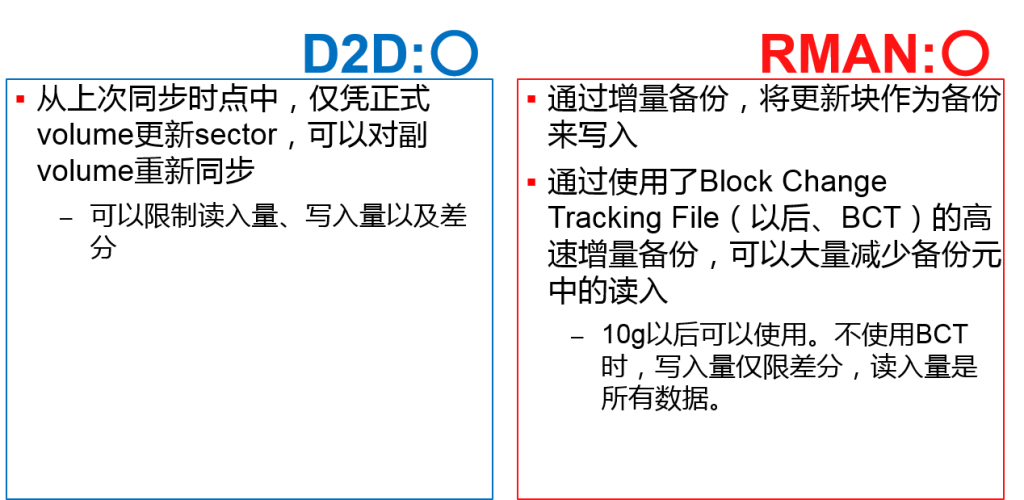
- vs. 存储功能备份
- 备份的全面损坏的风险
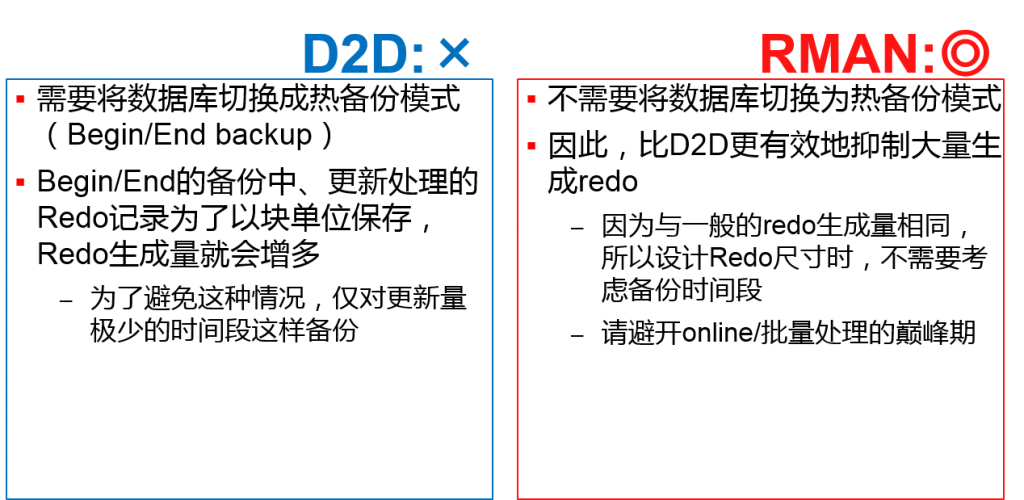
- 备份的性能与负荷
- 管理性
- 破损块对策
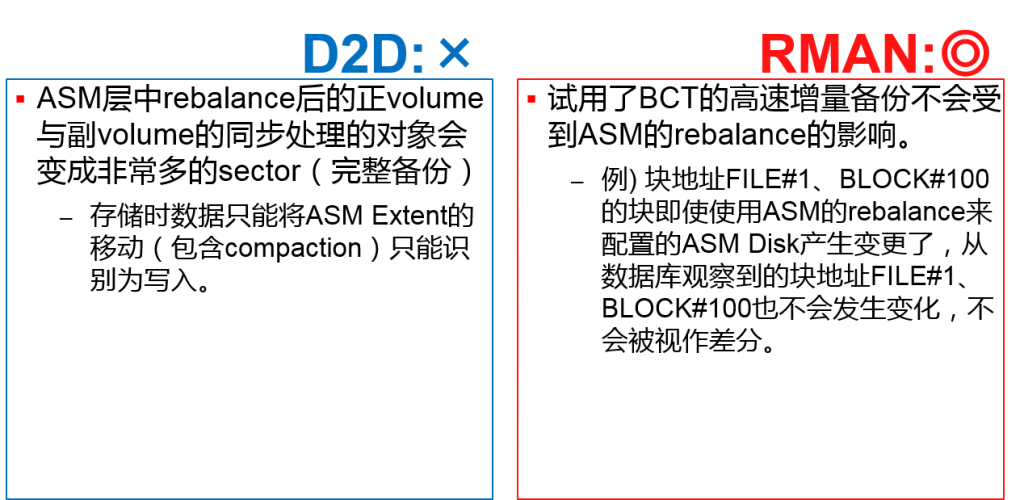
- ASMrebalance的影响
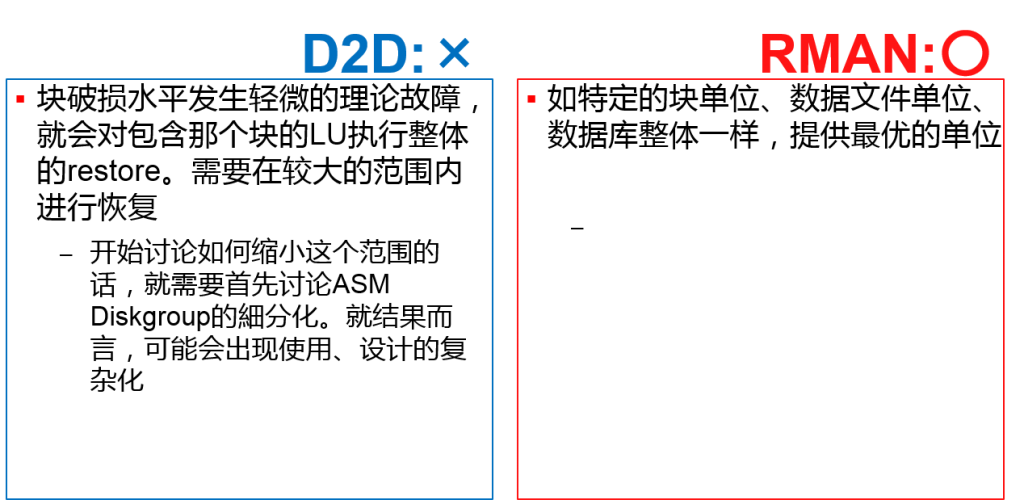
- restore& recovery的灵活性
D2D(Storage Backup) vs. Oracle Recovery Manager
| D2D | RMAN | ||
