本文永久链接 https://www.askmac.cn/archives/oracle-free-space-managements-验证报告.html
介绍
Oracle从Oracle9i开始为了管理段内空闲区域free extent,会新建bitmap来使用
追加了自动段区域管理这个功能。作为一直以来(Oracle6~Oracle8i)的管理段内空闲区域free extent的方法,可以使用free list (FREELISTS),这是管理数据块的唯一方法。另外,使用自动段区域管理的优点如下所示:
– 便于管理(特别是在Real Application Clusters(RAC)环境中)
– 提高区域使用率
– 提高同时执行处理
一直以来,管理空闲区域free extent的唯一方法都是free list(FREELISTS),free list groups。FREELIST GROUP的设定非常复杂,需要数据库管理者有大量的知识储备,自动段区域管理会自动调整好这些设定,变得非常简便了。另外,自动段管理会自动确认相邻的连续空闲区域free extent,所以不需要合并空白范围 (COALESCE)。由此可以提高区域使用率。但是,这究竟是否与性能有关呢?是否自动段管理比一直以来使用free list的空闲区域free extent管理的执行处理要快呢?本报告就是为了回答这个疑问,将日本oracle公司中进行的测试结果做了一个汇总。
区域管理方式概要
作为区域管理方式的选项,根据管理的layer差异,有以下几种组合。
表区域(表区域的EXTENT管理)
- 本地管理表管理表区域
- 用管理bitmap可以使用的EXTENT
- 用bit值分辨空闲区域free extent以及使用完成
- 自动识别相邻空白EXTENT
- 从9i开始的默认管理方法
▼ 本地管理表区域中EXTENT管理(分配方法)
○ AUTOALLOCATE(默认)
□EXTENT的尺寸在系统中会自动管理自动分配。
– 初始EXTENT会分配到64KB
– 段尺寸小于1MB时,分别分割为64KB
– 段尺寸大于1MB小于64MB时,会分别分配1MB
– 之后就按1MB,8MB,64MB等尺寸来进行分配
○ UNIFROM SIZE
□通过指定EXTENT分配尺寸的值,可以使其统一。
- 目录管理表区域
- 通过数据目录管理可以使用的EXTENT
- 表区域中的各个段中,可以指定不同的记忆区域参数
- 需要合并相邻的空白EXTENT(COALESCE)
◆ 段区域管理
- 自动段区域管理(管理bitmap)
- 使用bitmap追踪段内部可以使用的部分以及使用完成的区域
- 自动管理PCTUSED、FREELISTS、FREELISTS GROUPS
- 手动管理数据块
- 利用PCTFREE、PCTUSED、FREELISTS、FREELISTS GROUPS手动构成数据块
- 目录管理表区域中,这是唯一的管理方法
◆ 段区域管理
- 自动段区域管理(管理bitmap)
- 使用bitmap追踪段内部可以使用的部分以及使用完成的区域
- 自动管理PCTUSED、FREELISTS、FREELISTS GROUPS
- 手动管理数据块
- 利用PCTFREE、PCTUSED、FREELISTS、FREELISTS GROUPS手动构成数据块
- 目录管理表区域中,这是唯一的管理方法
使用bitmap的空闲区域free extent管理概要
自动段区域管理中,段内空闲区域free extent的管理中就会使用到bitmap。这里的bitmap中,就会记录段内的各种数据块的使用量状态相关的信息。以下就是相关说明。
- 通过bitmap,使用率的表示方法依赖于段类型
- 数据块
Bitmap的状态可以在所有的活跃事务都被commit之后,以块内可以使用的空闲区域free extent的总计值来算出来。
。
- 索引段
索引段的话,bitmap会表明那个块是否是空白块的候补。
- LOB段
Bit并不是表示对应的1个块,而是表示块的chunk
那么实际上块的空闲区域free extent状态是怎样通过bit来表现出来的呢。
具体来说如下所示,将4个bit作为一个set来使用。

我将说明自动段区域管理(bitmap区域管理)中数据块的PCTUSED、PCTFREE的关系(制成段时,可以自动无视指定PCTUSED值)。
内部操作如下
空白块的性能指标(Block Space Utilization)
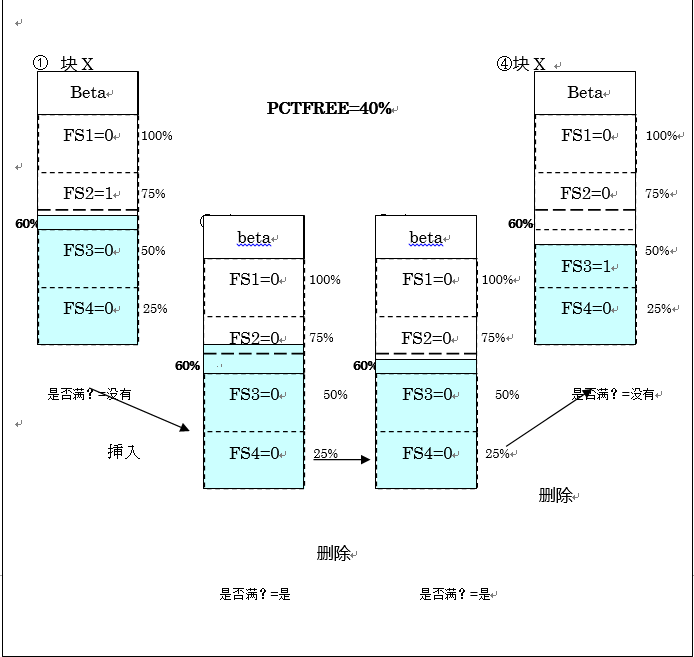
Bitmap的管理中,数据块被分为4个部分(不包含数据beta)。上图中,被分割为4个部分FS1、FS2、FS3、FS4。然后根据4个会话,可以如下所示展示空白状态。
- FS1・・・块有0%到25%的空白空间
- FS2・・・块有25%到50%的空白空间
- FS3・・・块有50%到75%的空白空间
- FS4・・・块有75%到100%的空白空间
根据块内空闲区域free extent的水平,就会动态更新空白状态。
在图1-1的例子中,块X中,可以将空白状态以FS2来表现。原因在于块X已经使用了一半以上了,并且,还留存了25%以上的空闲区域free extent。对这个块X执行几次插入处理,假设块内使用完成的区域指定为PCTFREE,超过了阀值。(图1-1中②的状态)。这时,假设这个块无法使用新的插入处理,就可以竖起满(full)的flag。之后,进一步进行删除处理。虽然在同样的FS2,中也存在,对正在使用的区域中使用PCTFREE指定的阀值进行一定程度的下调(图1-1中③的状态)。但是此时,块中已经插满了flag。
那么,什么时候这个flag会被排除,什么时候又会再次在插入处理中使用这个块呢?根据删除处理,块的使用状态在FS2中出现在范围之外时,换言之,变成FS3的状态时(图1-1中④的状态)。
因此,一直以来的free list管理中,作为PCTUSED可以用百分比单位来指定这个值,在bitmap管理中,实际上,用25单位重复的值来设定,请注意这些点。
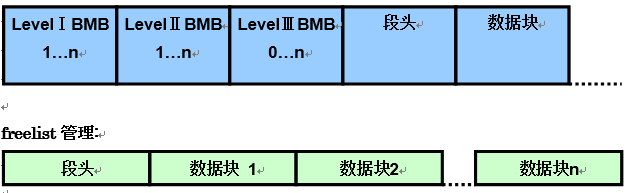
Bitmap储存在被称为bitmap块,bitmap被储存在被称为bitmap块的数据块组件中。在自动段区域管理中以段头与其数据块这种形式,最大可以保持3个水平的bitmap块。在如下所示的图1-2中,表示各个水平的bitmap块之间的关系。
Bitmap段的等级制度
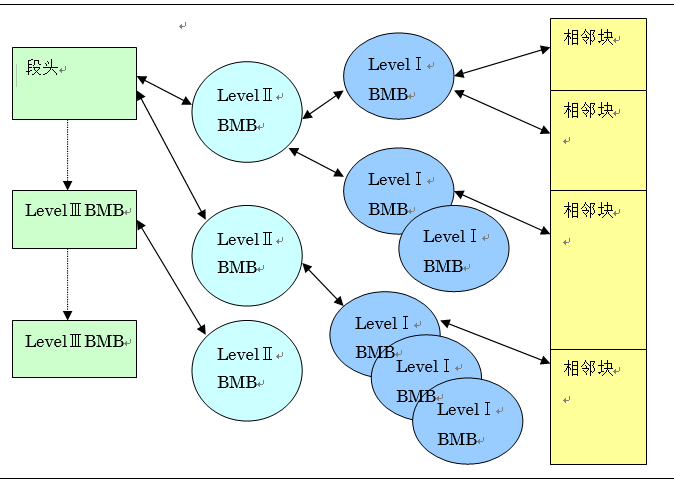
如上述图1-2bitmap段的等级制度相关图中所示,bitmap块为树形结构,根部是段头(或者说是LevelⅢBMB)需要空闲区域free extent的所有进程首先会从这个段头(或者说是LevelⅢBMB)开始执行减少错误,然后标记可用空闲区域free extent。LevelⅠBMB中,会储存对应块以及空白状态信息DBA(Data Block Address)。
下面说明空白块的搜索方法相关概要。
◆空白块搜索方法概要
- 如果存在插入处理中已经应用的数据块的话,就会在那个数据块中储存接下来的插入数据。最开始的插入处理或者块的空闲区域free extent不够时,就会执行步骤2。
- 因为最后使用过的LevelⅡBMB的DBA将段头块作为提示储存了,所以就会执行对那个LevelⅡBMB管理的数据块的写入。
- 通过步骤2中决定下来的LevelⅡBMB来管理的LevelⅡBMB之中,选择空闲区域free extent最多的项目。LevelⅡBMB中没有空闲区域free extent时,通过执行插入的进程的进程ID来执行哈希处理来决定其他的LevelⅡBMB。段内完全没有空闲区域free extent的话,就会分配新的extent,返回步骤2。
- 在Level1BMB中寻找空白块。这时,请再次用进程ID执行哈希处理,决定搜索开始的位置。由此,就可以防止多个进程插入时的竞争。如果发现了空白块的话,就对这些块进行pin。如果不能pin或者空闲区域free extent不够时,请持续进行bitmap的扫描。
空白数据块的搜索相关的详细算法的说明以及bitmap管理的详细信息请参考本文末的《8.参考资料》。
内容提要
在自动段管理中(bitmap管理),在bitmap块中,可以通过段内对应的一个个数据块的空白状态从满,依次到(FULL)・0%~25%・25%~50%・50%~75・75%~100%——这样较为精细的设定,来管理。一直以来的free list管理中拥有可以用于插入处理的空闲区域free extent,所以数据块就会链接到free list。
要管理对应bitmap块的所有的数据块的空白状态的话,从区域使用效率来看,比起free list管理要更好。但是,通过这里数据块的管理对象的合计,我们应该可以猜到未来会有这样的发展趋势:使用管理对应所有数据块的空白状态的bitmap管理的人数,会超过使用free list管理的人数。
这是由于对新建数据执行大量插入、删除、更新处理,在大部分数据块的空白状态变化时,使其不会破坏bitmap管理。
对应的,管理数据块较多就代表,通过对长度可变的column进行更新,在数据长度比现有数据更大的案例中,可以掌握哪里有存在一定的空闲区域free extent的数据块,并可以有效利用
上述问题到底在这次的测试中是否能够成立呢?请关注下文。
测试概要
这次的验证中,重点在于评价两种方法的性能差异:1.使用至今的,使用了free list集群(free list group)的空闲区域free extent管理,2.新功能,使用bitmap的空闲区域free extent管理。为了避免oracle的其他功能影响测试结果,我们通过以下组合来测试性能。
| 表区域管理 | 段管理 | extent管理
(分配方法) |
| 本地管理表区域
块尺寸 2K |
自动 bitmap管理 PCTFREE 30 |
AUTOALLOCATE |
| UNIFORM SIZE 1GB | ||
| 手动数据・块管理 PCTFREE 30 PCTUSED 40 PCTINCREASE 0 FREELISTS 20 FREELISTS GROUP S 4 |
AUTOALLOCATE | |
| UNIFORM SIZE 1GB |
另外,对于上述各种案例的性能差异之间,我们获得了单独案例(SI)环境Real Application Clusters(RAC)环境两种案例之中的数据进行了评价。
测试中所使用的H/W环境
| Server | HP L2000 2-nodes CPU PA-8500(360Mhx) * 4 Memory 2GB |
| Interconnect | 100MB Ethernet*2 |
| Storage | EMC Symmetrix 8430 (Cache 8GB) |
| O/S | HP-UX B.11.11 64-bit (February 2001 Patch Bundle) |
| Clusterware | ServiceGuard OPS Edition Bundle A.11.13 |
| Database | Oracle9iR9.0.1.1 w/option Real Application Clusters |
测试方法
在下述测试项目中,分别获得各自的合计处理执行时间、CPU使用率、oracle的统计中的数据 (STATSPACK)。对于RAC环境中的处理时间请将其看成两案例中所有事物完结的时间、终止时间(根据不同情况,可能会有某个实例的处理优先完成的情况)。
SI环境中的测试方法
◆ 测试中使用过的表架构
| 列名 | 属性 | column长度(Bytes) | 索引 |
| C_1 | VARCHAR2 | 2 | 没有插入、有更新与删除、没有更新与删除 |
| C_2 | VARCHAR2 | 1960 | 没有 |
使用的数据长度
对于column C_1为2Bytes,对于column C_2来说,为了避免行连锁与行移行,需要使用1,460Bytes的字符串(半角英文)数据。
-插入(Insert)
在20个客户端中,对各个进程同时定义每5,000行(总计 200,000行
= 20客户端 × 5,000行)VARCHAR2的各自的column C_1、C_2插入数据。
-更新(Update)
同样地,还有这两种方法,在20个客户端中,将column C_1作为搜索关键词,将column C_2的值更新为NULL,或者将NULL的值更新为1460bytes的字符串。并且,获得在column C_1中制成时的数据以及没有使用时的数据。在没有竞争的进程中,每次更新5000行 (合计 200,000行= 20客户端 × 5,000行)。
-删除(Delete)
同样地,在20个客户端中,将column C_1作为搜索关键词删除行整体。在没有竞争的进程中,每次删除5000行。删除处理也需要获得column C_1中使用索引时的数据,以及没使用的数据。
RAC环境中的测试方法
◆ 测试中所使用的架构
| 列名 | 属性 | column长(Bytes) | 索引 |
| C_1 | VARCHAR2 | 2 | 没有 |
| C_2 | VARCHAR2 | 1960 | 没有 |
◆ 所使用的数据长度
对column C_1为2Bytes,对C_2来说,为了避免行连锁与行移行,需要使用1,460Bytes的字符串(半角英文)数据。
(合计100,000行 = 20客户端 × 2,500行 × 2 案例 )
在column C_1、C_2中插入使用VARCHAR2定义的各自的数值。
-更新(Update)
同样的实例中,20个客户端同时将column C_1作为搜索关键词。将column C_2的值更新为NULL。在没有竞争的进程中,每次更新2500行 (合计 200,000行= 20客户端 ×2500行×2实例)。
-删除(Delete)
同样的实例中会将column C_1作为搜索关键词来删除行整体。在没有竞争的进程中,会重复一次一次地删除2500行(合计100,000行 = 20客户端 × 2,500行 × 2 实例)
结果与验证
7.1 Single Instance环境
▼ 插入(Insert)处理
下述表7.1-1是展示在插入处理时,所需要的时间以及CPU平均使用率 (%usr+%sys)的结果的一览。并且,不仅是这些数值的平均,而是一次的处理中获得的数值。
表7.1-1. SI中插入处理结果
| 段管理方法 | extent管理方法 | 处理 | 处理时间 | CPU平均 使用率 (%usr+%sys) |
|
| 自动 bitmap管理 |
Autoallocate | Insert | 454秒 (7分34秒) |
85% | |
| 自动 bitmap管理 |
Uniform Size 1GB | insert | 425秒 (7分05秒) |
87% | |
| 手动 Freelists 20 Freelists Gropus 4 |
Autoallocate | insert | 424秒 (7分04秒) |
89% | |
| 手动 Freelists 20 Freelists Gropus 4 |
Uniform Size 1GB | insert | 424秒 (7分04秒) |
90% | |
如上表所示,在SI环境中,用bitmap管理空闲区域free extent,除去用Autoallocate进行extent管理的情况,空闲区域free extent的bitmap管理以及free list管理之间,处理时间几乎相同。那么,在初始的bitmap管理中用Autoallocate来进行extent的分配时,处理速度大概会降低7%。基于此,验证各个STATSPACK报告。
– Top 5 Wait Events (插入处理-SI环境)
下表7.1-2是在插入处理中的统计信息:Top 5 Wait Events。
*表7.1-2插入处理中的Top 5 Wait Events
| Top 5 Wait Events | ||||||
| 段管理方法 | extent管理方法 | 处理时间 | Event | Waits | Wait Time(s) | %Total Wt Time |
| 本地 bitmap管理 |
