本文永久地址:https://www.askmac.cn/archives/oracle-shared-pool%e5%85%b1%e4%ba%ab%e6%b1%a0%e8%af%a6%e8%a7%a3.html
理解shared pool共享池
子池分割以及子heap分割
共享池可以通过以下两个角度来分割。
1.根据CPU以及共享池尺寸来分割子池(自动手动均可)
⇒ 因为共享池latch(每个池中各有一个)的竞争分散
CPU 数、共享池的共享分割
2.根据持续时间来对子heap进行分割(仅限自动)
⇒ 通过使得持续时间较长的chunk一直存在,就可以防止碎片化
根据内存的持续时间来分割共享池

根据持续时间不同导致所储存的信息不同
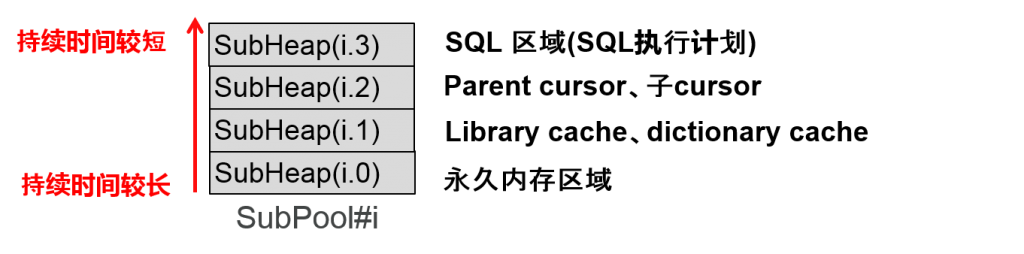
子池的隐藏FREE区域(通称)
- 启动数据库之后会存在一个名为隐藏FREE(SubPool#0)的空白区域(Reserved Granule)。另外,在各个SubPool中也会分配一定的FREE区域。用V$SGASTAT观察到的FREE是包含SubPool#0的空白区域的总计。
- SubPool#0的区域不会发生碎片化。
- 由于这些机制,指定的子池从隐藏FREE中获得区域的话,指定的子池就会无端扩张,产生尺寸偏差,导致发生ORA-4031。
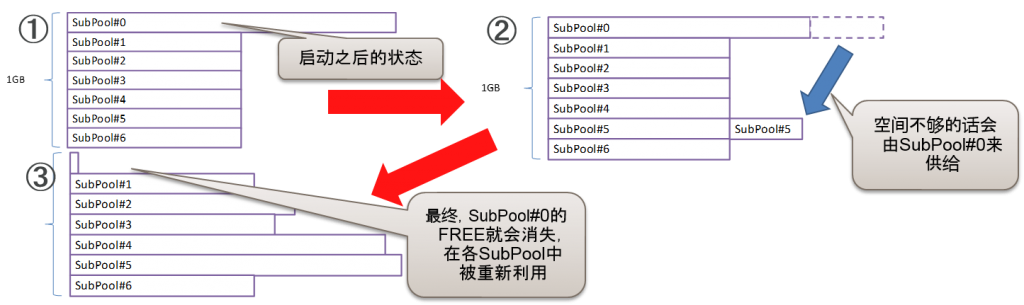
共享池的FREE内存是指什么(v$sgastat.free memory)
- 隐藏FREE(Reserved Granule)
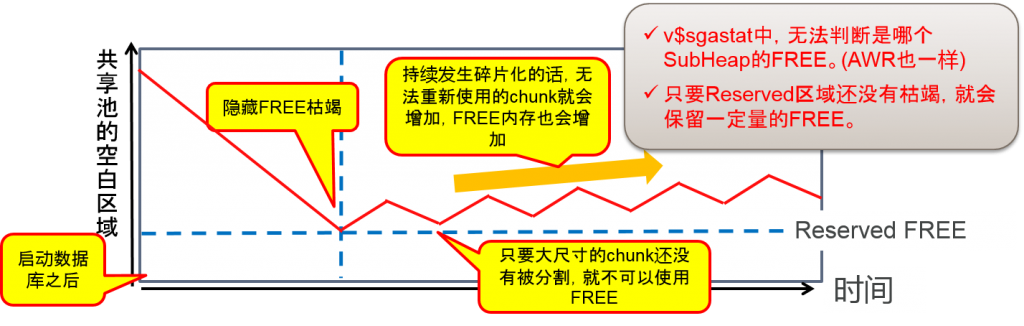
持续使用的话,慢慢地就会被分割到数个SubHeap中,消失的区域 - Reserved FREE
通过设定shared_pool_reserved_size预约区域(默认是共享池的5%)
可以确保4400byte以上的chunk
- FREE chunk
Free list中被连接的空白chunk,如果是区域的要求,无论何时都可以使用,但是,需要确保区域是连续区域。不足4400byte的chunk就会被确保下来
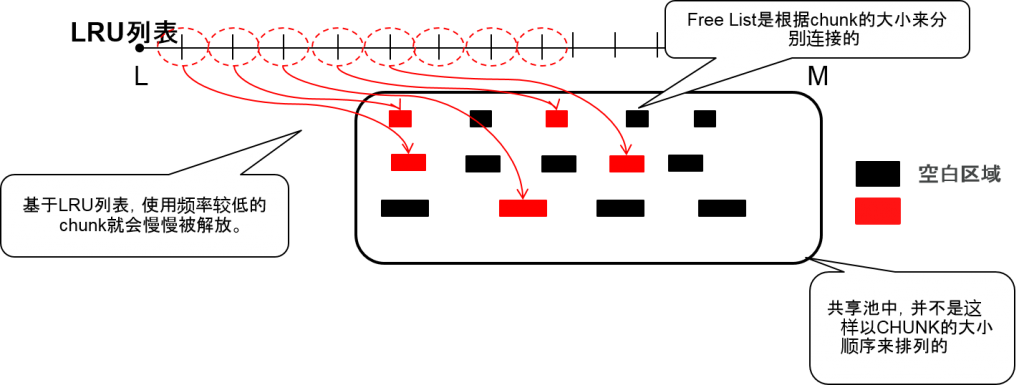
刷新LRU列表的机制
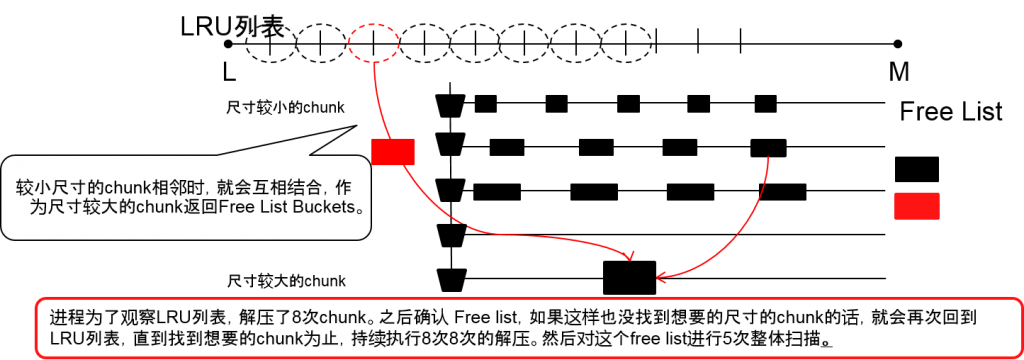