| 备份的全部损坏风险 | × 有全部损坏风险 | ◎ 可以通过高速增量备份回避 | |
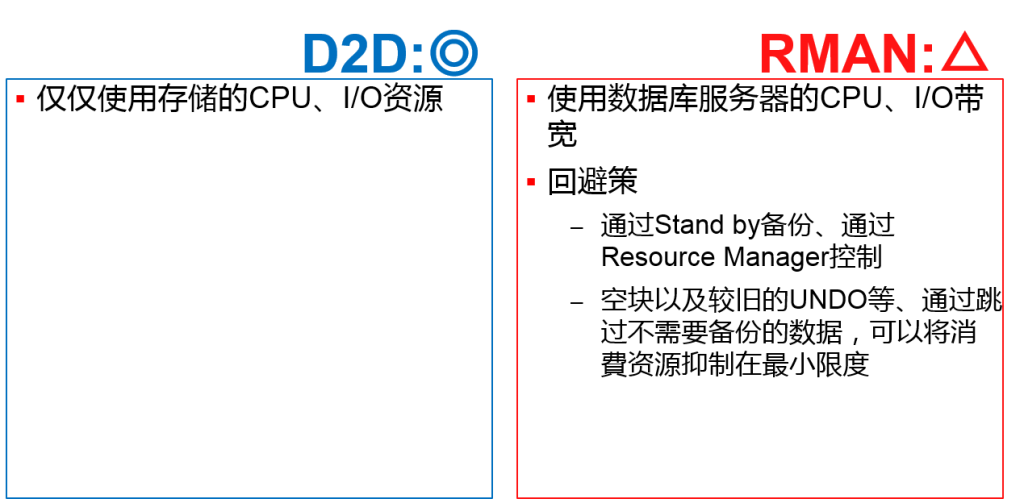
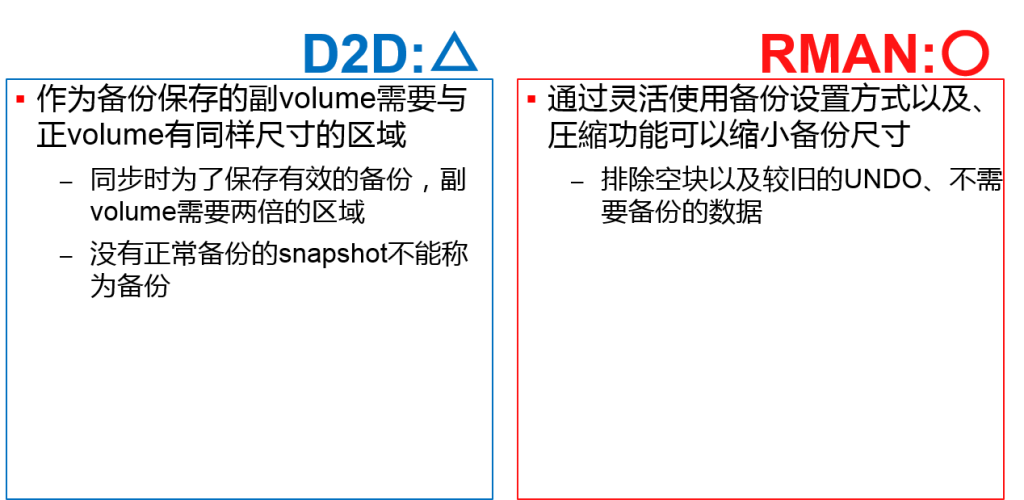
| 备份的 性能与负荷 |
消費资源 | ◎ 仅限存储的资源 | △ 使用服务器的资源 |
| 总I/O量 | ○ 仅限sector单位中的差分 | ○ 仅限块单位中的差分 | |
| 保持数据总量 | △ 与正式volume同等的尺寸 | ○ 可以压缩、减少 | |
| Redo生成量 | × 备份中増加 | ◎ 与一般的情况相同 | |
| 管理性 | × 人工管理比较麻烦 | ○ 自动管理 | |