Autoallocate | 7分34秒 | log file sync | 197,256 | 2,968 | 45.05 |
| latch free | 68,171 | 966 | 14.66 | |||
| enqueue | 7,017 | 665 | 10.1 | |||
| ges remote message | 378 | 461 | 7 | |||
| free buffer waits | 1,632 | 401 | 6.09 | |||
| 本地 bitmap管理 |
Uniform Size 1GB | 7分05秒 | log file sync | 194,263 | 2,558 | 46.62 |
| latch free | 63,304 | 921 | 16.78 | |||
| ges remote message | 363 | 443 | 8.07 | |||
| enqueue | 3,630 | 439 | 8.01 | |||
| free buffer waits | 1,183 | 274 | 4.99 | |||
| 本地 Freelists 20 Freelist Group 4 |
Autoallocate | 7分04秒 | log file sync | 193,691 | 2,921 | 52.55 |
| latch free | 67,878 | 934 | 16.81 | |||
| ges remote message | 380 | 464 | 8.35 | |||
| enqueue | 9,006 | 440 | 7.91 | |||
| io done | 54,882 | 290 | 5.21 | |||
| 本地 Freelists 20 Freelist Group 4 |
Uniform Size 1GB | 7分04秒 | log file sync | 195,590 | 3,434 | 57.82 |
| latch free | 64,572 | 866 | 14.58 | |||
| ges remote message | 392 | 478 | 8.06 | |||
| io done | 48,167 | 325 | 5.47 | |||
| enqueue | 8,632 | 235 | 3.97 | |||
bitmap管理以及free list管理的比较
extent管理中,指定了Uniform Size时,要限定处理时间的话,就会出现差距几乎相同的结果。那么这次需要测试空闲区域free extent的管理方法之间的差距。
首先,请参考以下下表7.1.1-1。这是bitmap管理中的STATSPACK报告的Buffer busy waits。
* 表 7.1.1-1 bitmap管理/Uniform Size 1GB中的Buffer busy waits
| Buffer busy waits | |||||
| 段管理方法 | extent管理方法 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 自动 bitmap管理 |
Uniform Size 1GB | 1st level bmb | 8,292 | 65 | 8 |
| data block | 2,850 | 37 | 13 | ||
| segment header | 948 | 7 | 7 | ||
| undo header | 127 | 0 | 3 | ||
| 2nd level bmb | 115 | 0 | 3 | ||
首先可以确认到上述表中发生了LevelⅠBMB(1st Level bmb)的等待。在Uniform Size 1GB中制成段时,用1个LevelⅠBMB管理256个数据块的空闲区域free extent时(跟块尺寸无关)。通过这次的插入处理,至今还没有使用的数据块就会变成空白,就会更新管理这些项目的LevelⅠBMB的bitmap的架构。这时就会发生等待。需要更新LevelⅠBMB以及段头 (LevelⅢBMB)。可以在上表中确认这些等待。
下面是Enqueue Activity相关内容的表7.1.1-2。
* 表 7.1.1-2 bitmap管理/Uniform Size 1GB中的Enqueue activity
| Enqueue activity | ||||||||
| 段管理方法 | extent管理方法 | Enqueue | Requests | Succ Gets | Failed Gets | Waits | Time (ms) | Time (s) |
| 自动 bitmap管理 |
Uniform Size 1GB | FB | 15,527 | 15,527 | 0 | 2,787 | 158.1 | 441 |
| HW | 7,053 | 836 | 6,217 | 600 | 16.98 | 10 | ||
| US | 37 | 37 | 0 | 6 | 10.5 | 0 | ||
上述表中作为Enqueue的Activity的上位可以观察到FB以及HW。FB是指数据块的格式。插入时进程将通过LevelⅠBMB所指定的数据块以及不超过数据块相邻的extent的范围的多个块,同时进行格式化。作为FB Enquere终于有所提高了。
HW Enqueue是指高水位线的Enqueue。bitmap管理中,与free list管理不同的是其实际应用了Low HWM以及High HWM两种高水位线。此值分别在Low HWM以及High HWM各自特定的条件下进行更新时,请注意两种合计值。
那么这次请关注free list、free list集群的Buffer busy waits。
* 表 7.1.1-3 free list管理/Uniform Size 1GB中的Buffer busy waits
| Buffer busy waits | |||||
| 段管理方法 | extent管理方法 | Class |
Waits |
Tot Wait Time (s) |
Avg Time (ms) |
| 手动 free list20 free list集群4 |
Uniform Size 1GB | free list | 8,281 | 63 | 8 |
在bitmap管理时,LevelⅠBMB 中发生了free list的Wait
Waits的数据以及几乎没有差异的结果 (请参考上述表7.1.1-1)。
Enqueue activity中又是怎样的情况呢。
* 表 7.1.1-4 free list管理/Uniform Size 1GB中的Enqueue activity
| Enqueue activity | ||||||||
| 段管理方法 | extent管理方法 | Enqueue | Requests | Succ Gets | Failed Gets | Waits | Time (ms) | Time (s) |
| 手动 free list20 free list・group4 |
Uniform Size 1GB | HW | 40,061 | 40,061 | 0 | 8242 | 29.47 | 243 |
| US | 35 | 35 | 0 | 5 | 8.2 | 0 | ||
bitmap管理时没有发生之前发生过的FB Enqueue,由于插入处理HWM上升了。HW Enqueue也上升了。
总而言之,使用自动段区域管理时,在Buffer busy waits、Enqueue activity两方面中都会记录新的项目。请在通过STATSPACK报告调优时注意这点。
bitmap管理中的extent管理Autoallocate的性能恶化
通过bitmap管理空闲区域,通过Autoallocate管理extent时,比起其他管理方法,处理时间大约恶化了7%。请大家注意Buffer busy waits。
表 7.1.2-1 bitmap管理/Autoallocate中的Buffer busy waits
首先,比起上文中的《表 7.1.1-1 bitmap管理/Uniform Size 1GB》中的Buffer busy wait,请注意LevelⅠBMB、data block 、segment header、LevelⅡBMB中所有数值都大幅增加了。
通过Autoallocate 管理extent时,create table语句的storage语句中没有指定任何initial的值时,作为初始extent,就会分配到64kb。在64K的段中,1个LevelⅠBMB管理着16个数据块的空白状态(与块尺寸无关)。如上文《7.1.1bitmap管理与free list管理的比较》中所述,通过Uniform Size 1GB管理extent时,1个LevelⅠBMB管理着256个数据块的空白状态。这个段尺寸中的地址指定能力的差异是指,将同样数量的数据插入表时,如果所使用的数据块数相同的话, Autoallocate比Uniform Size 1GB数量要更多,就需要更多的LevelⅠBMB。通过Autoallocate制成段之后,确认了LevelⅡBMB的转储之后,在制成段时,就会分配到2个LevelⅠBMB (对此,Uniform Size 1GB中,制成段后分配到了2169个LevelⅠBMB)如此次测试所示,重新大量使用数据块时,仅凭2个LevelⅠBMB是无法管理所有数据块的空白状态的。于是就需要大量追加新建LevelⅠBMB。
追加新建LevelⅠBMB是指,bitmap・块部的格式以及追加对应的LevelⅡBMB,以及造成大部分段头(LevelⅢBMB)的更新。另外,在由于bitmap块而分配到的区域中,就会追加新建的LevelⅠBMB。还可能会发生这样的情况:无法储存这些bitmap块,在分配extent时,新建的bitmap块就可以获得多种bitmap块结构。表7.1.2-1的值为追加这些新建的LevelⅠBMB、LevelⅡBMB,更新段头(LevelⅢBMB),是反映了制成新建的bitmap块的结果。
那么Enqueue activity的情况又怎样呢?
* 表 7.1.2-2 bitmap管理/Autoallocate中的Enqueue activity
| Enqueue activity | ||||||||
| 段管理方法 | extent管理方法 | Enqueue | Requests | Succ Gets | Failed Gets | Waits | Time (ms) | Time (s) |
| 自动 bitmap管理 |
Autoallocate | FB | 17,302 | 17,302 | 0 | 4,411 | 134.39 | 593 |
| HW | 15,822 | 2,014 | 13,808 | 1,262 | 34.17 | 43 | ||
| TX | 201,149 | 201,149 | 0 | 726 | 65.62 | 48 | ||
| US | 40 | 40 | 0 | 9 | 19.44 | 0 | ||
在此,作为Enqueue activity,请注意产生TX(事务日志)。产生事务日志的理由有以下几条,特别需要注意通过Autoallocate管理extent时,因为执行create table语句的storage语句时,没有指定任何initial值,所以就分配到了过小的64k的extent。
bitmap管理中对于没有使用的数据块的格式,在多个进程同时执行插入处理时,各进程中独立执行的机制。各个进程将通过哈希算法指定的DBA作为起点,由此对不超过extent范围的相邻的16个块进行格式化。换言之,通过1个进程可以格式化32KB的区域(16块X手机块尺寸2KB=32KB)。通过Autoallocate分配的extent的尺寸是指,段尺寸超过1MB。实际上是对20个客户端中的未使用过的块进行格式化,为了执行插入处理至少需要640KB的区域(20客户端X16块X数据块尺寸2KB=640KB)(段头等区域实际上不够640KB)就会分配到64KB这个较少的尺寸。因此,就会执行块的格式化,这就是TX Enqueue增多的原因。
那么使用free list、free list・group 管理时的Autoallocate中的Buffer busy waits以及Enqueue Activity的情况又是怎样的呢?
* 表 7.1.2-3 free list管理/Autoallocate中的Buffer busy waits
| Buffer busy waits | |||||
| 段管理方法 | extent管理方法 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 手动manual free list20 free list・group4 |
Autoallocate | free list | 8,439 | 67 | 8 |
| segment header | 4 | 0 | 0 | ||
* 表 7.1.2-4 free list管理/Autoallocate中的Enquue Activity
| Enqueue activity | ||||||||
| 段管理方法 | extent管理方法 | Enqueue | Requests | Succ Gets | Failed Gets | Waits | Time (ms) | Time (s) |
| 手动manual free list20 free list・group4 |
Autoallocate | HW | 40,196 | 40,196 | 0 | 8,578 | 52.65 | 452 |
| US | 42 | 42 | 0 | 11 | 9.18 | 0 | ||
与bitmap管理时不同,在free list管理中理所当然的事情,在FB Enqueue中并不会发生。因此,并不会发生bitmap管理时会发生的日志等待
总而言之,在bitmap管理时通过Atoallocate分割extent时,如果不指定注意到同时执行事务数的initial值的话,就可能对性能造成较大影响(在指定了initial时,就会提前分配到对应尺寸的多个extent, LevelⅠBMB的地址指定能力也可以分配到对应尺寸的项目)。在制成段时,如果正确指定了storage语句,请通过Uniform Size来进行extent管理。
更新(Update)处理
下表7.1-3是在将column C_2的列数据长1,460bytes更新为NULL时,所需要的处理时间以及CPU平均使用率的结果一览。
*表7.1-3 SI中的更新处理結果(无索引、将column C_2的列数据长1,460bytes更新为NULL
| 段管理方法 | extent管理方法 | 有没有索引 | 处理 | 处理时间 | CPU平均 使用率 (%usr+%sys) |
| 自动 bitmap管理 |
Autoallocate | 没有 | Update
1,460byts→Null |
2,172秒 (36分12秒) |
46% |
| 自动 bitmap管理 |
Uniform Size 1GB | 没有 | Update
1,460byts→Null |
2,158秒 (35分58秒) |
47% |
| 手动manual free list20 free list・group4 |
Autoallocate | 没有 | Update
1,460byts→Null |
2,167秒 (36分07秒) |
44% |
| 手动manual free list20 free list・group4 |
Uniform Size 1GB | 没有 | Update
1,460byts→Null |
2,166秒 (36分06秒) |
46% |
如上图所示,在SI环境中,将不使用索引的列数据长1,460bytes更新成NULL时所需要的处理时间是指free list管理中,几乎由于没有extent的差异造成的影响。比起管理free list时的处理时间,bitmap管理时的处理时间几乎都不到1%,人们几乎感觉不到有变化。
那么同样的处理中,使用索引的情况又是怎样的呢?