要求共享池的空白区域~ORA-4031的流程

子池、子heap之间的空白区域不是相通的
- 即使指定的SubHeap中需要空白区域,但也无法从其他的子池的内存或者其他subheap中获得。Free list不同的subheap来管理的。
- 刷新LRU列表,已经制成的空白内存就会分别返回各自的subheaplist。
- 为了制作(1.2)的空白,需要刷新LRU,如果找到了LRU中可以解压的chunk的话,就会激情那个chunk返回到free list中。
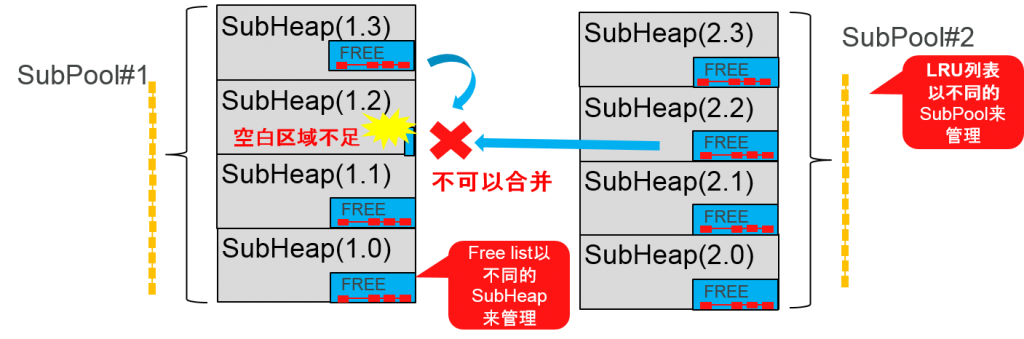
共享池的free内存候补
- RECREATABLE chunk
–使用LRU列表中被关联的chunk,当free内存不足时,无法进行pin,就会依次解压使用频率较低的chunk,返回free list。
–Free list存在于每个subheap中,因为并不会返回隐藏free,所以只能在同样的subheap中重复利用。
–flush shared pool可以单方面解压RECREATABLE chunk。
- FREEABLE chunk
–Chunk的使用者发出解压命令是,就会被返回free list。
※ PERMANENT chunk不会返回 free list
碎片化的倾向分析方法
| No | 调查目的 | 获得的meta | DB
获得间隔 |
ASM
获得间隔 |
| 1 | 确认共享池的空白以及使用量的总量 | V$SGASTAT | 1小时 | 1天 |
| 2 | 确认不同子池中使用的共享池的空白以及使用量的总量※V$SGASTATの元表 | X$KSMSS | 1小时 | 1天 |
| 3 | 确认预约区域的共享池的使用状况 | V$SHARED_POOL_RESERVED | 1小时 | 1天 |
| 4 | 确认共享池的碎片化状况(KROWN132267) | X$KSMSP | 1天 | 1天 |
| 5 | 确认LRU flash量 | X$KGHLU | 1小时 | 1天 |
| 6 | 获得SQL AREA的信息 | V$SQL | 1天 | 1天 |
每个子池的碎片化倾向分析(合计)
- 从X$KSMSP中分析每个子池的free统计的SUM(合计)的倾向。
–对于每个子池(X$KSMSS)进行更加详细的mesh分析,观点也与X$KSMSS相同
- X$KSMSP因为和共享池latch相关,需要慎重指定获得间隔
