张表分区操作之后,若干语句性能出现衰减问题。这些语句片断如下:
…
Where well_id = :B1
And to_char(PROD_DATE,’yyyy-mm-dd’)=to_char(‘2013-06-18′,’yyyy-mm-dd’)
…
在分区之前,这些语句基于WELL_ID字段的普通索引进行访问。而在分区之后,该索引设计为Local non-prefixed分区索引。而语句中PROD_DATE字段前的to_char函数导致 Oracle无法使用分区裁减功能,最终导致Oracle需要访问该Local non-prefixed分区索引的所有分区字段,从而使得分区之后性能反而低于分区前的性能。
因此,出现性能衰减不是分区方案本身问题,而是应用语句编写错误导致性能出现问题。
如何解决?由于应用一时无法修改,只能取消WELL字段的分区索引,恢复为原来的普通索引,应用性能基本恢复到原来状态。
谁说分区索引一定能提高性能?很多情况下普通索引效率比Local non-prefixed分区索引效率反而更高!
试想,国内有多少Oracle数据库系统的分区方案设计了大量Local non-prefixed分区索引,其实性能可能还不如不分区的普通索引呢!
案例的感慨
世界上有很多这样美好的谎言:“如果你采用了什么什么新技术,你的系统处理能力一定得到极大提高”。还有更具体的:“分区技术对应用是透明的,你的应用不用做任何改造,使用分区技术,处理能力肯定得到大幅度提升。”
错!一句被反复验证的话是:一个原本就很好的系统,运用新的先进技术将达到如虎添翼的效果。而反之,如果应用软件质量不高,匆忙运用新的先进技术,效果往往是适得其反的。
在原理上,分区技术本质是对应用透明的,Oracle公司这种宣传也是没有问题的。但对应用的深入分析,特别是应用本身合理的优化改造,才能真正达到分区的目的,也才能把分区技术的特点和优势发挥得淋漓尽致。
总之,现有系统的优化,特别是应用软件本身的优化将是未来一切新技术和先进技术运用的重要前提和基础。
3.6本章参考资料及进一步读物
本章的参考资料及进一步读物:
| 序号 | 资料类别 | 资料名称 | 资料概述 |
| 1. | Oracle 11g R2联机文档 | 《Oracle® Database VLDB and Partitioning Guide》 | Oracle 11g之前有关分区的技术散落在联机文档的多本书中,而11g之后专门推出了这本书,可见分区技术的重要性!这可是从事海量数据库设计和分区设计的必读物! |
| 2. | My Oracle Support | 《Master Note for Partitioning (Doc ID 1312352.1)》 | 从事海量数据库设计和分区设计的又一必读物!分区技术资料的索引! |
| 3. | My Oracle Support | 《GUIDELINES FOR PARTITIONING INDEXES IN 8.XX (Doc ID 1056340.6)》 | 虽然是当年8i时期写出的资料,但的确是讲解分区索引设计指南的经典文章。 |
| 4. | My Oracle Support | 《How to Implement Partitioning in Oracle Versions 8 and 8i (Doc ID 105317.1)》 | 同样是一篇写于8i时期的文章,但对分区技术而言同样是经典读物! |
| 5. | My Oracle Support | 《Partitioned Indexes: Global, Local, Prefixed and Non-Prefixed (Doc ID 69374.1)》 | 就是因为仔仔细细阅读和研究了该文章将近2个小时,让我终于明白了Oracle分区索引技术中最难懂的Local Non-Prefixed索引! |
| 6. | My Oracle Support | 《Top Partitioned Index Issues (Doc ID 165309.1)》 | 又一篇介绍分区索引原理、设计和管理的经典文章! |
Leave a Reply