*表7.1-4 SI中的更新处理結果(有索引、将column C_2的列数据長1,460bytes更新成NULL)
| 段管理方法 | extent管理方法 | 有无索引 | 处理 | 处理时间 | CPU平均 使用率 (%usr+%sys) |
| 自动 bitmap管理 |
Autoallocate | 有 | Update
1,460bytes→Null |
215秒 (3分35秒) |
54% |
| 自动 bitmap管理 |
Uniform Size 1GB | 有 | Update
1,460bytes→Null |
200秒 (3分20秒) |
54% |
| 手动manual free list20 free list・group4 |
Autoallocate | 有 | Update
1,460bytes→Null |
205秒 (3分25秒) |
54% |
| 手动manual free list20 free list・group4 |
Uniform Size 1GB | 有 | Update
1,460bytes→Null |
205秒 (3分25秒) |
56% |
比较是否使用索引的情况时,发现处理时间减少了十分之一。另外,使用索引时,在freelist的管理红可以看到extent管理中处理时间的差异。对应的,bitmap管理中使用Autoallocate时,比起free list管理,处理速度大约恶化5%。反而Uniform Size 1GB提高了5%的处理速度。虽说如此,不过只是时间差正负5秒以内的结果而已。
这次,我们来观察将C_2的值,从NULL更新成1460bytes时的情况。
*表7.1-5 SI中的更新处理結果(没有索引、将columnC_2的Null値的列数据长更新为1,460bytes)
| 段管理方法 | extent管理方法 | 有没有索引 | 处理 | 处理时间 | CPU平均 使用率 (%usr+%sys) |
| 自动 bitmap管理 |
Autoallocate | 没有 | Update
Null→1,460bytes |
1,297秒 (21分37秒) |
41% |
| 自动 bitmap管理 |
Uniform Size 1GB | 没有 | Update
Null→1,460bytes |
1,270秒 (21分10秒) |
44% |
| 手动manual free list20 free list・group4 |
Autoallocate | 没有 | Update
Null→1,460bytes |
1,240秒 (20分40秒) |
44% |
| 手动manual free list20 free list・group4 |
Uniform Size 1GB | 没有 | Update
Null→1,460bytes |
1,235秒 (20分35秒) |
46% |
这次的结果中,free list管理比起bitmap管理,通过Autoallocate 管理extent要快4%左右,通过Uniform Size 1GB来管理时要快3%。
这次我们也观察到,由于extent的管理方法不同,造成了明显的差距。Bitmap管理中, Autoallocate比Uniform Size 1GB大约会慢2%左右。这是全盘扫描时必须读入的
LevelⅠBMB总量,Autoallocate要更多。
同样的处理中使用索引的情况又是怎样的呢?。
*表7.1-6 SI中的更新处理結果(有索引、将columnC_2的Null値的列数据长更新为1,460bytes)
| 段管理方法 | extent管理方法 | 索引の
有無 |
处理 | 处理时间 | CPU平均 使用率 (%usr+%sys) |
| 自动 bitmap管理 |
Autoallocate | 有 | Update
Null→1,460bytes |
146秒 (2分26秒) |
70% |
| 自动 bitmap管理 |
Uniform Size 1GB | 有 | Update
Null→1,460bytes |
189秒 (3分09秒) |
57% |
| 手动manual free list20 free list・group4 |
Autoallocate | 有 | Update
Null→1,460bytes |
165秒 (2分45秒) |
63% |
| 手动manual free list20 free list・group4 |
Uniform Size 1GB | 有 | Update
Null→1,460bytes |
164秒 (2分44秒) |
62% |
首先是处理时间,比起不使用索引的情况,大约缩短了八分之一。这次是bitmap管理中,通过Autoallocate管理extent的情况比free list管理要提高了大约13%处理时间。反之,通过Uniform Size 1GB管理extent时,比bitmap大约慢了15%。这是因为管理一个bitmap块的DBA越少需要空闲区域free extent时的搜索算法的性能就越能提高。
那么,这次让我们分别从各自的STATSPACK来进行验证吧。
– Top 5 Wait Events (更新处理-SI环境)
各案例的更新处理中的STATSPACK的Top 5 Wait Events的一览如下所示
*表7.1-7 更新处理中的Top 5 Wait Events(没有索引、将columnC_2的Null値的列数据长更新为1,460bytes)
因为储存数据的表中没有制成索引, Wait Events的top中db file scattered read就会上升,因此就会频繁发生db file sequential read。
*表7.1-8更新处理中的Top 5 Wait Events(有索引、将columnC_2的Null値的列数据长更新为1,460byte)
这次的bitmap管理中使用Autoallocate时,Wait Events「Library cache load lock」也会出现。会话为了加载数据基础对象,试着搜索加载日志。就像其他进程无法加载同一个对象一样,加载模式通常是通过排他模式来获得的。加载日志繁忙时,会话直到可以使用为止,都会使得这个项目待机。发生「Library cache load lock」的原因如下所示。
・解析过度
– 不共享的SQL
– 发行了不必要的解析call
– 没有使用绑定变量
・共享SQL被age-out(解除分配)了
– 共享池尺寸不合适
・共享池中无法保持较大的PL/SQL对象
・ 通过变更以及重编译,使得依赖于这个对象的对象无效化
这次更新测试时所执行的SQL语句,对应搜索关键词的种类有200个。这些都没有共享。因为使用了同样的客户端程序,在bitmap管理中,除了指定了Autoallocate的情况以外,如果发生了这个问题,就不会上升到Top 5 Wait Event。
*表7.1-9更新处理中的Top 5 Wait Events(没有索引、将columnC_2的Null値的列数据长更新为1,460bytes)
储存数据的表中因为没有展开索引,就会上升Wait Events的top中db file scattered read。另外,由于同样的理由,还会导致频繁发生db file sequential read。
*表7.1-10 更新处理中的Top 5 Wait Events(有索引、将columnC_2的Null値的列数据长更新为1,460bytes)
所有的案例中,作为wait的top,enqueue就会上升。各自的Enqueue Activity如下所示。
*表7.1-11 更新处理中的Enqueue Activity(有索引、将columnC_2的Null値的列数据长更新为1,460bytes)
| Enqueue activity | ||||||||||
| 段管理方法 | extent管理方法 | 索引の 有無 |
处理 | Enqueue | Requests | Succ Gets | Failed Gets | Waits | Time (ms) | Time (s) |
| 自动 bitmap管理 |
Autoallcoate | 有 | Update Null→1,460bytes |
FB | 23,208 | 23,208 | 0 | 10,182 | 70.64 | 719 |
| HW | 55,438 | 2,054 | 53,384 | 1,527 | 113.36 | 173 | ||||
| TX | 1,197 | 1,197 | 0 | 620 | 25.34 | 16 | ||||
| US | 44 | 44 | 0 | 34 | 11.38 | 0 | ||||
| 自动 bitmap管理 |
Uniform Size 1GB | 有 | Update Null→1,460bytes |
FB | 17,110 | 17,110 | 0 | 4,426 | 161.76 | 716 |
| HW | 5,892 | 824 | 5,068 | 728 | 381.24 | 278 | ||||
| 手动manual free list20 free list・group4 |
Autoallcoate | 有 | Update Null→1,460bytes |
HW | 41,629 | 41,629 | 0 | 35,560 | 53.51 | 1,903 |
| US | 32 | 32 | 0 | 1 | 30 | 0 | ||||
| 手动manual free list20 free list・group4 |
Uniform Size 1GB | 有 | Update Null→1,460bytes |
HW | 40,030 | 40,030 | 0 | 34,652 | 57.27 | 1,985 |
| US | 14 | 14 | 0 | 4 | 36 | 0 | ||||
通过bitmap管理Autoallocate的组合中,产生TX(事务日志)的理由请参考前文中的「▼插入(Insert)处理」的《7.1.2 bitmap管理中的extent管理Autoallocate的性能恶化》。
7.1.3 bitmap管理中的extent管理的差异导致的空闲区域free extent管理的影响
首先指定bitmap管理,通过Autoallocate以及Uniform Size来管理extent
* 表7.1.3-1 bitmap管理・更新处理・(没有索引、将columnC_2的Null値的列数据长更新为1,460bytes)
* 表7.1.3-2 bitmap管理・更新处理・有索引・Buffer busy waits(将columnC_2的Null値的列数据长更新为1,460bytes)
*表7.1.3-3bitmap管理・更新处理・没有索引・Buffer busy waits将columnC_2的Null値的列数据长更新为1,460bytes)
* 表7.1.3-4 bitmap管理・更新处理・有索引・Buffer busy waits(将columnC_2的Null値的列数据长更新为1,460bytes)
从表7.1.3-1到7.1.3-4中所有共通的可以观测到的点中,通过Autoallocate来管理extent的情况比使用Uniform Size 1GB的情况会产生更多的LevelⅠBMB等待。如前文所述,由于Autoallocate,会分配到一个较小的64kb的区域。另外,Autoallocate比Uniform Size 1GB分配到的LevelⅠBMB要多。LevelⅠBMB增加就代表追加LevelⅠBMB的数量以及更新段头(LevelⅠBMB)的信息。因此,Autoallocate比Uniform Size 1GB会发生更多的LevelⅡBMB以及段头的等待。
bitmap块总数会影响搜索时的性能。特别是在进行全盘扫描时,因为需要检测Low HWM与High HWM之间是否存在未格式化的块,就会需要读入所有的bitmap块。在这次的验证中,可以理解到表7.1-7、表7.1.3-1、表7.1.3-3的结果中反映出了这些问题
另外,将列数据长从1460 bytes更新为NULL时,需要更新LevelⅠBMB所保存空闲区域free extent的信息。因此,在类似处理中(可增加可以使用的空白块),跟是否存在索引无关,LevelⅠBMB数量较多的Autoallocate在处理上所需要的时间更多。
相对地,这次的验证中,我们也弄清楚了在将列数据长从NULL更新为1460 bytes的处理中,如何才能尽早找出可以储存数据的空白块,从而使得整体性能提高。同时进行多个DML中,减少bitmap块中的竞争的最佳方法就是增加bitmap块数。然后,发现Autoallocate满足这个条件。在这样的条件中,使用全盘搜索以及不同的索引时,在bitmap管理中找出可以使用的空白块的搜索算法的效率比使用freelist的效率更高。另外,观察表7.1-11,可以发现bitmap管理中使用Autoallocate的话,块在格式化时,作为Enqueue,tx(事务日志)也会上升。基于此,在制成段时的storage句中,指定合适的initial或者设定合适的Uniform Size的话,可能性能就可以进一步提高。
总结上述内容的话,DSS系等同时进行多个DML中发生全盘扫描时,根据bitmap块的数量(特别是LevelⅠBMB的数量)对应的I/O也会增加,造成处理速度降低但是,提高设定并行DM+,就可以减少成本。相对的,使用索引时,在bitmap块总数较多的案例中,需求空白块的竞争也会大幅减少,从结果上来说提高了性能。特别是OLTP中,因为不进行全表扫描,所以bitmap管理比freelist管理更好。
但是,为了确保大部分的bitmap块,提高减少extent的尺寸,可能会发生TX Enqueue,所以需要考虑到同时执行用户数,指定合适的Uniform Size,另外,在Autoallocate中制成段时,请使用合适的initial值来明确进行分配。
7.1.4 free list、free list・group中的extent管理差异中的空闲区域free extent管理性能
与上文的7.1.3相同,请注意extent管理中指定Autoallocate与Uniform Size时的Buffer busy waits的值。
* 表 7.1.4-1free list管理・更新处理・没有索引・Buffer busy waits(将columnC_2的Null値的列数据长更新为1,460bytes)
| Buffer Busy Waits | |||||||
| 段管理方法 | extent管理方法 | 有没有索引 | 处理 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 手动manual free list20 free list・group4 |
Autoallocate | 没有 | Update 1,460bytes→Null |
data block | 1761388 | 4621 | 3 |
| undo block | 5897 | 58 | 10 | ||||
| free list | 2889 | 7 | 3 | ||||
| undo header | 244 | 1 | 4 | ||||
| 手动manual free list20 free list・group4 |
Uniform Size 1GB | 没有 | Update 1,460bytes→Null |
data block | 1713767 | 4443 | 3 |
| undo block | 5111 | 47 | 9 | ||||
| free list | 2592 | 7 | 3 | ||||
| undo header | 200 | 1 | 3 | ||||
*表 7.1.4-2 free list管理・更新处理・有索引・Buffer busy waits将columnC_2的Null値的列数据长更新为1,460bytes)
| Buffer Busy Waits | |||||||
| 段管理方法 | extent管理方法 | 有没有索引 | 处理 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 手动manual free list20 free list・group4 |
Autoallocate | 有 | Update 1,460bytes→Null |
free list | 9293 | 29 | 3 |
| 手动manual free list20 free list・group4 |
Uniform Size 1GB | 有 | Update 1,460bytes→Null |
free list | 9024 | 30 | 3 |
*表 7.1.4-3free list管理・更新处理・没有索引・Buffer busy waits(将columnC_2的Null値的列数据长更新为1,460bytes)
| Buffer Busy Waits | |||||||
| 段管理方法 | extent管理方法 | 有没有索引 | 处理 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 手动manual free list20 free list・group4 |
Autoallocate | 没有 | Update Null→1,460bytes |
data block | 933325 | 2395 | 3 |
| free list | 20166 | 25 | 1 | ||||
| undo block | 240 | 2 | 7 | ||||
| segment header | 93 | 0 | 3 | ||||
| undo header | 15 | 0 | 3 | ||||
| 手动manual free list20 free list・group4 |
Uniform Size 1GB | 没有 | Update Null→1,460bytes |
data block | 996902 | 2482 | 2 |
| free list | 14706 | 12 | 1 | ||||
| undo block | 248 | 2 | 9 | ||||
| undo header | 30 | 0 | 4 | ||||
| segment header | 15 | 0 | 1 | ||||
*表 7.1.4-4free list管理・更新处理・有索引・Buffer busy waits(将columnC_2的Null値的列数据长更新为1,460bytes)
| Buffer Busy Waits | |||||||
| 段管理方法 | extent管理方法 | 有没有索引 | 处理 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 手动manual free list20 free list・group4 |
Autoallocate | 有 | Update Null→1,460bytes |
free list | 24828 | 36 | 1 |
| segment header | 130 | 0 | 1 | ||||
| data block | 45 | 0 | 2 | ||||
| undo header | 1 | 0 | 0 | ||||
| 手动manual free list20 free list・group4 |
Uniform Size 1GB | 有 | Update Null→1,460bytes |
free list | 25897 | 37 | 1 |
如上述表7.1.4-1到7.1.4-4所示,与7.1.3中验证过的空闲区域free extent管理时不同,在freelist管理中,extent的分配方法并不会受到太大影响。
▼删除(Delete)处理
下述表7.1-12以及表7.1-13是表示删除处理所需要的时间以及CPU平均使用率。
*表7.1-12 SI中的删除处理結果(没有索引)
| 段管理方法 | extent管理方法 | 有没有索引 | 处理 | 处理时间 | CPU平均 使用率 (%usr+%sys) |
| 自动 bitmap管理 |
Autoallocate | 没有 | Delete | 2,193秒 (36分33秒) |
46% |
| 自动 bitmap管理 |
Uniform Size 1GB | 没有 | Delete | 2,164秒 (36分04秒) |
46% |
| 手动manual free list20 free list・group4 |
Autoallocate | 没有 | Delete | 2,171秒 (36分11秒) |
46% |
| 手动manual free list20 free list・group4 |
Uniform Size 1GB | 没有 | Delete | 2,176秒 (36分16秒) |
45% |
首先这是bitmap管理中的extent管理的差异,Autoallocate比Uniform Size 1GB大约多需要1%的处理时间。在管理中,extent管理之差是指插入处理与更新处理性能完全相同。空闲区域free extent管理之差是指bitmap管理与freelist之间只有1%的差异。
那么,同样的处理中,使用索引的情况又是怎样呢?
*表7.1-13 SI中的删除处理結果(有索引)
| 段管理方法 | extent管理方法 | 有没有索引 | 处理 | 处理时间 | CPU平均 使用率 (%usr+%sys) |
| 自动 bitmap管理 |
Autoallocate | 有 | Delete | 200秒 (3分20秒) |
53% |
| 自动 bitmap管理 |
Uniform Size 1GB | 有 | Delete | 205秒 (3分25秒) |
54% |
| 手动manual free list20 free list・group4 |
Autoallocate | 有 | Delete | 206秒 (3分26秒) |
56% |
| 手动manual free list20 free list・group4 |
Uniform Size 1GB | 有 | Delete | 200秒 (3分20秒) |
61% |
使用索引时,比起不使用索引,处理时间缩短了约10%。
另外,在bitmap管理中, Autoallocate比Uniform Size 1GB提高了3%的处理时间。相对的,在free list管理中,Uniform Size 1GB大约打稿了3%左右的处理时间。虽是如此,两者之间最打差异也才正负6秒,人几乎感受不到有什么变化。空闲区域free extent管理方法的差异,这次没有得到明确的确认。
那么Top 5 Wait Events又是怎样的呢?