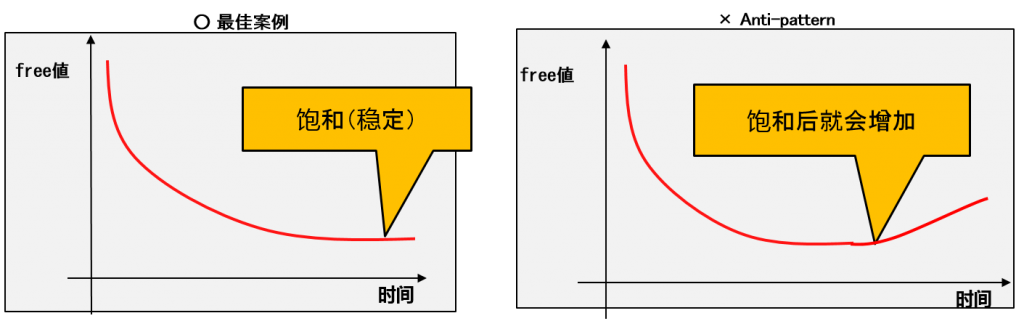
每个子池的碎片化倾向分析(平均)
- 从X$KSMSP中分析每个字heap的free统计的AVG(平均)的倾向。
–达到一定值后就会饱和
- Free的平均值持续下降就代表无法使用的小chunk在持续增加(碎片化越来越严重)。
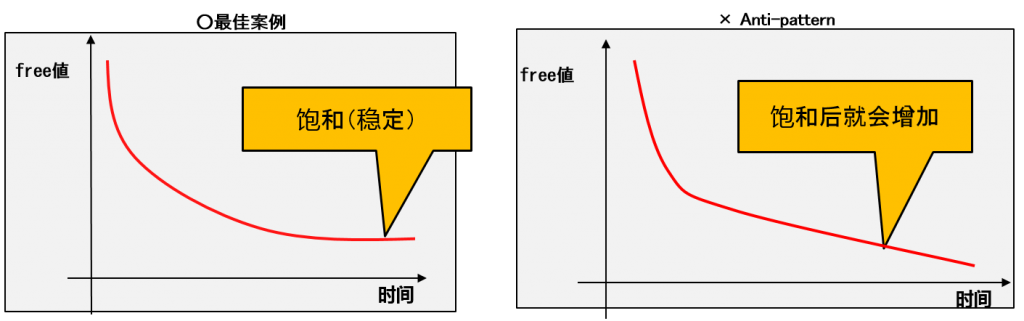
每个子heap的碎片化倾向分析( count )
- 从X$KSMSP中分析每个子heap的free统计的COUNT(个数)的倾向。
–到一定值就会饱和
- Free的个数持续增加就代表无法使用的小chunk在持续增加(碎片化越来越严重)

每个子heap的碎片化倾向分析(最大)
- 从X$KSMSP中分析每个子heap的free统计的最大的倾向
–到一定值就会饱和
- Free值的最大值到达一定程度的话,区域越大能用实际使用的区域也就越多

实际系统的ASM的共享池使用情况(memory_target=1.5G以及280M)
※但是,因为是正式Cutover之前的数据、
无法掌控实验层面的使用的同学请仅将结果作为参考值
memory_target=1.5G
- 在性能测试时,在正式环境(3节点RAC)的节点1中,ASM实例中发生了ORA-4031,ASM实例以及数据库实例出现down。另外,因为其影响,在节点2中,ASM实例就会发生ORA-569,并且ASM实例以及数据库实例出现down 。
★节点1的ASM实例的警报日志
Mon Jan 21 14:37:00 2013
ORA-04031: unable to allocate 3768 bytes of shared memory
(“shared pool”,”unknown object”,”sga heap(1,0)”,”ges enqueues”)
★节点2的ASM实例警报日志
之后,在节点2的ASM实例中, global enqueue 相关的错误
Mon Jan 21 14:37:02 2013
ORA-00569: Failed to acquire global enqueue
| ASM(GRID)的版本 | PROCESSES | MEMORY_TARGET | CPU核心数 | ASM的管理DB数 | DG数 | DG总尺寸 |