| 泛用性 | △ 依赖于存储供应商 | ○ 从H/W结构中独立出来 | |
| 破损块对策 | × 不可以区分正常or破损 | ◎ 备份时可以检测 | |
| ASMrebalance的影响 | × 差分数据量大幅増加 | ◎ 没有影响 | |
| 备份的加密 | × 因为是正式volume的拷贝,所以无法加密 | ○ 可以加密 | |
| 价格 | × 数千万~数亿 | ○ EE标准功能 | |
| restore& recovery | 灵活性 | △ 最小也是LU单位 | ○ 可以对应块单位 |
| 管理性 | × 依赖于DBA的技能 | ○ 通过建议器自动判断 | |
备份方式的讨论結果 重新理解RMAN的优点
- 上一页的比较表是D2D中长期使用某巨大系统备份的优秀的Sier的同志们评价的结果。
–9ià11g的升级案例
–决定了大部分D2D的备份对策的状态
–通过联合使用OCS & SC & Dev ,仅过2个多月,就采用了RMAN
之后我将介绍RMAN的优点
D2D(Disk to Disk)备份
顺序
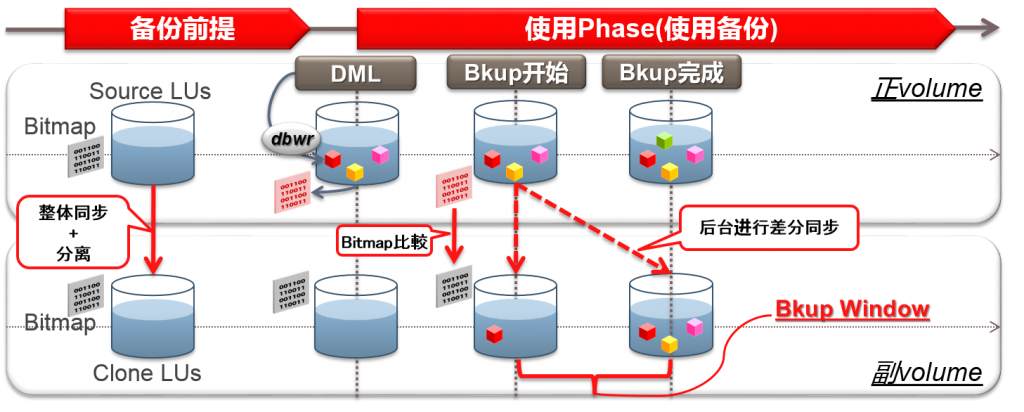
通过RMAN进行的高速增量备份
使用顺序
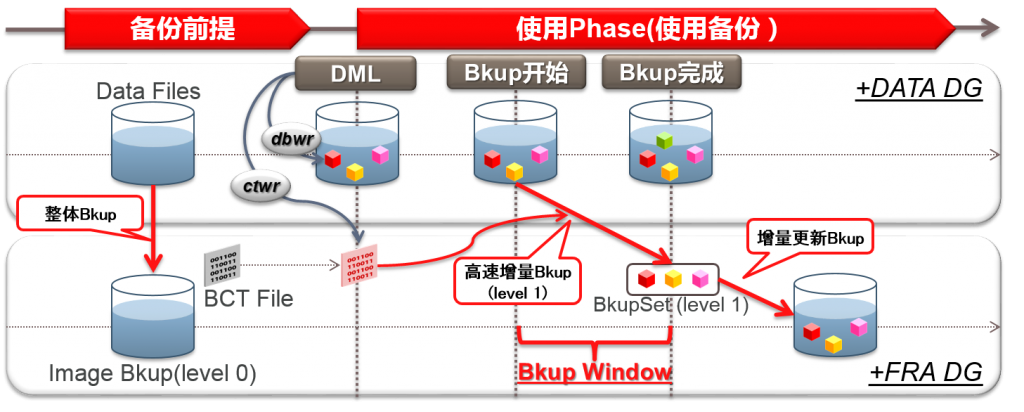
D2D vs. RMAN(高速增量备份)
使用顺序的比較与D2D的缺点
- 实际上,备份的数据量与复制时间都几乎相同
–D2D虽然给客户瞬间就可以完成备份的错觉。但实际上是后台进行数据拷贝
- 然后客户会提出这样的疑问,觉得二者是完全相同的!!