* 表7.1.-14 删除处理中的Top 5 Wait Events(没有索引)
因为更新处理中没有制成表以及索引,所以Wait Events中频繁发生db file scattered read以及db file sequential read。
然后记录同样的删除处理中的使用索引的Top 5 Wait Events。
表7.1-15 删除处理中的Top 5 Wait Events(有索引)
通过有效使用所以,可以在Wait Events中减少db file scattered read的发生。
7.1.5 bitmap管理中的extent管理差异导致的性能差异
使用bitmap管理空闲区域free extent,指定Autoallocate进行extent管理时,请注意 Buffer busy waits以及、Uniform Size 1GB的Buffer busy waits。讨论作为最开始的比较没有使用索引的情况。
* 表7.1.5-1 bitmap管理・删除处理・没有索引・Autoallocate中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent管理
方法 |
有没有索引 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 自动 bitmap管理 |
Autoallocate | 没有 | data block | 1759107 | 6177 | 4 |
| undo block | 5405 | 78 | 15 | |||
| 1st level bmb | 3735 | 11 | 3 | |||
| extent map | 12 | 3 | 279 | |||
| undo header | 411 | 2 | 5 | |||
| 2nd level bmb | 6 | 0 | 7 | |||
| file header block | 1 | 0 | 30 | |||
*表7.1.5-2 bitmap管理・删除处理・没有索引・Uniform Size 1GB中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent管理
方法 |
有没有索引 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 自动 bitmap管理 |
Uniform Size 1GB | 没有 | data block | 1822995 | 5654 | 3 |
| undo block | 4828 | 58 | 12 | |||
| undo header | 398 | 2 | 4 | |||
| 1st level bmb | 907 | 2 | 2 | |||
LevelⅠBMB的waits数的差异以及Autoallocate管理中,LevelⅡ不会上升,这在上文的《7.1.3bitmap管理中extent管理的差异造成的空闲区域free extent管理的差异》中说明过了。
伴随着LevelⅠBMB数量的增大,现有的bitmap块就会出现容量不足,所以需要采用多bitmap块结构。删除时,为了避免extent map的资源竞争。还是应该在制成段时指定合适的initial,或者指定合适的Uniform Size。
下面的内容是使用了索引时的情况的结果。
* 表7.1.5-3 bitmap管理・删除处理・有索引・Autoallocate中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent管理
方法 |
索引の
有無 |
Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 自动 bitmap管理 |
Autoallocate | 有 | 1st level bmb | 4,073 | 22 | 5 |
| 2nd level bmb | 7 | 0 | 13 | |||
| file header block | 2 | 0 | 0 | |||
| segment header | 1 | 0 | 0 | |||
* 表7.1.5-4 bitmap管理・删除处理・有索引・Uniform Size 1GB中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent管理
方法 |
索引の
有無 |
Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 自动 bitmap管理 |
Uniform Size
1GB |
有 | 1st level bmb | 9,889 | 47 | 5 |
没有使用索引时就会频繁发生数据块的等待。另外,Autoallcoate中的extent map竞争也会消失。另外,Uniform Size 1GB中只会增加LevelⅠBMB的waits。
总结以上几点,为了在bitmap管理中获得更好的性能,需要指定考虑到同时执行用户数的合适的Uniform Size,或者在Autoallocate中提前预分配extent,根据实际情况使用索引。
7.1.6 free list、free list・group管理中的extent管理差异中空闲区域free extent管理的性能
下面表的内容为free list管理中的Autoallocate以及Uniform Size 1GB的Buffer busy waits。
* 表7.1.6-1 free list管理・删除处理・没有索引・Autoallocate中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent
管理方法 |
索引の
有無 |
Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 手动manual free list20 free list・group4 |
Autoallocate | 没有 | data block | 1783121 | 5536 | 3 |
| undo block | 6814 | 59 | 9 | |||
| free list | 3128 | 8 | 2 | |||
| undo header | 344 | 1 | 3 | |||
| file header block | 9 | 0 | 43 | |||
* 表7.1.6-2 free list管理・删除处理・没有索引・Uniform Size1GB中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent
管理方法 |
索引の
有無 |
Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 手动manual free list20 free list・group4 |
Uniform Size
1GB |
没有 | data block | 1683652 | 5700 | 3 |
| undo block | 5729 | 57 | 10 | |||
| free list | 2949 | 9 | 3 | |||
| undo header | 227 | 1 | 5 | |||
更新处理时也得到了同样的结果,与bitmap管理时不同,由于extent管理方法的差异,freelist的等待并没有什么差异,那么使用索引时又是怎样的情况呢?
* 表 7.1.6-3 free list管理・删除处理・没有索引・Autoallocate中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent
管理方法 |
有没有索引 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 手动manual free list20 free list・group4 |
Autoallocate | 有 | free list | 10,229 | 31 | 3 |
* 表 7.1.6-4 free list管理・删除处理・有索引・Uniform Size1GB中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent
管理方法 |
有没有索引 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 手动manual free list20 free list・group4 |
Uniform Size
1GB |
有 | free list | 11,559 | 37 | 3 |
使用索引时,之前没有使用时的几个等待就会消失,就会变成发生freelist的等待。比较两个等待我们可以看出,extent管理方法不同几乎没有造成什么影响。
总结起来就是,由于删除处理增加了一些可以使用的新的空闲区域free extent的情况。如果限定在SI环境中的话,bitmap管理与freelist管理之间并没有明显的差异。实际上,这也同样证明了将上文中所示的1460bytes更新为NULL的处理中,也会得到同样的结果。
但是提高bitmap管理空闲区域free extent时,请不要使用合适的extent尺寸,可能会使得性能恶化。
▼结论 (SI环境)
由上述验证结果,提高bitmap管理SI环境中的空闲区域free extent时,与使用free list、free list・group管理的差异如下所示。
- 由于插入、更新处理,从而使用新的数据块在管理空闲区域free extent的案例中,bitmap管理以及freelist管理之间,并没有发现显著性能差异。
- 通过更新、删除处理来增加新的可以使用的空闲区域free extent的案例中,也并没有发现显著的性能差异。
- Bitmap管理时,bitmap块数会影响搜索时的性能。全盘搜索时,bitmap块数也与成本紧密相关。设定并行查询以及并行DML可以减少成本。在同时执行多个DML,为了找出可以使用的空闲区域free extent的搜索处理中,通过大部分bitmap块可以会被管制,所以性能较高。
- bitmap管理中通过Autoallocate管理extent时,在制成段时,没有在storage语句中指定合适的initial值的话,根据同时执行用户数以及所使用的数据长度,就会发事务日志以及性能恶化。请指定合适的initial值或者使用Uniform Size管理extent。
- 用freelist以及freelist group管理时,由于extent管理方法的差异,对性能的影响也较小。
- Bitmap管理、freelist管理以及freelist group管理之间基本没有明显的性能差异。但从管理方面以及区域使用效率的角度来看的话,还是使用bitmap管理较好。
- 总之迁移到RAC中在可以预测的系统中,需要讨论bitmap管理。(详细内容请参考后文中的RAC)
7.2 Real Application Clusters(RAC)环境
▼插入(Insert)处理
下表7.2-1是RAC环境中的插入处理所需要的时间以及CPU平均使用率的结果。
*表7.2-1 RAC环境中的插入处理結果
| 段管理方法 | extent管理方法 | 处理 | 实例 | 处理时间 (単体) |
处理时间 (合计) |
CPU平均 使用率(%usr+%sys) |
| 自动 bitmap管理 |
Autoallocate | Insert | #1 | 403秒
(6分43秒) |
409秒
(6分49秒) |
47% |
| #2 | 407秒
(6分47秒) |
47% | ||||
| 自动 bitmap管理 |
Uniform Size 1GB | Insert | #1 | 411秒
(6分51秒) |
411秒
(6分51秒) |
51% |
| #2 | 383秒
(6分23秒) |
47% | ||||
| 手动manual free list20 free list・group4 |
Autoallocate | Insert | #1 | 583秒
(9分43秒) |
583秒
(9分43秒) |
35% |
| #2 | 370秒
(6分10秒) |
48% | ||||
| 手动manual free list20 free list・group4 |
Uniform Size 1GB | Insert | #1 | 397秒
(6分37秒) |
657秒
(10分57秒) |
44% |
| #2 | 657秒
(10分57秒) |
34% |
首先是处理时间(単体)与处理时间(合计)的相关内容。这是在各实例中同时开始处理时,每个实例完成处理所需要的时间,并且所有的实例直到所有处理完成所需要的时间。要说为什么要分成两部分来说明的话,是因为在容易发生竞争的RAC环境中,单侧节点处理优先执行,这时其他的资源都在持续等待,结果就是每个实例完成所需要的时间。
基于以上几点,重新观察上表结果的话,总计所需要的处理时间,bitmap管理比freelist一级freelist group管理要快多了。Autoallocate要快30%,Uniform Size 1GB要快48%左右,bitmap管理整体处理所需要的时间更少。
另一方面,各自的单体处理中,bitmap中的实例#1与实例#2之间处理时间又较大差距,对于较早完成的实例,其他实例会大概浪费约37%-39%左右的时间。
我还想通过STATSPACK来进行验证。
– Top 5 Wait Events (插入处理– RAC环境)
下表展示了RAC环境中的插入处理时的STATSPACK的Top 5 Wait Eventsで示す。
*表7.2-2 RAC环境・插入处理中的Top 5 Wait Events
| Top 5 Wait Events | ||||||
| 段管理方法 | extent管理方法 | 实例 | Event | Waits | Wait Time(s) | %Total Wt Time |
| 自动 bitmap管理 |
Autoallocate (Default) |
#1 | enqueue | 8508 | 990 | 25.06 |
| free buffer waits | 1060 | 479 | 12.11 | |||
| latch free | 29245 | 454 | 11.49 | |||
| ges remote message | 195791 | 454 | 11.48 | |||
| buffer busy due to global cache | 12472 | 259 | 6.56 | |||
| #2 | enqueue | 9268 | 817 | 19.07 | ||
| free buffer waits | 1588 | 643 | 15.01 | |||
| ges remote message | 234394 | 626 | 14.61 | |||
| latch free | 33073 | 517 | 12.07 | |||
| buffer busy due to global cache | 17280 | 413 | 9.65 | |||
| 自动 bitmap管理 |
Uniform Size 1GB | #1 | enqueue | 7368 | 755 | 20.6 |
| free buffer waits | 1133 | 610 | 16.62 | |||
| ges remote message | 186236 | 415 | 11.32 | |||
| latch free | 24662 | 372 | 10.15 | |||
| log file sync | 49313 | 333 | 9.08 | |||
| #2 | free buffer waits | 1037 | 453 | 12.88 | ||
| log file sync | 47991 | 438 | 12.47 | |||
| enqueue | 6212 | 437 | 12.45 | |||
| ges remote message | 180194 | 432 | 12.28 | |||
| latch free | 26076 | 403 | 11.48 | |||
*表7.2-2 RAC环境・插入处理中的Top 5 Wait Events (続き)
| Top 5 Wait Events | ||||||
| 段管理方法 | extent管理方法 | 实例 | Event | Waits | Wait Time(s) | %Total Wt Time |
| 手动manualfree list20
free list・ group4 |
Autoallocate | #1 | enqueue | 30356 | 6622 | 75.84 |
| Ges remote message | 182976 | 740 | 8.47 | |||
| buffer busy waits | 15908 | 590 | 6.76 | |||
| log file sync | 46369 | 314 | 3.6 | |||
| latch free | 18774 | 276 | 3.16 | |||
| #2 | enqueue | 23396 | 2088 | 53.46 | ||
| Ges remote message | 201830 | 744 | 19.04 | |||
| buffer busy waits | 14733 | 415 | 10.62 | |||
| latch free | 18545 | 264 | 6.76 | |||
| log file sync | 46144 | 192 | 4.91 | |||
| 手动manual
free list20 free list・ group4 |
Uniform Size
1GB |
#1 | enqueue | 22268 | 2085 | 41.16 |
| Ges remote message | 190149 | 1513 | 29.86 | |||
| log file sync | 47795 | 487 | 9.62 | |||
| buffer busy waits | 15636 | 471 | 9.31 | |||
| latch free | 17865 | 258 | 5.08 | |||
| #2 | enqueue | 26271 | 7010 | 68 | ||
| Ges remote message | 178281 | 1528 | 14.82 | |||
| buffer busy waits | 17763 | 725 | 7.03 | |||
| log file sync | 48708 | 542 | 5.26 | |||
| latch free | 18322 | 258 | 2.5 | |||
7.2.1 RAC环境・插入处理時・bitmap管理中的extent管理差异造成的性能差异
表7.2-2的Top 5 Wait Events中需要注意的点在于通过Autoallocate分配extent比Uniform Size 1GB分配来说,Enqueue以及Ges remote message两方面等待值都会增加。Ges remote message的增加意味着节点之间的事务日志、表日志。Library cache、字典日志、mount日志都增加了。、Buffer busy waits变化如下所示。
* 表7.2.1-1 RAC环境・bitmap管理・Autoallocate・插入处理中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent管理方法 | 实例 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 自动 bitmap管理 |
Autoallocate | #1 | segment header | 10211 | 258 | 25 |
| 2nd level bmb | 3397 | 95 | 28 | |||
| 1st level bmb | 2089 | 54 | 26 | |||
| data block | 709 | 27 | 39 | |||
| undo header | 491 | 2 | 4 | |||
| undo block | 59 | 0 | 0 | |||
| #2 | segment header | 12264 | 330 | 27 | ||
| 2nd level bmb | 3144 | 153 | 49 | |||
| 1st level bmb | 5705 | 124 | 22 | |||
| data block | 875 | 21 | 23 | |||
| undo header | 853 | 3 | 4 | |||
| undo block | 57 | 0 | 1 | |||
* 表7.2.1-2 RAC环境・bitmap管理・Uniform Size 1GB・插入处理中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent管理方法 | 实例 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 自动 bitmap管理 |
Uniform Size 1GB | #1 | segment header | 9380 | 237 | 25 |