| 11.2.0.3.2 | 100 | 280MB | 52 | 1 | 18 | 91TB |
・Note 1363369.1中,ASM的MEMORY_TARGET推荐值大概在2012/10时,是272M之后变更为1.5GB了。因此设定为1.5GB之后,需要确认设定值的合适性。
※我重新回顾了一遍设计书的时间大概是2012/2前后
SGA,PGA(实例1)
- MEMORY_TARGET=1.5G(1,536M)
※启动时的尺寸 SGA:PGA=6:4=约921M : 约614M(KROWN 127002) - SGA 约914M byte
- 共享池约832M byte、large_pool 48M、asm_cache 32M、fixed_sga 约2M
- PGA 约622M byte

共享池的free的比例(实例1)
- MEMORY_TARGET=1.5G(1,536M)
- 共享池约832Mbyte
- 两周期间free memory 从685M byte递减到683M byte
(使用区域从147M增加到149M)
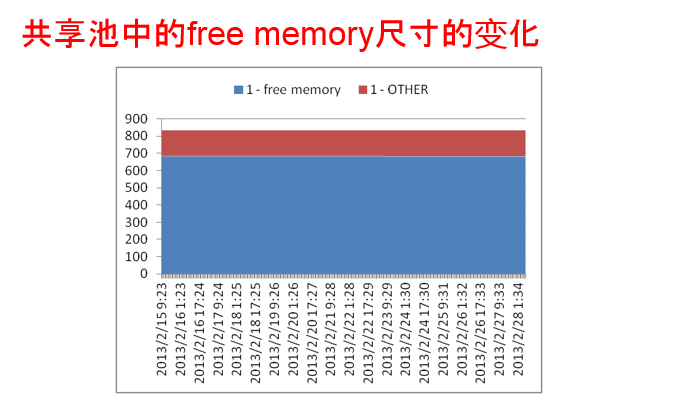
- free memory 从685M byte 减少到683M
- 子池0(隐藏free)个固定为624M byte
- 子池1是从61M byte减少到59 byte

memory_target=280M
- MEMORY_TARGET=280M
※启动时的尺寸 SGA:PGA=6:4=168M : 112M - SGA 约254Mbyte
- 共享池约164Mbyte、large_pool 64M、asm_cache 24M、fixed_sga 约2M
- PGA 约26Mbyte
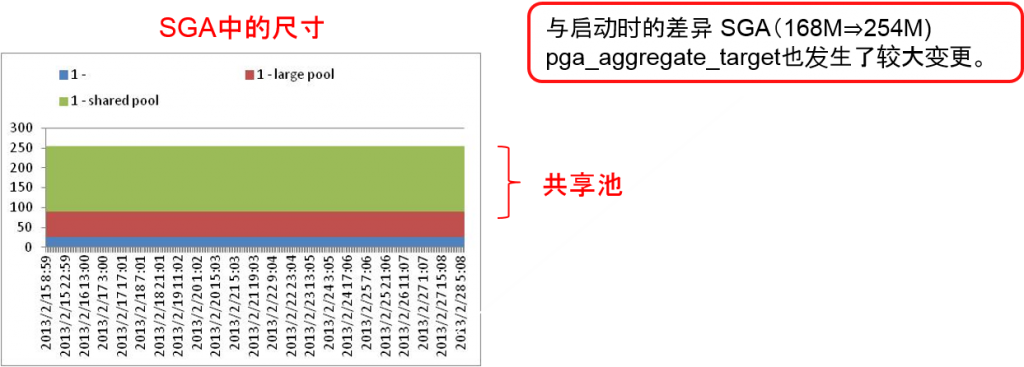
- 共享池实例1:约164Mbyte、实例2:约172Mbyte
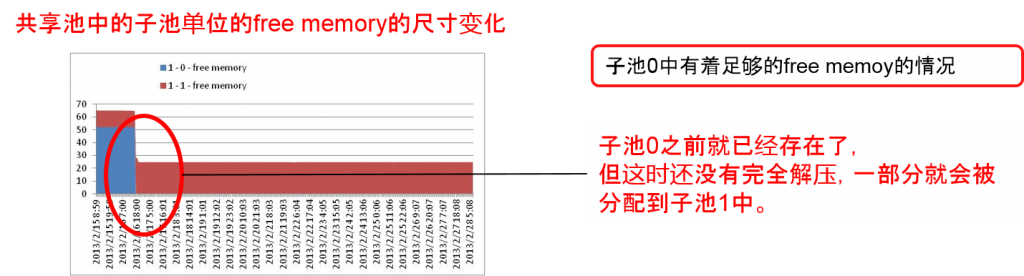
- free memory从约65Mbyte减少到约25Mbyte。之后几乎没有变化。

- 子池0(隐藏free)之前保证为50M byte但到2/16 18:00已经使用完毕
- 子池1之前保证为12M byte,到2/16 18:00增加,之后变更成约25M byte
- free memory 减少时,与减少的比例几乎相同的内存量将会被分配到「SQLA」「KGLH0」中。