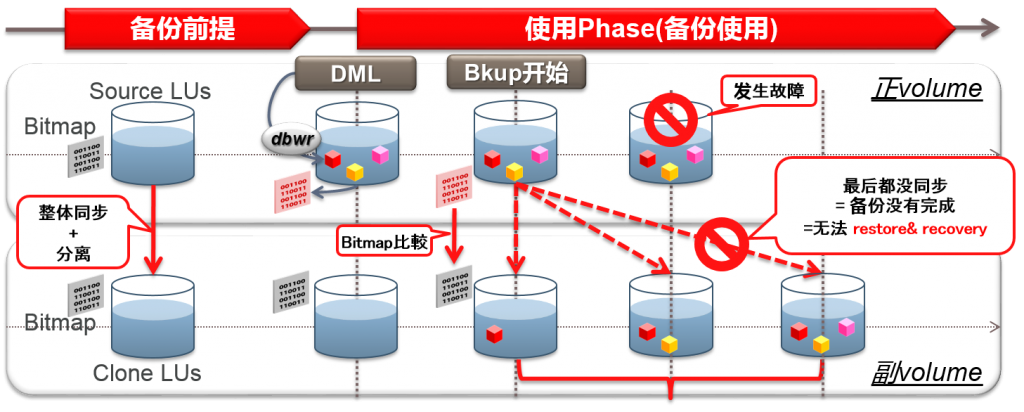
–使用D2D备份时,正式volume坏了的话,是否可以修复?
NG:因为会被覆盖,所以没有有效备份
必须有两个备份or tape备份
一方面,RMAN的分割增量与更新的Phase也没有问题
D2D(Disk to Disk)备份
同步中的发生故障的话就无法修复
备份的性能与负荷
消費资源
总I/O量
Block Change Tracking 的结构
BCT File的尺寸
- BCT的文件尺寸非常小
–数据库的尺寸以及Redo的线程数的比例
–与数据库更新频率无关
–初始尺寸10MB
–通常、数据库的块尺寸(?)约1/30,000 x节点数
- 300GB以内为10MB、600GB时为20MB+α
–不依赖于数据文件的尺寸(每个都在320KB以上)
=》 因为bitmap管理中尺寸都较小,所有没有较大的I/O
- 对BCT File写出时,不仅DBWR,CTWR也会执行事务与非同步
–不会影响Commit的响应时间
–DBWR对数据文件写入之前是否需要一起使用?
- CTWR进程仅仅在BCT有効的情况下启动
–经过Large Pool(不足时的Shared Pool)内的「CTWR dba buffer」
SQL> select pool,name,sum(bytes)/1024 from v$sgastat where name like 'CTWR'; POOL NAME SUM(BYTES)/1024 -------------------- ------------------ --------------- large pool CTWR dba buffer 1392
Block Change Tracking 的结构
备份时的I/O尺寸
- 备份时的I/O尺寸(块数)的最优化
–高速增量备份时仅仅读取更新块的操作
–变成随机I/O,通过完整备份,比较多块I/O的话吞吐量就会降低
–但是根据更新量不同,需要查看将I/O尺寸最优化的操作
备份的性能与负荷
保持数据总量
Redo生成量
备份的性能与负荷
Begin backup命令的高速化(虽然与RMAN无关)
- Oracle 9i Database中、Begin backup命令的响应时间较缓慢的问題(Oracle Database 10g Release1中解决完成)
–KROWN#120942
- 缓冲区高速缓存尺寸、数据文件数的比例,BEGIN BACKUP也需要时间
- 例) R9.2.0.8中,一个数据文件的Begin Backup所需要的时间
–缓冲区高速缓存10GB时:約0.06秒
–缓冲区高速缓存24GB时:約0.15秒(11gR2中0.00秒)
管理性 数据文件以外的备份相关文件

RMAN> DELETE OBSOLETE命令的修正
- RMAN的DELETE OBSOLETE命令是遵循删除对策,删除归档日志的命令
–可能出现无视删除对策,没有传送到Standby Site(或者没有完成应用)的归档日志被删除的情况
–通过Bug#12357315修正
破损块对策 是否是可以恢复的备份?