| 1st level bmb | 4134 | 60 | 15 | |||
| 2nd level bmb | 1766 | 47 | 27 | |||
| data block | 848 | 13 | 15 | |||
| undo header | 286 | 2 | 6 | |||
| undo block | 1 | 0 | 0 | |||
| #2 | segment header | 10370 | 284 | 27 | ||
| 1st level bmb | 3806 | 119 | 31 | |||
| 2nd level bmb | 1451 | 33 | 23 | |||
| data block | 785 | 22 | 28 | |||
| undo header | 134 | 1 | 5 | |||
| undo block | 1 | 0 | 0 | |||
除去data block值,Autoallocate的所有Class中等待值都增加了。原因依旧是Autoallocate,在制成段时,没有在storage语句中指定合适的initial语句。因为默认的extent分配方法,初始会动态分配类似64K或1MB这样较小的extent尺寸。
我之前已经在「7.1.2 bitmap管理中的extent管理Autoallocate性能恶化」中阐述过了。Autoallocte为了管理空闲区域free extent,需求较多的LevelⅠBMB,并且,由于LevelⅠBMB增加引起了LevelⅡBMB比例増加。然后更新段头(LevelⅢBMB)的信息,这次验证中,并没有出现明确的性能差异,类似DSS等大规模处理数据的案例中,请通过这点来决定extent的分配方法。
下面记载着各自的Enqueue Activity。
* 表7.2.1-3 RAC环境・bitmap管理・Autoallocate・插入处理中的Enqueue activity
| Enqueue activity | |||||||||
| 段
管理方法 |
extent
管理方法 |
实例 | Enqueue | Requests | Succ Gets | Failed Gets | Waits | Time (ms) | Time (s) |
| 自动 bitmap管理 |
Autoallocate | #1 | FB | 7272 | 7272 | 0 | 4069 | 67.42 | 274 |
| HW | 3837 | 1870 | 1967 | 1849 | 351.4 | 650 | |||
| TX | 51285 | 51285 | 0 | 938 | 113.87 | 107 | |||
| TT | 717 | 717 | 0 | 104 | 1.99 | 0 | |||
| US | 52 | 52 | 0 | 52 | 6.13 | 0 | |||
| TS | 64 | 64 | 0 | 47 | 0.62 | 0 | |||
| CF | 826 | 826 | 0 | 27 | 1.93 | 0 | |||
| TM | 51527 | 51526 | 1 | 23 | 0.78 | 0 | |||
| ST | 68 | 68 | 0 | 6 | 926.33 | 6 | |||
| TA | 1 | 1 | 0 | 1 | 1 | 0 | |||
| #2 | FB | 7919 | 7919 | 0 | 4660 | 77.6 | 362 | ||
| HW | 1749 | 1555 | 194 | 1564 | 179.35 | 281 | |||
| TX | 51427 | 51427 | 0 | 1162 | 165.05 | 192 | |||
| TM | 51359 | 51356 | 3 | 724 | 0.81 | 1 | |||
| ST | 59 | 59 | 0 | 56 | 485.63 | 27 | |||
| TS | 55 | 55 | 0 | 4 | 1 | 0 | |||
| US | 178 | 178 | 0 | 3 | 32.33 | 0 | |||
| TD | 2 | 2 | 0 | 2 | 1 | 0 | |||
| DR | 1 | 1 | 0 | 1 | 2 | 0 | |||
Enqueue中缩写的意思如下所示。
CF: 控制文件事务
FB : 数据・块的格式化
HW: 高水位线入队
ST: 区域管理事务
TA: 事务恢复
TD:将 SCN以及时间进行mapping的入队(每5分钟发生一次)
TM: DML入队
TS: 临时段(包含表区域)
TT: 临时表
TX: 事务
US: 回滚(undo)・段
* 表7.2.1-4 RAC环境・bitmap管理・Uniform Size 1GB・插入处理中的Enqueue activity
Enqueue中缩写的意思如下所示。
CF: 控制文件事务
DR: 分散恢复
FB : 数据・块的格式化的格式化
HW: 高水位线入队
ST: 区域管理事务
TA: 事务恢复
TD:将 SCN以及时间进行mapping的入队(每5分钟发生一次)
TM: DML入队
TS: 临时段(包含表区域)
TT: 临时表
TX: 事务
FB Enqueue(数据块的格式化)的Waits由于extent管理的差异,似乎没有受到太大影响。相对的,HW Enqueue引起的waits中,Uniform Size 1GBの方比Autoallocate更多。这主要是由于Low HWM相邻的块被格式化了,导致Low HWM上升造成的影响。
总而言之,RAC环境中的bitmap管理,管理10万件的数据量时,extent管理不同造成的性能差异也不同。但是,Autoallocate中的LevelⅠBMB、LevelⅡBMB数量增加可能导致性能恶化。特别是动态分配extent时发生的LevelⅠBMB格式化会直接影响到性能。请一定要注意这点来对extent进行预分配。或者分配合适的Uniform Size。
7.2.2 RAC环境插入处理・free list、free list・group中的extent管理差异导致的性能差异
首先,请注意各自的Buffer busy waits。
* 表7.2.2-1 RAC环境free list管理・Autoallocate插入处理中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理方法 | extent管理方法 | 实例 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 手动manual free list 4 free list・group20 |
Autoallocate | #1 | free list | 15881 | 607 | 38 |
| undo block | 25 | 0 | 0 | |||
| data block | 2 | 0 | 0 | |||
| #2 | free list | 14719 | 430 | 29 | ||
| segment header | 10 | 0 | 2 | |||
| undo block | 3 | 0 | 3 | |||
| data block | 1 | 0 | 0 | |||
* 表7.2.2-2 RAC环境・free list管理・Uniform Size 1GB・插入处理中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理方法 | extent管理方法 | 实例 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 手动manual free list 4 free list・group20 |
Uniform Size 1GB | #1 | free list | 15628 | 486 | 31 |
| data block | 4 | 0 | 0 | |||
| undo block | 3 | 0 | 3 | |||
| undo header | 1 | 0 | 0 | |||
| #2 | free list | 17714 | 745 | 42 | ||
| undo block | 43 | 0 | 1 | |||
| data block | 6 | 0 | 0 | |||
* 表7.2.2-3 RAC环境・free list管理・Autoallocate・插入处理中的Enqueue Activity
| Enqueue activity | |||||||||
| 段
管理方法 |
extent
管理方法 |
实例 | Enqueue | Requests | Succ Gets | Failed Gets | Waits | Time (ms) | Time (s) |
| 手动manual free list 4 free list・group20 |
Autoallocate | #1 | HW | 20518 | 20518 | 0 | 19558 | 348.2 | 6810 |
| US | 94 | 94 | 0 | 93 | 1.8 | 0 | |||
| TT | 276 | 276 | 0 | 73 | 2.08 | 0 | |||
| CF | 1228 | 1228 | 0 | 29 | 2.07 | 0 | |||
| TM | 50254 | 50254 | 0 | 25 | 0.68 | 0 | |||
| TS | 19 | 19 | 0 | 17 | 0.59 | 0 | |||
| TX | 50165 | 50165 | 0 | 11 | 1 | 0 | |||
| TA | 2 | 2 | 0 | 2 | 1 | 0 | |||
| ST | 21 | 21 | 0 | 1 | 21 | 0 | |||
| #2 | HW | 21100 | 21100 | 0 | 21072 | 102.75 | 2165 | ||
| TM | 51910 | 51910 | 0 | 509 | 1.01 | 1 | |||
| ST | 80 | 80 | 0 | 75 | 0.89 | 0 | |||
| TX | 50393 | 50393 | 0 | 9 | 1 | 0 | |||
| US | 178 | 178 | 0 | 2 | 9.5 | 0 | |||
| TD | 2 | 2 | 0 | 2 | 1 | 0 | |||
| DR | 1 | 1 | 0 | 1 | 3 | 0 | |||
Enqueue中缩写的意思如下所示。
CF: 控制文件事务
FB : 数据・块的格式化
HW: 高水位线入队
ST: 区域管理事务
TA: 事务恢复
TD:将 SCN以及时间进行mapping的入队(每5分钟发生一次)
TM: DML入队
TS: 临时段(包含表区域)
TT: 临时表
TX: 事务
US: 回滚(undo)・段
* 表7.2.2-4. RAC环境・free list管理・Uniform Size1GB・插入处理中的Enqueue Activity
| Enqueue activity | |||||||||
| 段
管理方法 |
extent
管理方法 |
实例 | Enqueue | Requests | Succ Gets | Failed Gets | Waits | Time (ms) | Time (s) |
| 手动manual free list 4 free list・group20 |
Uniform Size
1GB |
#1 | HW | 20031 | 20031 | 0 | 20004 | 107.73 | 2155 |
| TM | 51416 | 51416 | 0 | 554 | 0.79 | 0 | |||
| ST | 62 | 62 | 0 | 61 | 0.89 | 0 | |||
| TX | 50249 | 50248 | 0 | 9 | 0.89 | 0 | |||
| TS | 57 | 57 | 0 | 7 | 0.57 | 0 | |||
| TD | 5 | 5 | 0 | 5 | 0.6 | 0 | |||
| US | 428 | 428 | 0 | 2 | 41.5 | 0 | |||
| DV | 4 | 4 | 0 | 1 | 1 | 0 | |||
| DR | 1 | 1 | 0 | 1 | 2 | 0 | |||
| #2 | HW | 20041 | 20041 | 0 | 20029 | 122.98 | 2463 | ||
| TM | 51777 | 51776 | 1 | 491 | 1.12 | 1 | |||
| ST | 87 | 87 | 0 | 85 | 10.27 | 1 | |||
| DV | 4 | 4 | 0 | 3 | 1 | 0 | |||
| TX | 50289 | 50289 | 0 | 2 | 9 | 0 | |||
| US | 176 | 176 | 0 | 2 | 6 | 0 | |||
| TD | 2 | 2 | 0 | 2 | 1 | 0 | |||
| DR | 1 | 1 | 0 | 1 | 2 | 0 | |||
Enqueue中缩写的意思如下所示。
CF: 控制文件事务
FB : 数据・块的格式化
HW: 高水位线入队
ST: 区域管理事务
TA: 事务恢复
TD:将 SCN以及时间进行mapping的入队(每5分钟发生一次)
TM: DML入队
TS: 临时段(包含表区域)
TT: 临时表
TX: 事务
US: 回滚(undo)・段
两者间,HW Enqeue就会上升到top中,两个实例中的合计的数值中,Autoallocate与Uniform Size 1GB之间没什么差异。
但是,仅限Uniform Size 1GB,作为新的入队,Diana Version(DV) Enqueue就会上升。这个DV入队本来就是在oracle共享池中读入PL/SQL程序时,但是实际上,发生这些情况时,大部分都是O/S水平异常或者其他原因(这次我们没有过多追究正确原因)
本文永久链接 https://www.askmac.cn/archives/oracle-free-space-managements-验证报告.html
总而言之,freelist管理中选择Autoallocate时,可能发生master空白列表竞争,另外指定较大尺寸的extent时,可能发生新的DV入队等。因此,插入处理中,比起使用freelist管理,使用bitmap性能要更好。
▼更新(Update)处理
下表7.2-3是RAC环境中进行更新处理时所需要的时间以及CPU平均使用率的结果一览
*表7.2-3 RAC环境中的更新处理結果(将column C_2列数据长从1460 bytes更新为NULL)
| 段
管理方法 |
extent
管理方法 |
处理 | 实例 | 处理时间 (単体) |
处理时间 (合计) |
CPU平均 使用率 (%usr+%sys) |
| 自动 bitmap管理 |
Autoallocate | Update | #1 | 1,064秒 (17分44秒) |
1,123秒 (18分43秒) |
55% |
| #2 | 1,123秒 (18分43秒) |
58% | ||||
| 自动 bitmap管理 |
Uniform Size
1GB |
Update | #1 | 1,204秒 (20分04秒) |
1,212秒 (20分12秒) |
58% |
| #2 | 1,147秒 (19分07秒) |
54% | ||||
| 手动manual free list 20 free list・group 4 |
Autoallocate | Update | #1 | 1,601秒 (26分41秒) |
1,601秒 (26分41秒) |
41% |
| #2 | 1,335秒 (22分15秒) |
49% | ||||
| 手动manual free list 20 free list・group 4 |
Uniform Size
1GB |
Update | #1 | 1,185秒 (19分45秒) |
1,185秒 (19分45秒) |
59% |
| #2 | 1,106秒 (18分26秒) |
55% |
处理时间(単体)以及处理时间(合计)请参考插入处理的项目。
合计的处理时间首先是在bitmap管理中通过Autoallocate来进行时,比起使用Uniform Size 1GB能提高8%左右的处理时间。另一方面,freelist管理中,反而是Uniform Size 1GB比Autoallocate的处理时间要快35%。
比较空闲区域free extent管理的差异时,Autoallocate管理方面,bitmap管理要比freelist管理要快42%。相对的,Uniform Size 1GB中freelist要快2%左右。
那么STATSOACK中又是怎样的情况呢?
*表7.2–4 RAC环境・更新处理中的Top 5 Wait Events(将column C_2列数据长从1460 bytes更新为NULL)
| Top 5 Wait Events | ||||||
| 段管理方法 | extent管理方法 | 实例 | Event | Waits | Wait Time(s) | %Total Wt Time |
| 自动 bitmap管理 |
Autoallocate (Default) |
#1 | global cache cr request | 606569 | 6435 | 31.37 |
| latch free | 260388 | 4490 | 21.89 | |||
| global cache s to x | 54703 | 3054 | 14.89 | |||
| buffer busy due to global cache | 98264 | 2804 | 13.67 | |||
| KJC: Wait for msg sends to complete | 1060413 | 1454 | 7.09 | |||
| #2 | global cache cr request | 770848 | 8457 | 39.38 | ||
| latch free | 273382 | 4886 | 22.75 | |||
| global cache s to x | 55372 | 2456 | 11.44 | |||
| buffer busy due to global cache | 56848 | 1855 | 8.64 | |||
| KJC: Wait for msg sends to complete | 1527438 | 1530 | 7.12 | |||
| 自动 bitmap管理 |
Uniform Size 1GB | #1 | global cache cr request | 796545 | 9068 | 39.53 |
| latch free | 276780 | 4729 | 20.62 | |||
| global cache s to x | 52125 | 2900 | 12.64 | |||
| buffer busy due to global cache | 63969 | 2233 | 9.73 | |||
| KJC: Wait for msg sends to complete | 1483038 | 1668 | 7.27 | |||
| #2 | global cache cr request | 702136 | 8111 | 36.57 | ||
| latch free | 264556 | 4724 | 21.3 | |||
| global cache s to x | 51774 | 3586 | 16.17 | |||
| buffer busy due to global cache | 76018 | 1965 | 8.86 | |||
| KJC: Wait for msg sends to complete | 1176069 | 1590 | 7.17 | |||
*表7.2-4 RAC环境・更新处理中的Top 5 Wait Events(将column C_2列数据长从1460 bytes更新为NULL)
| Top 5 Wait Events | ||||||
| 段管理方法 | extent管理方法 | 实例 | Event | Waits | Wait Time(s) | %Total Wt Time |
| 手动manualfree list20
free list・ group4 |
Autoallocate | #1 | global cache cr request | 473370 | 13254 | 43.83 |
| latch free | 297110 | 5144 | 17.01 | |||
| buffer busy due to global cache | 70893 | 3141 | 10.39 | |||
| global cache s to x | 70479 | 2721 | 9 | |||
| ges remote message | 2598161 | 1878 | 6.21 | |||
| #2 | global cache cr request | 539812 | 7468 | 28.32 | ||
| latch free | 300839 | 5479 | 20.77 | |||
| buffer busy due to global cache | 110418 | 4306 | 16.33 | |||