※「SQLA」的区域,通过追加v$sql,可以指定增加的SQL。
pga_aggregate_target产生变化的话,cursor就会无效化,就会发生hard Perth。2周内(包括 2/16 18点)pga_aggregate_target的尺寸没有变化,被无效化后,首先发行的SQL尺寸就可能变大。

考察
- memory_target太小的话,就难以判断其是否处于健康状态
- ASM从客户的角度来看的话就是volume manager。
变更pga_aggregate_target,ASM实例上的SQL就会被hard Perth,
(子cursor增加),SQL AREA增加也是好现象。
⇒就像Exadata的最佳实例一样,ASM的实例如果使用sga_target的话就更加正确?
共享池的监控点
监控点(ASM的共享池) X$KSMSS
★前提
memory_target=1.5G
※memory_target太小的话,就非常难判断是健康的状态。
★监控点
需要注意到子池0枯竭的时机
※但是如果不观察一般使用的变化的话,就无法知道子池0到底消耗了多少基础。
★监控SQL
SELECT ksmsslen FROM x$ksmss where ksmdsidx=0 and ksmssnam=‘free memory‘
★前提
自动SGA、手动SGA相通的可以使用的方法
★监控点
缓冲区高速缓存是共享池的供给源,需要监控缓冲区高速缓存的初始值(用户定义值)与现行值之间是否存在差距。
★监控SQL
SELECT CURRENT_SIZE – USER_SPECIFIED_SIZE
FROM V$MEMORY_DYNAMIC_COMPONENTS
WHERE COMPONENT = ‘DEFAULT buffer cache’;
比如,实际分配了缓冲区高速缓存CURRENT_SIZE=30G的话,用初始化参数指定的最低值低于
db_cache_size=20G时,共享池的供给源就会枯竭。
但是,不观察日常使用的变化的话,就无法知道到底缓冲区高速缓存(供给源)消耗了多少base。
缓冲区高速缓存的最低值,因为是将4M X CPU数提高到Granule单位,所以比USER_SPECIFIED_SIZE的最小值还小的话,就会将上述USER_SPECIFIED_SIZE更换成最低值来进行监控
Leave a Reply