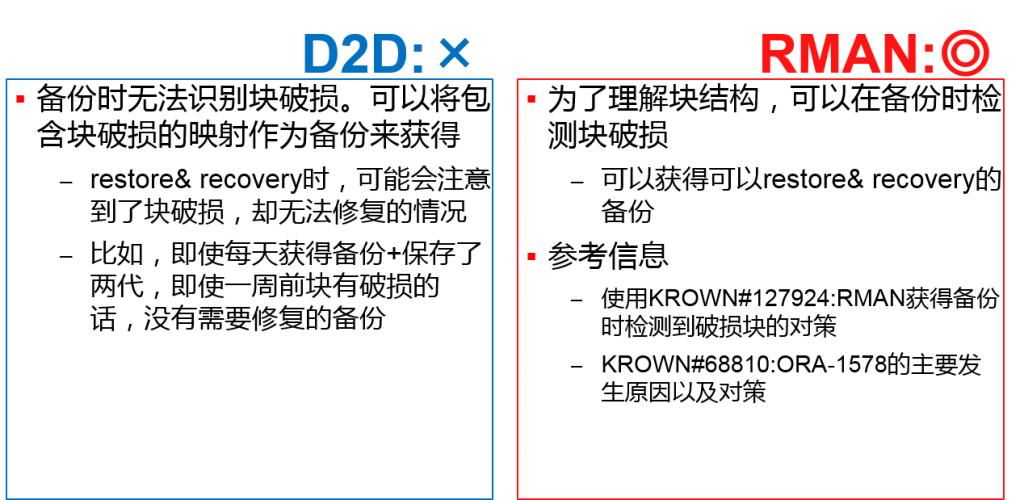
RMAN的块破损检测 默认设定中,检测到一个块破损的话就终止
RMAN> -- 执行增量备份 backup incremental level 1 tablespace RTEST1; Backup开始(开始时间: 12-07-23) 使用channelORA_DISK_1 使用channelORA_DISK_2 channelORA_DISK_1: 开始设定增量水平1的数据文件备份 channelORA_DISK_1: 在备份设定中指定数据文件 入力数据文件文件番号=00010 名前=+DATA/o11g/datafile/rtest1.282.789398885 channelORA_DISK_1: 启动piece 1(12-07-23) RMAN-00571: =========================================================== RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS =============== RMAN-00571: =========================================================== RMAN-03009: backup命令(ORA_DISK_1channel上) 在07/23/2012 16:22:00失败了 ORA-19566: 超过了破损块的限制0(文件+DATA/o11g/datafile/rtest1.282.789398885) SQL> select * from V$DATABASE_BLOCK_CORRUPTION; FILE# BLOCK# BLOCKS CORRUPTION_CHANGE# CORRUPTION_TYPE ---------- ---------- ---------- ------------------ --------------------------- 10 14980 1 6681461 FRACTURED RMAN> --特定块的修復 recover datafile 10 block 14980 ; 开始recover (开始时间: 12-07-23) 使用channelORA_DISK_1 使用channelORA_DISK_2 Stand by搜索完成,restore了1个块 Media Recovery开始 Media Recovery完成。消耗时间: 00:00:01 recover完成 (完成时间: 12-07-23) SQL> --查看破损对象 SELECT SEGMENT_TYPE, OWNER||'.'||SEGMENT_NAME "SCHEMA.TABLE" FROM DBA_EXTENTS WHERE 10 = FILE_ID AND 14996 BETWEEN BLOCK_ID AND BLOCK_ID+BLOCKS -1 ; SEGMENT_TYPE SCHEMA.TABLE ------------- ------------- TABLE RUSER.RTBL1
多个块出现破损时的注意事项
需要重复破损块的次数、以及下一个处理
开始备份
检测块破损 终止备份
修复破损块
可以设定破损块检测数的上限(MAXCORRUPT)
RMAN> -- 总之先无视,完成备份。
RUN
{
SET MAXCORRUPT FOR DATAFILE 10 TO 128 ;
backup incremental level 1 tablespace RTEST1;
}
MAXCORRUPT的弱点
- 通过设定MAXCORRUPT,可以一边检测多个快破损一边完成备份
–已检测到的破损块可以通过以下命令来一起修复
RMAN> RECOVER CORRUPTION LIST;
- 但是,备份是否是正常的呢?
- 重新执行一次高速增量备份,是否可以备份修复完成的状态呢?