| KJCTS client waiting for tickets | 52231 | 2469 | 9.36 | |||
| ges remote message | 2431088 | 1619 | 6.14 | |||
| 手动manual
free list20 free list・ group4 |
Uniform Size
1GB |
#1 | ges remote message | 3446941 | 52194 | 70.46 |
| global cache cr request | 633104 | 5987 | 8.08 | |||
| latch free | 314660 | 5379 | 7.26 | |||
| buffer busy due to global cache | 113030 | 3838 | 5.18 | |||
| global cache s to x | 60527 | 3531 | 4.77 | |||
| #2 | ges remote message | 3301328 | 52261 | 71.78 | ||
| global cache cr request | 721933 | 6355 | 8.73 | |||
| latch free | 294386 | 5297 | 7.28 | |||
| global cache s to x | 57089 | 3000 | 4.12 | |||
| buffer busy due to global cache | 77360 | 2574 | 3.54 | |||
7.2.3 RAC环境・更新处理(将column C_2列数据长从1460 bytes更新为NULL)・bitmap管理中extent管理差异造成的性能差异
Buffer Busy Waits相关内容如下所示。
* 表7.2.3-1 RAC环境・bitmap管理・Autoallocate・更新处理中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent管理方法 | 实例 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 自动 bitmap管理 |
Autoallocate | #1 | data block | 128671 | 3411 | 27 |
| 1st level bmb | 197 | 1 | 6 | |||
| undo block | 491 | 1 | 2 | |||
| 2nd level bmb | 11 | 0 | 31 | |||
| undo header | 27 | 0 | 2 | |||
| #2 | data block | 71364 | 2297 | 32 | ||
| 1st level bmb | 636 | 8 | 13 | |||
| undo block | 1104 | 7 | 6 | |||
| 2nd level bmb | 10 | 0 | 14 | |||
| undo header | 38 | 0 | 3 | |||
* 表7.2.3-2 RAC环境・bitmap管理・Uniform Size 1GB・更新处理中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent管理方法 | 实例 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 自动 bitmap管理 |
Uniform Size
1GB |
#1 | data block | 79696 | 2677 | 34 |
| undo block | 901 | 4 | 4 | |||
| 1st level bmb | 351 | 4 | 10 | |||
| undo header | 36 | 0 | 3 | |||
| 2nd level bmb | 1 | 0 | 30 | |||
| #2 | data block | 97946 | 2387 | 24 | ||
| 1st level bmb | 148 | 1 | 5 | |||
| undo block | 319 | 1 | 2 | |||
| 2nd level bmb | 2 | 0 | 60 | |||
| undo header | 26 | 0 | 2 | |||
首先请注意bitmap块的wait。使用Autoallocate管理extent时,实例#1以及#2的LevelⅠBMB waits的总计为833(:197+636=833),LevelⅡBMB的waits的总计为21(:11+10=21)。对此,、Uniform Size 1GB中LevelⅠBMB的waits 合计为499(:351+148=399),LevelⅡBMB的waits为3(:1+2=3)。换言之,Autoallocate以及Uniform Size 1GB之间waits的差距是指LevelⅠBMB中为334,LevelⅡBMB中为18。Bitmap相关的内容,Autoallocate反而更多。特别需要注意LevelⅡBMB 的Waits对于性能的影响。
这次在管理extent时,Autoallocate(制成段时的storage语句中没有指定initial值)以及Uniform Size 1GB选择比较极端的管理方法的验证。为了验证Bitmap等待相关内容,需要考虑同时执行用户数、以及将要处理的列数据长。请指定合适的Uniform Size或者在Autoallocate管理中,制成段时,指定合适的initial值,对extent进行预分配。
7.2.4 RAC环境・更新处理(将column C_2列数据长从1460 bytes更新为NULL)・freelist管理中的extent管理差异造成的性能差异。
* 表7.2.4-1 RAC环境・free list管理・Autoallocate・更新处理中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent管理方法 | 实例 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 手动manual
free list20 free list・ group 4 |
Autoallocate | #1 | data block | 95671 | 4478 | 47 |
| free list | 8034 | 28 | 4 | |||
| undo block | 4555 | 22 | 5 | |||
| undo header | 85 | 0 | 4 | |||
| #2 | data block | 145176 | 5315 | 37 | ||
| free list | 3398 | 9 | 3 | |||
| undo block | 1390 | 2 | 1 | |||
| undo header | 60 | 1 | 10 | |||
* 表7.2.4-2 RAC环境・free list管理・Uniform Size 1GB・更新处理中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent管理方法 | 实例 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 手动manual
free list20 free list・ group4 |
Uniform Size
1GB |
#1 | data block | 140784 | 4749 | 34 |
| free list | 4963 | 12 | 2 | |||
| undo block | 2256 | 10 | 4 | |||
| undo header | 16 | 0 | 3 | |||
| #2 | data block | 96182 | 3220 | 33 | ||
| free list | 5385 | 13 | 2 | |||
| undo block | 1655 | 5 | 3 | |||
| undo header | 36 | 0 | 9 | |||
首先我们需要注意free list的waits。Autoallocate的情况中,实例#1以及#2的Waits的总计为11,432(:8,034+3,398=11,432),Uniform Size 1GB中为10,348(:4,963+5,385),其差距为1084占比约为10%。另外,还需要注意上文中介绍过的extent管理差异导致的性能差异。Bitmap管理中的LevelⅠBMB的差399为大约2.8倍。Freelist在扩展段时,在extent的空白块指的并不是free list・group而是对段头(super master freelist)进行链接时的项目。换言之,因为freelist group带来的性能提升太多,在ALTER TABLE ALLOCATE EXTENT语句中对free list・group进行extent分配。
在RAC环境中,使用free list・group来管理空闲区域free extent时,分配extent进行扩展的案例中(在扩展段时,通过这次的验证,进行大部分的extent分配,指定较小的extent尺寸)可能会影响性能,请多加注意。
▼删除(Delete)处理
下表7.2-5是RAC环境中删除处理所需要的时间以及CPU平均使用率的结果。
*表7.2-5 RAC环境中的删除处理結果
| 段
管理方法 |
extent
管理方法 |
处理 | 实例 | 处理时间 (単体) |
处理时间 (合计) |
CPU平均 使用率 (%usr+%sys) |
| 自动 bitmap管理 |
Autoallocate | Delete | #1 | 1,238秒 (20分38秒) |
1,239秒 (20分39秒) |
52% |
| #2 | 1,148秒 (19分08秒) |
54% | ||||
| 自动 bitmap管理 |
Uniform Size
1GB |
Delete | #1 | 1,173秒 (19分33秒) |
1,235秒 (20分35秒) |
57% |
| #2 | 1,235秒 (20分35秒) |
55% | ||||
| 手动manual free list 20 free list・group 4 |
Autoallocate | Delete | #1 | 791秒 (13分11秒) |
812秒 (13分32秒) |
46% |
| #2 | 805秒 (13分25秒) |
62% | ||||
| 手动manual free list 20 free list・group 4 |
Uniform Size
1GB |
Delete | #1 | 809秒 (13分29秒) |
824秒 (13分44秒) |
45% |
| #2 | 820秒 (13分40秒) |
62% |
与插入时的处理不同,在删除处理中bitmap管理比freelist管理带来的性能提升更多。Extent管理中,Autoallocate的情况为比freelist管理时的情况的处理时间要快52%,Uniform Size 1GB比freelist管理要快50%左右。
Extent管理的差异中需要注意的是Autoallocate以及Uniform Size 1GB的处理时间差小于1%,freelist管理中约为1%,基本没有什么差异。
那么STATSPACK又是怎样的情况呢。
*表7.2-6 RAC环境・删除处理中的Top 5 Wait Events
| Top 5 Wait Events | ||||||
| 段管理方法 | extent管理方法 | 实例 | Event | Waits | Wait Time(s) | %Total Wt Time |
| 自动 bitmap管理 |
Autoallocate (Default) |
#1 | global cache cr request | 606569 | 6435 | 31.37 |
| Latch free | 260388 | 4490 | 21.89 | |||
| global cache s to x | 54703 | 3054 | 14.89 | |||
| buffer busy due to global cache | 98264 | 2804 | 13.67 | |||
| KJC: Wait for msg sends to complete | 1060413 | 1454 | 7.09 | |||
| #2 | global cache cr request | 770848 | 8457 | 39.38 | ||
| Latch free | 273382 | 4886 | 22.75 | |||
| global cache s to x | 55372 | 2456 | 11.44 | |||
| buffer busy due to global cache | 56848 | 1855 | 8.64 | |||
| KJC: Wait for msg sends to complete | 1527438 | 1530 | 7.12 | |||
| 自动 bitmap管理 |
Uniform Size 1GB | #1 | global cache cr request | 796545 | 9068 | 39.53 |
| Latch free | 276780 | 4729 | 20.62 | |||
| global cache s to x | 52125 | 2900 | 12.64 | |||
| buffer busy due to global cache | 63969 | 2233 | 9.73 | |||
| KJC: Wait for msg sends to complete | 1483038 | 1668 | 7.27 | |||
| #2 | global cache cr request | 702136 | 8111 | 36.57 | ||
| Latch free | 264556 | 4724 | 21.3 | |||
| global cache s to x | 51774 | 3586 | 16.17 | |||
| buffer busy due to global cache | 76018 | 1965 | 8.86 | |||
| KJC: Wait for msg sends to complete | 1176069 | 1590 | 7.17 | |||
*表7.2-6 RAC环境・删除处理中的Top 5 Wait Events(続き)
| Top 5 Wait Events | ||||||
| 段管理方法 | extent管理方法 | 实例 | Event | Waits | Wait Time(s) | %Total Wt Time |
| 手动manualfree list20
free list・ group4 |
Autoallocate | #1 | global cache cr request | 473370 | 13254 | 43.83 |
| latch free | 297110 | 5144 | 17.01 | |||
| buffer busy due to global cache | 70893 | 3141 | 10.39 | |||
| global cache s to x | 70479 | 2721 | 9 | |||
| ges remote message | 2598161 | 1878 | 6.21 | |||
| #2 | global cache cr request | 539812 | 7468 | 28.32 | ||
| latch free | 300839 | 5479 | 20.77 | |||
| buffer busy due to global cache | 110418 | 4306 | 16.33 | |||
| KJCTS client waiting for tickets | 52231 | 2469 | 9.36 | |||
| ges remote message | 2431088 | 1619 | 6.14 | |||
| 手动manual
free list20 free list・ group4 |
Uniform Size
1GB |
#1 | ges remote message | 3446941 | 52194 | 70.46 |
| global cache cr request | 633104 | 5987 | 8.08 | |||
| latch free | 314660 | 5379 | 7.26 | |||
| buffer busy due to global cache | 113030 | 3838 | 5.18 | |||
| global cache s to x | 60527 | 3531 | 4.77 | |||
| #2 | ges remote message | 3301328 | 52261 | 71.78 | ||
| global cache cr request | 721933 | 6355 | 8.73 | |||
| latch free | 294386 | 5297 | 7.28 | |||
| global cache s to x | 57089 | 3000 | 4.12 | |||
| buffer busy due to global cache | 77360 | 2574 | 3.54 | |||
7.2.5 RAC环境・删除处理時・bitmap管理中的extent管理的差异造成的性能差异
首先,请注意二者的Buffer busy waits。
* 表7.2.5-1 RAC环境・bitmap管理・Autoallocate・删除处理中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent管理方法 | 实例 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 自动 bitmap管理 |
Autoallocate | #1 | data block | 98787 | 3258 | 33 |
| undo block | 1442 | 10 | 7 | |||
| 1st level bmb | 996 | 5 | 5 | |||
| undo header | 97 | 0 | 4 | |||
| extent map | 4 | 0 | 48 | |||
| #2 | data block | 101963 | 2987 | 29 | ||
| 1st level bmb | 425 | 9 | 21 | |||
| undo block | 275 | 2 | 7 | |||
| undo header | 38 | 0 | 1 | |||
| 2nd level bmb | 1 | 0 | 30 | |||
*表7.2.5-2 RAC环境・bitmap管理・Uniform Size 1GB・删除处理中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent管理方法 | 实例 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 自动 bitmap管理 |
Uniform Size
1GB |
#1 | data block | 82589 | 2094 | 25 |
| 1st level bmb | 691 | 4 | 6 | |||
| undo block | 190 | 1 | 4 | |||
| undo header | 35 | 0 | 3 | |||
| 2nd level bmb | 3 | 0 | 0 | |||
| #2 | data block | 75416 | 2354 | 31 | ||
| undo block | 848 | 7 | 8 | |||
| 1st level bmb | 4440 | 6 | 1 | |||
| undo header | 89 | 1 | 6 | |||
| 2nd level bmb | 42 | 0 | 8 | |||
首先,让我们来关注仅仅在Autoallocate中发生的extent map的竞争,其原因为分配extent时,变成了多bitmap块结构。
另外比其Autoallocate,Uniform Size 1GB的LevelⅠBMB语句LevelⅡBMB的Waits要更高,这是因为LevelⅠBMB地址指定能力之间有差异。之前已经上文的SI环境中的验证的「7.1.2 bitmap管理中的extent管理Autoallocate的性能恶化」中验证过了,结论为Unifrom Size 1GB是用1个LevelⅠBMB来管理256 数据块的空白状态的。对此,Autoallcoate则是1个LevelⅠBMB来管理16个或者64个数据块(使用Autoallocate时,储存100,000行时,因为段的总计尺寸约为260MB。因此,在连续数据块被删除的案例中,Uniform Size 1GB比Autoallocate更容易发生LevelⅠBMB的竞争。那么为什么在删除处理中,会发生大量的LevelⅠBMB的Waits,而在更新处理中却并不会发生那么多wait呢?
现阶段中,因为还没有确认方法,所以没有推断区域,可以想到的主要理由如下所示:储存数据时,拥有同样的key(C_1的值)得到较好扩散,可以管理不同的LevelⅠBMB中的数据块的空白状态。这次的验证中,单纯把重点放在处理件数上,所以并没有获得严谨的数据储存序列。这个差值是指出现的可能性较大。
bitmap管理中,1个数据块只能储存1-5行左右的情况下,如上文中的删除处理以及更新处理的对策一样,通过将数据长度更换为NULL等操作,可以制造数据块中的空闲区域free extent。制造空闲区域free extent是指更新LevelⅠBMB保存的空白信息,并且更新管理的LevelⅡBMB信息,甚至更新段头(LevelⅢBMB)的信息。这时发生的竞争绝不低,请在检查时注意。
7.2.6 RAC环境・删除处理時・free list管理中的extent管理差异造成的性能差异
首先,请大家注意Autoallocate眼睛Uniform Size 1GB Buffer busy waits。
* 表7.2.6-1 RAC环境・free list管理・Autoallocate・删除处理中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent管理方法 | 实例 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 手动manual
free list20 free list・ group4 |
Autoallocate | #1 | data block | 126496 | 4610 | 36 |
| free list | 6209 | 17 | 3 | |||
| undo block | 3157 | 14 | 4 | |||
| undo header | 2 | 0 | 5 | |||
| #2 | data block | 62635 | 1988 | 32 | ||
| undo block | 2521 | 25 | 10 | |||
| free list | 6408 | 21 | 3 | |||
| file header block | 17 | 7 | 392 | |||
| undo header | 45 | 0 | 1 | |||
* 表7.2.6-2 RAC环境・free list管理・Uniform Size 1GB・删除处理中的Buffer busy waits
| Buffer busy waits | ||||||
| 段管理
方法 |
extent管理方法 | 实例 | Class | Waits | Tot Wait Time (s) |
Avg Time (ms) |
| 手动manual
free list20 free list・ group4 |
Uniform Size
1GB |
#1 | data block | 136784 | 4297 | 31 |
| free list | 6352 | 17 | 3 | |||
| undo block | 3192 | 12 | 4 | |||
| undo header | 2 | 0 | 0 | |||
| #2 | data block | 53108 | 1753 | 33 | ||
| free list | 5746 | 18 | 3 | |||
| undo block | 2268 | 9 | 4 | |||
| undo header | 20 | 0 | 10 | |||
首先是free list值的差异,实例#1、#2的waits的总计值,Autoallcoate中为 12,617(:6,207+6,408=12,617),Uniform Size 1GB中为12,098(内訳:6,352+5,746)。差距为519,百分比来表示的话就是4%左右,Autoallcate的数值较高。上文「7.2.4 RAC环境・更新处理(将column C_2的列数据长度从1,4620bytes更新为Null)中free list管理中的extent管理的差异导致的性能差异」中论述过了,free list・group管理机制中,段扩展时,被分配到的extent中的空白块不是指freelist group,而是指连接到段头(super master freelist)。相对的,Uniform Size 1GB的情况就是将各自的free list・group连接到空白块。
总而言之,在RAC环境中,利用free list・group来管理空闲区域free extent时,与这次的验证相同,通过Autoallocate来管理、分配进行扩展的案例中以及在段中指定较小的extent尺寸时,在分配大部分extent的案例中,可以有效利用free list・group。在制成段时,在在storage语句中指定合适的initial值或者在ALTER TABLE ALLOCATE EXTENT语句中,对freelist group分配extent,从管理层面来考虑的话,导入到bitmap管理要更好。
▼結論 (RAC环境)
提高上述验证结果,RAC环境中的空闲区域free extent管理中,bitmap管理与freelist group管理之间的区域如下所示。
- 插入处理中,bitmap管理的效率比freelist管理的效率要高得多。
- 更新处理中比插入管理来说,bitmap管理与freelist管理之间基本没有差异。但是如果使用如下方法的话,可以提高bitmap管理的性能:考虑到了同时执行的用户数进行extent分配。2.在制成段时,指定合适的initial值。
- Bitmap管理时,bitmap块数量会对搜索性能产生影响。特别是在搜索全盘时,会读入所有的bitmap块。可以同设定并行DML,可以减轻这些成本,请根据具体情况来进行导入。
- 一个块只能储存4-5行时,在bitmap管理中,连续数据块就会被删除,空闲区域free extent就会增加,bitmap块竞争就会升高,请大家注意。特别是段尺寸较大时,这个倾向较强。
- 管理freelist group,进行段扩展时,被分配的extent中的空白块是指不是连接到freelistgroup,而是连接到段头(super freelist),请大家注意。
- Freelistgroup只能在制成段时进行指定,另外,还有如上文所说的,extent的空白块不会进行连接。相对地,bitmap管理中,就不需要考虑这些问题,RAC环境中,还是尽可能使用bitmap管理会更好。
参考資料
各水平的bitmap块相关的详细内容如下所示,首先是LevelⅠBMB相关说明。
- LevelⅠBMB
・LevelⅠBMB保存了属于段的extent中的相邻块之间的空白信息。
Bit set DBA(Data Block Address) range:
vector ・段中的块的subset信息
・无法超过extent的范围来构成subset
通过LevelⅠBMB的排列来指定的DBA range是指不超过extent的范围的相邻的DBA的set。由此,可以更加方便地执行extent的操作以及段的重构。
各个LevelⅠBMB最多可以管理16个DBA range。由此,在重构复杂段以及多个同时执行处理中,需要调整对Level BMB的高负荷访问之间的平衡。LevelⅠBMB中,使用RAC环境时,会储存区域对应的实例相关的Affinity的数据。
◆ LevelⅠBMB的转储

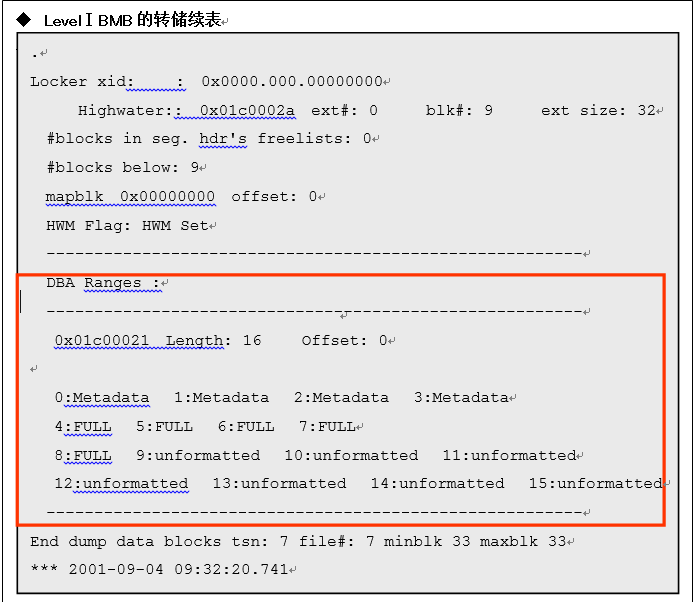
LevelⅠBMB表示相邻的DBA的range。DBA的range是指位于range开始位置的DBA,range长度。LevelⅠBMB中可以储存的DBA range是指段尺寸以及依赖于适合的bit的数量。
由上述的转储中,extent中最开始的4个数据块(0-3也计为4)可以通过储存元数据来确认。这是其他的LevelⅠBMB、LevelⅡBMB 段头相关信息。插入处理中,首先使用的数据块为4,接下来可以在插入处理使用的块为9.另外,4-8的数据块为满(FULL)时(作为bitmap的架构可以使得1101成立)。然后9-15的数据块没有被格式化的状态可以使得0000成立。
接下来是Level II BMB的相关说明。
- LevelⅡBMB
・LevelⅡBMB保持着LevelⅠ的DBA以及元数据。
LevelⅠBMB排列
- LevelⅠBMB的DBA
- 任意块中的空闲区域free extent的最大值
- 实例的Affinity
另外LevelⅡBMB中会储存以下信息。
- LevelⅢBMB(或者是段头)的DBA
- 可以使用空闲区域free extent的LevelⅠBMB的总数
- LevelⅠBMB的合计
- 可能存在的下一个LevelⅡBMB的DBA
- Bitmap锁定处理中的XID
- 锁定操作描述符(Locking Operation Descriptor)
通过1个LevelⅡBMB来管理的LevelⅠBMB数据(1个LevelⅠBMB使用7bytes的区域)如下所示。
- 块尺寸2K → 300 LevelⅠBMB (最小:2.4MB 最大:600MB)
- 块尺寸4K → 500 LevelⅠBMB (最小:32MB 最大:2GB)
- 块尺寸32K → 4,000 LevelⅠBMB (最小:2GB 最大:128GB)
由此,1个LevelⅡBMB所管理的LevelⅠBMB数量就变得非常多。因此,LevelⅡBMB的信息就会频繁更新。这时,系统就会产生新的瓶颈。
与LevelⅠBMB时相同,上述转储中作为bitmap块的level,可以确认 「SECOND LEVEL BITMAP BLOCK」的字符串。段头(LevelⅢBMB)的DBA会作为「pdba」的值被表示出来。另外还可以确认Level II BMB值中出现的LevelⅠBMB的总数(number)以及其中空闲区域free extent的LevelⅠBMB的总数(nfree)、以及各个LevelⅠBMB的DBA。通过Inst中表示的数值是指实例的Affinity表示的数值,这个值为1时,表示意味着这是SI环境在RAC环境中,需要根据具体情况,动态变更这个数值。
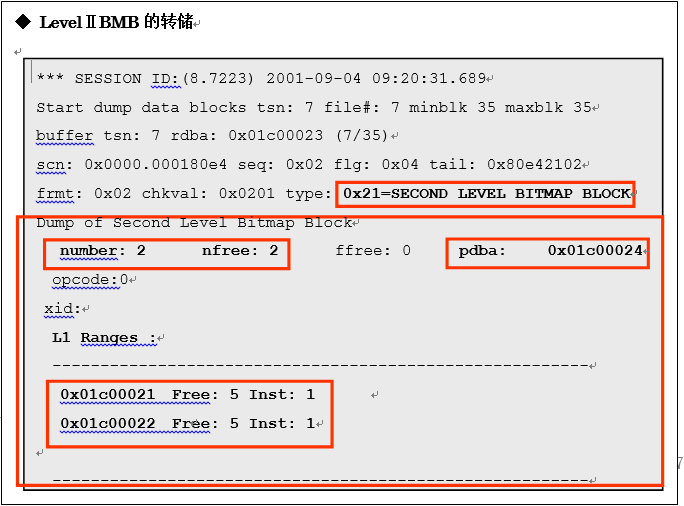
接下来我将说明LevelⅢBMB的相关内容。
- LevelⅢBMB
LevelⅢBMB保持了LevelⅡBMB的地址信息,大部分的段中,基本没有LevelⅢBMB新制成的案例。一般而言,段头作为最开始的LevelⅢBMB来发挥作用。新制成这个LevelⅢBMB是指段头无法保持所有的LevelⅡBMB信息了(空间不足)。
LevelⅢBMB中包含以下信息。
- 段头的DBA
- 可能存在的下一个LevelⅢBMB的DBA
- 可以使用的LevelⅡBMB DBA数
- LevelⅡBMB排列
- Bitmap锁定中的XID
可以通过段头(作为最开始的LevelⅢBMB来操作)来管理的LevelⅡBMB数如下所示。
- 块尺寸2K → 500 LevelⅡBMB (最小:1.2GB 最大:300GB)
- 块尺寸→ 1,000 LevelⅡBMB (最小:32GB 最大:2TB)
- 块尺寸→ 8,000 LevelⅡBMB (最小:16TB 最大:1PB)

「type」的项目中有「PAGETABLE SEGMENT HEADER」,这意味着这变成了自动段区域管理,(freelist管理时,这个值为「DATA SEGMENT HEADER」)。被highlight的「Highwater」值在这个段中表示包含数据的最终块的DBA(换言之就是还没使用过的块的DBA)。
然后请参考之后持续的段头的转储。
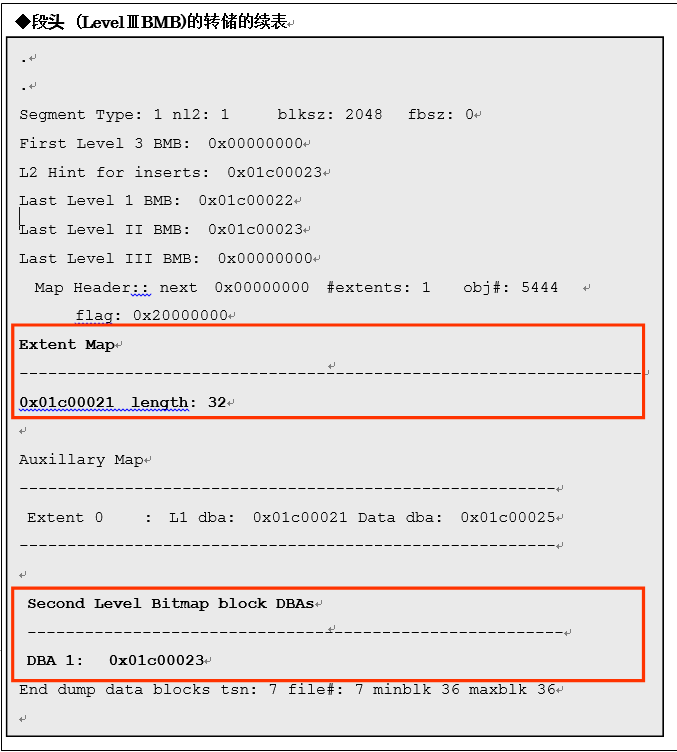
上图是上面的《段头的转储》的续表。虽然是被highlight的「Extent Map」的部分,但由此我们可以查看extent的DBA以及extent中的块长度(length)。如果这个段中分配了多个extent时,在接下来的部分中,会记录extent相关的DBA以及长度。
通过LevelⅠBMB指定的数据块是指刚开始没有被格式化的状态。以下记录了没有被格式化的数据块的转储。
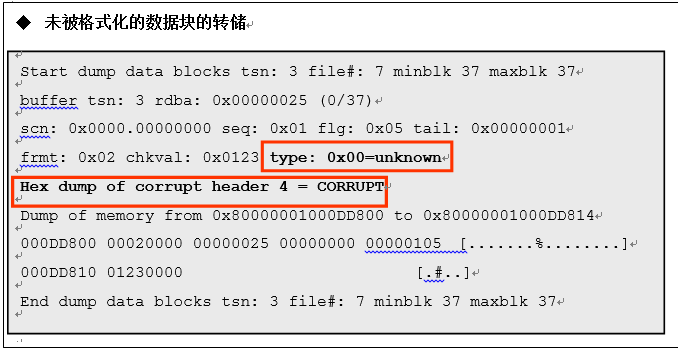
如上所示,我们可以看出未被格式化的数据块的类型为UNKOWN,数据块实际上与「CORRUPT」状态相同。
插入处理中,进程通过LevelⅠBMB指定的适合的数据块中,对数据进行写入,但在最开始的写入时,首先就会对未格式化的相邻的一系列的范围(最小为16)的数据块进行格式化。
然后记录执行了格式化的数据块
- 格式化之后的数据块的转储
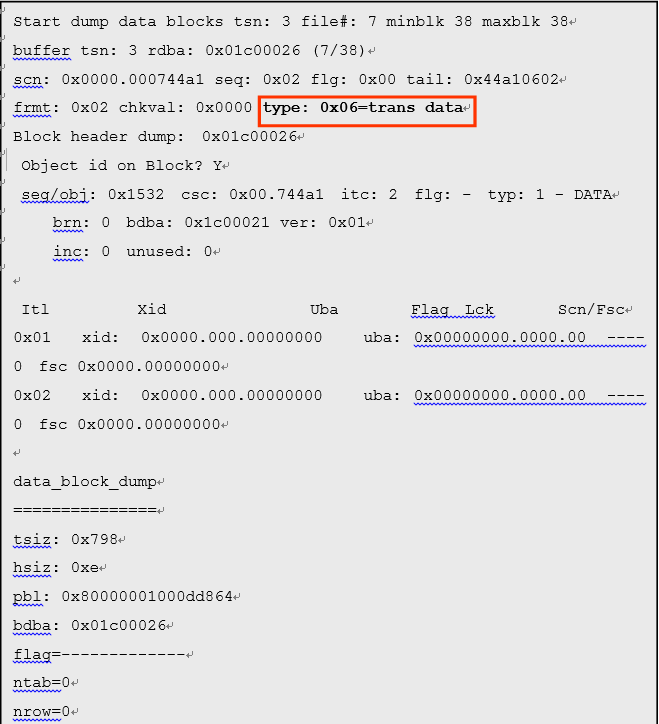
如上所示,完成格式化的数据块的类型就变成了「trans data」,就会追加bitmap块的锁定处理中使用的「xid」等,由此就可以储存数据了
这在之前已经阐述过了,数据块被格式化并不是指一个块被格式化,而是一定范围(最小是16个块)被格式化了。如果进程发现了没有被格式化的块的话,包含那个数据块,相邻的范围都会被格式化。这在实际执行格式化时,对于连续的数据块就会发生I/O。因此,新建extent的分配中,对所有的数据块进行格式化就代表这也需要巨量的成本。特别是extent尺寸越大,成本也就越高。因此,分配extent时,数据块就不会被格式化,在插入处理时,就会对数据进行格式化,从而减少I/O成本。