- 由于以下两个原因,可能会出现无法获得修复完成的块的备份的情况。
–因为RMAN的backup完成所以BCT的版本切换了
- 由于MAXCORRUPT设定,即使检测到块破损,如果backup命令正常完成的话,通过切换BCT的版本,就无法获得同样范围的备份。
–RMAN的块修复没有在BCT中tracking
- 通过RMAN的recover corruption命令修复破损块的I/Oは、因为没有在BCT中tracking,只要应用没有更新,就不会对块进行高速增量备份
- 通过与其他Oracle的数据破损对策(ASM镜像等)与的併用
–备份时时将检测到的破损块数最小化
–MAXCORRUPT的设定是默认的
–检测到2次时(循环)对数据库整体执行VALIDATE
- 请开发RMAN的结构
–备份时如果检测到了破损块就自动修复
- (附赠)只是检测到一个破损块
–BCT文件中tracking完成的块全部修复完成(高速增量备份对象的块)
通过BCT查看tracking完成的块
SQL> update RTBL1 set COL2='hoge' where COL1=100; commit; select dbms_rowid.rowid_relative_fno(rowid,'SMALLFILE') "FNO", dbms_rowid.rowid_block_number(rowid,'SMALLFILE') "BNO" from RTBL1 where COL1=100; FNO BNO ---------- ---------- 10 146 variable FNO number; execute :FNO := 10 select B.* from X$KRCFDE A, X$KRCBIT B where A.FNO = B.FNO and A.FNO = :FNO and A.CURR_VERCNT = B.VERCNT ; ADDR INDX INST_ID CTFBNO VERCNT VERTIME CSNO FNO BNO BCT ---------------- ---------- ---------- ---------- ---------- -------- ---------- ---------- ---------- ---------- 00002B7E775BAED8 2519 1 4096 16 12-07-23 1 10 144 4 ===> 144~148(144+4)的块被BCT File追踪了。
ASMrebalance的影响 与之前备份你的差分数据量的差异
查看BCT File中是否完成tracking(4
本环境中,因为Fileno=3是UNDO表区域,所以推测为UNDO表区域的変更已经被Tracking了。
SQL> -- 将BCT有效化
ALTER DATABASE ENABLE BLOCK CHANGE TRACKING USING FILE '+DATA(CHANGETRACKING)' REUSE;
SQL> -- 有效化完成之后的Bitmap Extent供应商的状态
set linesize 150 pagesize 5000
select CTFBNO, FNO, VERCNT, to_char(VERTIME, 'YYYY/MM/DD HH24:MI:SS'),
HIST_FIRST, HIST_LAST, HIST_EXTCNT, HIST_VERCNT, HIST_VERTIME,
LOW, HIGH from X$KRCFBH;
CTFBNO FNO VERCNT TO_CHAR(VERTIME,'YY HIST_FIRST HIST_LAST HIST_EXTCNT HIST_VERCNT HIST_VER LOW HIGH
---------- ---------- ---------- ------------------- ---------- ---------- ----------- ----------- -------- ---------- ----------
2304 0 0 0 0 0 0 0 0
2368 0 0 0 0 0 0 0 0
2432 3 1 2012/06/18 19:03:39 0 0 0 0 0 0
2496 0 0 0 0 0 0 0 0
2560 0 0 0 0 0 0 0 0
2624 0 0 0 0 0 0 0 0
本环境中、Fileno=9,构成制成段的SSD_TBS_1表区域的数据文件
SQL> -- 制成一个段。
create table TEST1 (col1 number) segment creation immediate tablespace SSD_TBS_1;
SQL> -- 是否完成tracking
select CTFBNO, FNO, VERCNT, to_char(VERTIME, 'YYYY/MM/DD HH24:MI:SS'),
HIST_FIRST, HIST_LAST, HIST_EXTCNT, HIST_VERCNT, HIST_VERTIME,
LOW, HIGH from X$KRCFBH;
CTFBNO FNO VERCNT TO_CHAR(VERTIME,'YY HIST_FIRST HIST_LAST HIST_EXTCNT HIST_VERCNT HIST_VER LOW HIGH
---------- ---------- ---------- ------------------- ---------- ---------- ----------- ----------- -------- ---------- ----------
2304 1 1 2012/06/18 19:03:39 0 0 0 0 0 0
2368 2 1 2012/06/18 19:03:39 0 0 0 0 0 0
2432 3 1 2012/06/18 19:03:39 0 0 0 0 0 0
......................