bitmap块中多个进程同时访问时,就很有可能发生。在多个进程进行插入时,通过LevelⅠBMB而执行的分配会通过根据实例编号以及实例ID中的哈希算法来执行。这是为了减少多个进程在插入处理中的格式化成本的机制。多个进程通过不同的LevelⅠBMB来指定的各个区域中同时执行写入时,比如,排列插入等案例中,对连续块进行格式化,也无法腾出足够的空闲区域free extent。这时,这个进程就不会对目标数据块进行格式化,转而去寻找其他可以使用空闲区域free extent。由此,就可能发生这样的状况:同一个extent中通过HWM(高水位线),会将一些未格式化的块原样保留。由此,因为存在没有格式化的数据块,所以在自动段区域管理中,应用了与一直以来freelist管理不同的HWM。
以下就是这样的HWM相关内容。
本文永久链接 https://www.askmac.cn/archives/oracle-free-space-managements-验证报告.html
◆自动段区域管理中的HWM(高水位线)
Bitmap管理中,通过以下两个HWM来管理段。
- Low High Water Mark (Low HWM)
- 这是表示以下所有块都完成了格式化
- High High Water Mark (High HWM)
- 这是表示以上所有块都完成了格式化
Low HWM以及High HWM直接的块之间可能同时存在完成格式化以及没有完成格式化的块。另外,各自的高水位线的操作时机如下所示。
- Low HWM操作时机
- 在同一个extent中,对Low HWM上相邻的块进行格式化时
- 分配新建extent时,之前extent中所有的块都完成格式化时
・ High HWM操作时机
- 与一直以来的freelist管理相同,在新建行插入处理时使用新建的块时上升
可以通过1个bitmap块来管理的块的总数多少依赖于段尺寸。1个bitmap块地址指定能力
(Bitmap Block Addressability)以及段尺寸的关系如下所示。
表8-1 bitmap・块的地址指定能力
| 段尺寸 | 被标记的数据块数量 |
| 1MB以下 | 16数据・块 |
| 32MB以下 | 64数据・块 |
| 1GB以下 | 256数据・块 |
| 1GB以上 | 1024数据・块 |
实际上,通过Autoallocate 管理extent时(段的初始尺寸为64K) 以及以Uniform Size为
10MB(段的初始尺寸为10MB)来制成时,会在以下记载LevelⅠBMB的转储
- 段尺寸小于1MB 时的LevelⅠBMB的转储
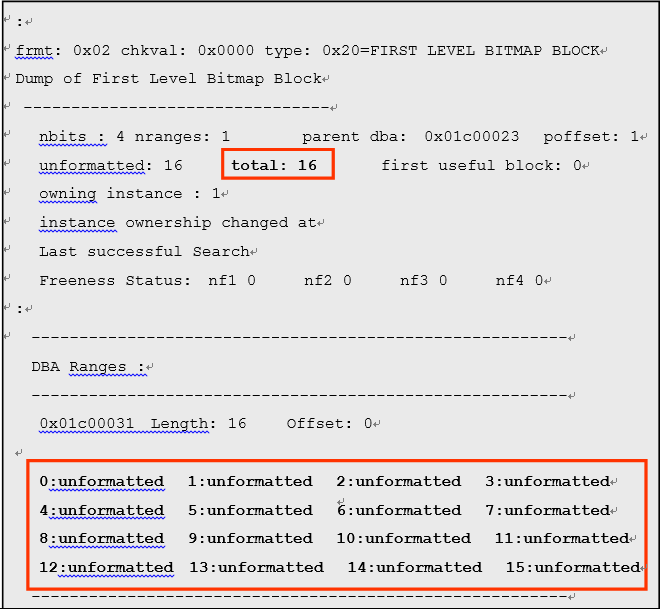
- 段尺寸大于1MB小于等于32MB时LevelⅠBMB的转储
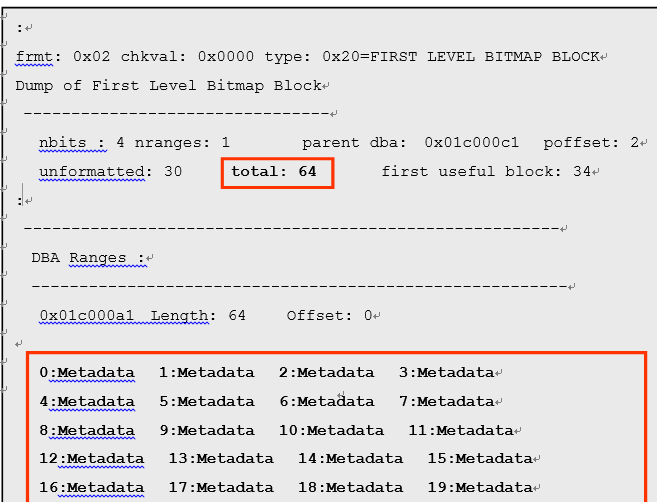
上述转储中LevelⅠBMB相关的段尺寸小于1MB时。在16个数据块中,并且对大于1MB小于等于32MB的64个数据块进行映射。
那么被分配的bitmap块数的成长率会怎样变化呢?请看下图。
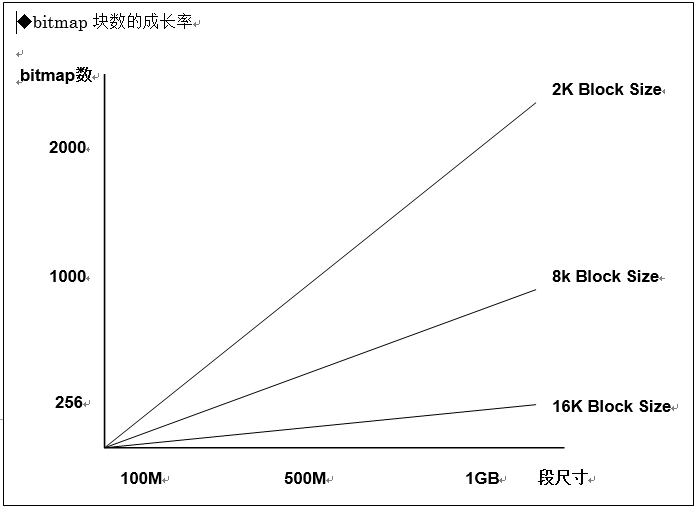
上述图表是bitmap块数与段尺寸增大的比例。成长率大概是线性的。同时执行处理中的并行度数的机制严格来说无法进行严谨的定义(需求空闲区域free extent同时访问的进程数)。所以需要预想到最恶劣的情况(巨量的进程同时对较小尺寸的段进行访问的案例),来定义如上的成长率。伴随着段的成长被分配的extent扩大时,(extent管理中,通过Autoallocate来指定的情况等等),并不一定如上所示线性成长。成长率也并不一定是16、64、256、1024等等、偶尔也会有飞跃性的增长。
1个bitmap块管理的块数,是直接影响下述搜索算法的主要原因。
◆受到bitmap块数影响的搜索算法
- 全盘搜索算法:
在自动段区域管理中,从High HWM对以下区域没有格式化的块进行许可。在表的全盘搜索中,为了判断块是否被格式化,首先需要对bitmap块进行搜索。因此,如果有大量的bitmap块的话,I/O成本也会相应增大。
- 搜索算法
同时多个DML中,减少数据块以及bitmap块之间的竞争也是性能优化的目标之一。特别是RAC的环境中,为了减少数据块的ping,这一点就非常重要。Bitmap块中,减少竞争的最佳方法就是通过增加bitmap块数,减少使用一个bitmap块来管理的DBA数量。请大家注意这也会在全盘搜索时,导致读入大量的bitmap块。
对于多个同时DML,可以指定缩小extent的尺寸,从而可以确保大部分的bitmap块,减少数据块以及bitmap块的竞争。但是,在段增长较频繁的案例中,并不一定如此。
比起一直以来的free list管理,段头自身结构以及构成要素中被变更的部分如下所示。
- 自动段区域管理中的段头结构

自动段管理的段头中,使用freelist管理的区域中会储存LevelⅡBMB排列。另外,短途中还会保存以下信息。
- Extent control:
维护High HWM
- Low HWM:
根据<extent编号、extent map块、LevelⅠBMB编号>执行维护
- 段头控制:
段类型、LevelⅡBMB数、DB块尺寸,插入中的LevelⅡBMB的提示。包含最后使用的LevelⅠBMB的DBA、最后使用的LevelⅡBMB的DBA、最后使用的LevelⅢBMB的DBA。
- Extent 表
保存Extent中的块数以及extent中最开始的块的DBA的信息
- 临时extent map
执行初始extent中的最开始的block的块的LevelⅠBMB以及最开始的数据块的维护。
自动段区域管理:
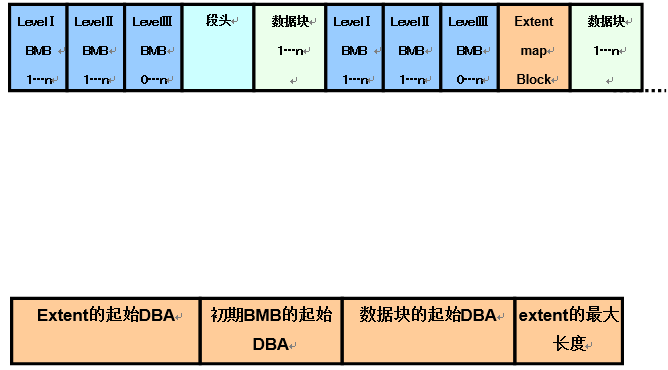
一直以来的freelist管理中,段头块一般位于段最开始的块中。在自动段区域管理中,所有的bitmap块都配置得较前方。
- 多个bitmap块以及extent map的结构
如上所述,bitmap块一般位于段头的前方。由此,就可以使得合并段更加高效。如果extent尺寸超过了LevelⅠBMB中可以出现的范围的话,oracle就会在新的extent分配时,将现有的项目分配到其他的新建bitmap块中。这样的结构我们称为Multiple BMBs)。在新的extent分配中,会估算必需的bitmap块数 (LevelⅠ、Ⅱ、ⅢBMB),重新分配新的extent的部分。
分配extent map block时,也需要分配bitmap块,bitmap块通常被放在extent map block的前方。由此,就可以仅凭单个bitmap块来管理extent结构了。Oracle并不需要在所有的extent中分配bitmap。假设出现这样的结构的话,就会出现大量bitmap块,导致新的性能问题。
- 复合bitmap块结构图
另外,extent map中还储存了以下信息。
- Extent的起始DBA
- 初期BMB的起始DBA
- 初期数据块的起始DBA
- Extent的最大长度
那么,我们搜索空闲区域free extent的算法到底是怎样的呢?
首先请搜索LevelⅡBMB中的空闲区域free extent的搜索算法。
- 如果有负荷要求的完成高速缓存的数据块的DBA的话请直接使用。如果没有请看②。
- 段头中最后使用的LevelⅡBMB作为提示保存着。在制成段时,最少也会分配到一个LevelⅡBMB。通过这个LevelⅡBMB所指定的DBA在搜索开始位置使用。这时,通过共享模式获得LevelⅡBMB。
- 通过LevelⅡBMB的搜索,找出拥有这个实例中最大空闲区域free extent的LevelⅠBMB。各个LevelⅡBMB中,根据空闲区域free extent状态,会储存各自LevelⅠBMB的数量。如果,没有找到符合要求的LevelⅠBMB的话,就会跳过LevelⅡBMB,选择下一个LevelⅡBMB。同时多个处理中的LevelⅡBMB的搜索是通过<实例编号、进程编号、哈希函数>来执行的。
- 搜索整个LevelⅡBMB,收集符合要求的空闲区域free extent的LevelⅠBMB的DBA,并且对应实例的Affinity。然后储存在对应排列中。这是,可以储存的LevelⅠBMB的最大值为10个。接下来,使用LevelⅠBMB搜索算法,搜索这10个LevelⅠBMB的排列找出空闲区域free extent。
- 如果没有找到足够的空闲区域free extent的话,就会检测实例的Affinity。这时,存在对应其他实例的LevelⅠBMB。保存了满足块要求的空闲区域free extent时,就会对块进行Steele。并且进行LevelⅠBMB的搜索。
- 扩展段,解放、LevelⅡBMB。RAC环境中为了减少PING, LevelⅠBMB保存着特定的实例以及实例group的Affinity。在空闲区域free extent的搜索算法中,经常想使用保存了与自己想通的实例的Affinity group的块,那么首先请尝试这种方法。如果,无法找到时,请进行其他扫描。
然后我将展示LevelⅠBMB中的空闲区域free extent的搜索算法
- LevelⅠBMB中的空闲区域free extent搜索算法
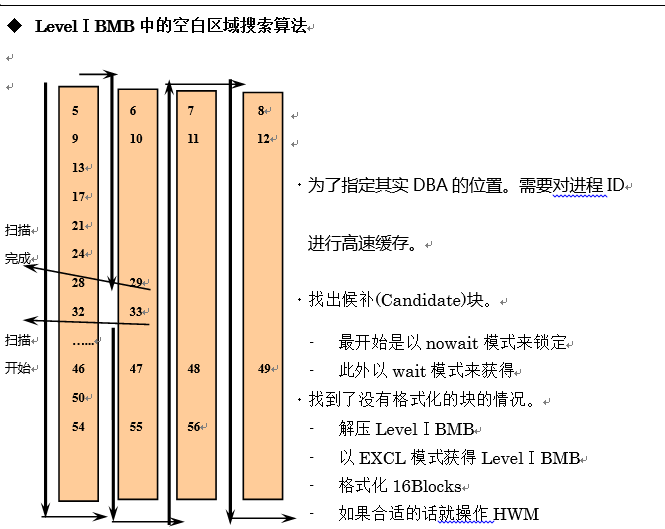
关于如何找出保存了最大的空闲区域free extent的LevelⅠBMB的问题,LevelⅠBMB可以将其作为DBA的2次元的grid来看待(grid的一次元固定为16)。通过对进程ID进行高速缓存,可以找出LevelⅠBMB搜索的开始位置。无法在现有块中找到足够的空白空闲区域free extent,需要在下一个块中寻找时,哈希函数中的同一column中,对现在的块到往前数16号的块进行搜索。如果现有column中没有找到候补块的话,就对下一个column进行搜索。发现了能成为候补的DBA时,首先对那个块以nowait模式进行锁定。这是,其他进程以及掌握时,就会继续寻找下一个候补。在寻找下一个候补块之前,首先尝试5次是否无法以排他模式获得那个块。
如果发现了没有格式化的DBA时,就需要解放LevelⅠBMB,并且以排他模式重新获得那个块。之后,作为DBA的开始位置,对相邻的16个数据块进行格式化,必要的话,还需要更新Low HWM或者High HWMを更新する。
最后解压LevelⅠBMB,检测其有效性。如果失败时,就会重新返回上述格式化的步骤。
确保空闲区域free extent的全盘搜索在date(终结)实例开始。为了更加简便地说明,上文的流程图中,不会覆盖。单纯以阀值的形式来表示。属于实例X的所有LevelⅠBMB的算法通过以下条目来决定。
- 如果实例date终结了,对LevelⅠBMB进行Steele。
- 如果instance有残留的话,执行LevelⅠBMB的CR(Consistent read)
- 如果现在的 时间比最后执行的分配阀值时间要少,或者现在的时间比最后执行的Steele的阀值要少时,就跳过那个块。
- 此外,都进行steele。
- 更新段的HWM。
自动段区域管理在RAC环境中是有效的管理方法。通过上述算法来管理,在动态追加、删除实例时,会对段进行自动调优。另一方面,通过freelist来管理段时,为了确保多个同时处理中的性能,会在制成段是,进行指定。自动段管理在动态追加、删除实例时,无法同样地动态操作这些freelist group的数量(需要重新制成段)。由此,需要在将来迁移到RAC中的SI环境中讨论是否应该导入自动段区域管理。
- 估计新分配的extent所需要的bit的总量。
- 在最后的LevelⅠBMB中,检测新建extent中是否存在将要使用的足够的空白bit。如果没有的话,就需要在新建extent中估计必需的所有LevelⅠ、Ⅱ、Ⅲ的BMB 数量。
- 分配extent。如果分配到新的bitmap块时,需要将其格式化。在extent中,将其置于数据块之前
- 对bitmap进行格式化。追加新建的LevelⅠBMB时。更新LevelⅡ对应元数据,在LevelⅠBMB中设定没有进行格式化的bit状态。
更新可以使用的bit总数信息。
更新LevelⅢBMB(或者是段头)的信息。
5 格式化 LevelⅠBMB最开始的range。并更新相关的bitmap块信息。返回插入时块的格式化的overhead。各个进程迅速导出响应时间。
- 必要的话请更新Low HWM以及High HWM。这都在HWM Enqueue中执行。
那么解除(Deallocation)extent分配操作又是怎样的呢?
- (Deallocation)extent分配操作
- 舍弃段时
▼ 删除所有相关元数据
→ 如果LevelⅠBMB包含在舍弃对象的范围中时,就会将extent与LevelⅠBMB一起删除
→ 如果LevelⅠBMB不包含在舍弃对象中时。就会更新bitmap信息。
→ 如果LevelⅠBMB被删除时,就会更新LevelⅡBMB的信息
→ 如果LevelⅡBMB被删除时,就会更新LevelⅢBMB信息
▼ 更新Low HWM以及High HWM
- 处理受UNDO保护
- drop段时
▼不需要更新bitmap
Extent删除时,需要删除相关所有元数据。通过复合bitmap块结构, LevelⅠBMB包含在删除对象的extent时,就不会更新LevelⅠBMB的信息,会一起被删除。相对地,删除对象的extent中不含LevelⅠBMB时,就会增加保存了可以使用的空闲区域free extent块,所以就会更新相关的bitmap信息。如果LevelⅠBMB被删除了,就会更新相关的LevelⅡBMB的信息。同样地, LevelⅡBMB被删除时,就会更新相关的LevelⅢBMB的信息。另外,根据需要还会减少Low HWM以及High HWM。因为这些处理都受UNDO保护,所以如果处理中发生了进程故障以及实例故障的话,还可以返回原本的状态。
段在drop时,段会被变更成“TEMP”,以无法访问的状态进行迁移,所以不需要更新bitmap块。
Leave a Reply