4352 0 0 0 0 0 0 0 0
4416 9 1 2012/06/18 19:03:40 0 0 0 0 0 0
4480 0 0 0 0 0 0 0 0
本环境中、Fileno=9是构成制成段的SSD_TBS_1表区域的数据文件
SQL> --制成一个段。
create table TEST1 (col1 number) segment creation immediate tablespace SSD_TBS_1;
SQL> --是否完成tracking
select CTFBNO, FNO, VERCNT, to_char(VERTIME, 'YYYY/MM/DD HH24:MI:SS'),
HIST_FIRST, HIST_LAST, HIST_EXTCNT, HIST_VERCNT, HIST_VERTIME,
LOW, HIGH from X$KRCFBH;
CTFBNO FNO VERCNT TO_CHAR(VERTIME,'YY HIST_FIRST HIST_LAST HIST_EXTCNT HIST_VERCNT HIST_VER LOW HIGH
---------- ---------- ---------- ------------------- ---------- ---------- ----------- ----------- -------- ---------- ----------
2304 1 1 2012/06/18 19:03:39 0 0 0 0 0 0
2368 2 1 2012/06/18 19:03:39 0 0 0 0 0 0
2432 3 1 2012/06/18 19:03:39 0 0 0 0 0 0
......................
4352 0 0 0 0 0 0 0 0
4416 9 1 2012/06/18 19:03:40 0 0 0 0 0 0
4480 0 0 0 0 0 0 0 0
SQL> -- 对ASM Diskgroup追加磁盘,执行rebalance
alter diskgroup SSDG drop disk SSDG_0001 rebalance power 11 wait;
SQL> -- 确认tracking信息是否被变更
select CTFBNO, FNO, VERCNT, to_char(VERTIME, 'YYYY/MM/DD HH24:MI:SS'),
HIST_FIRST, HIST_LAST, HIST_EXTCNT, HIST_VERCNT, HIST_VERTIME,
LOW, HIGH from X$KRCFBH
where FNO > 3 and FNO != 9 ;
no rows selected
通过ASM rebalance查看tracking信息是否发生变化
换言之,通过RMAN,不会影响高速增量备份
restore& recovery的灵活性
根据故障范围,以最优的单位进行restore& recovery
D2D(Storage Backup) vs. Oracle Recovery Manager
| D2D | RMAN | ||
| 备份的全部损坏风险 | × 有全部损坏的风险 | ◎ 通过高速增量备份回避 | |
| 备份的 性能与负荷 |
消費资源 | ◎ 仅限存储的资源 | △ 使用服务器的资源 |
| 总I/O量 | ○ 仅限sector单位中的差分 | ○ 仅限块单位中的差分 | |
| 保持数据总量 | △ 正volume与同等的尺寸 | ○ 可以压缩/减少 | |
| Redo生成量 | × 备份中会增加 | ◎ 与一般情况相等 | |
| 管理性 | × 手动管理变得复杂 | ○ 世代管理的自动化 | |
| 汎用性 | △ 依赖于存储供应商 | ○ 从H/W结构中独立 | |
| 破损块对策 | × 正常or破损的区別も不可 | ◎ 备份时可以检测 | |
| ASMrebalance的影响 | × 几乎对整个备份都有 | ◎ 没有影响 | |
| 备份的加密 | × 正volume的拷贝,所以不可以 | ○ 可以加密 | |
| 价格 | × 数千万~数亿 | ○ EE标准功能 | |
| restore& recovery | 灵活性 | △ 最小也是LU单位 | ○ 可以通过块单位处理 |
| 管理性 | × 依赖DBA的skill | ○ 通过建议器自动判断 | |
Leave a Reply