SMON的作用还包括清理obj$数据字典基表(cleanup obj$)
OBJ$字典基表是Oracle Bootstarp启动自举的重要对象之一:
SQL> set linesize 80 ;
SQL> select sql_text from bootstrap$ where sql_text like 'CREATE TABLE OBJ$%';
SQL_TEXT
--------------------------------------------------------------------------------
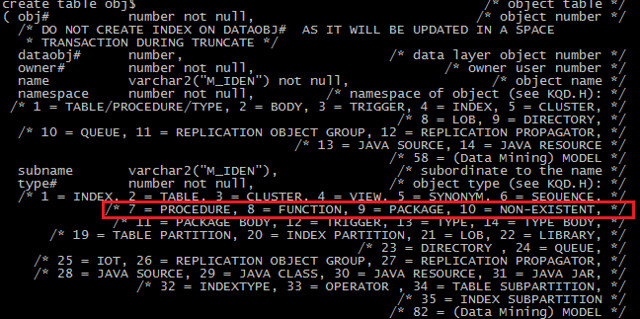
CREATE TABLE OBJ$("OBJ#" NUMBER NOT NULL,"DATAOBJ#" NUMBER,"OWNER#" NUMBER NOT N
ULL,"NAME" VARCHAR2(30) NOT NULL,"NAMESPACE" NUMBER NOT NULL,"SUBNAME" VARCHAR2(
30),"TYPE#" NUMBER NOT NULL,"CTIME" DATE NOT NULL,"MTIME" DATE NOT NULL,"STIME"
DATE NOT NULL,"STATUS" NUMBER NOT NULL,"REMOTEOWNER" VARCHAR2(30),"LINKNAME" VAR
CHAR2(128),"FLAGS" NUMBER,"OID$" RAW(16),"SPARE1" NUMBER,"SPARE2" NUMBER,"SPARE3
" NUMBER,"SPARE4" VARCHAR2(1000),"SPARE5" VARCHAR2(1000),"SPARE6" DATE) PCTFREE
10 PCTUSED 40 INITRANS 1 MAXTRANS 255 STORAGE ( INITIAL 16K NEXT 1024K MINEXTEN
TS 1 MAXEXTENTS 2147483645 PCTINCREASE 0 OBJNO 18 EXTENTS (FILE 1 BLOCK 121))
触发场景
OBJ$基表是一张低级数据字典表,该表几乎对库中的每个对象(表、索引、包、视图等)都包含有一行记录。很多情况下,这些条目所代表的对象是不存在的对象(non-existent),引起这种现象的一种可能的原因是对象本身已经被从数据库中删除了,但是对象条目仍被保留下来以满足消极依赖机制(negative dependency)。因为这些条目的存在会导致OBJ$表不断膨胀,这时就需要由SMON进程来删除这些不再需要的行。SMON会在实例启动(after startup of DB is started cleanup function again)时以及启动后的每12个小时执行一次清理任务(the cleanup is scheduled to run after startup and then every 12 hours)。
我们可以通过以下演示来了解SMON清理obj$的过程:
SQL> BEGIN
2 FOR i IN 1 .. 5000 LOOP
3 execute immediate ('create synonym gustav' || i || ' for
4 perfstat.sometable');
5 execute immediate ('drop synonym gustav' || i );
6 END LOOP;
7 END;
8 /
PL/SQL procedure successfully completed.
SQL> startup force;
ORACLE instance started.
Total System Global Area 1065353216 bytes
Fixed Size 2089336 bytes
Variable Size 486542984 bytes
Database Buffers 570425344 bytes
Redo Buffers 6295552 bytes
Database mounted.
Database opened.
SQL> select count(*) from user$ u, obj$ o
2 where u.user# (+)=o.owner# and o.type#=10 and not exists
3 (select p_obj# from dependency$ where p_obj# = o.obj#);
COUNT(*)
----------
5000
SQL> /
COUNT(*)
----------
5000
SQL> /
COUNT(*)
----------
4951
SQL> oradebug setospid 18457;
Oracle pid: 8, Unix process pid: 18457, image: oracle@rh2.oracle.com (SMON)
SQL> oradebug event 10046 trace name context forever ,level 1;
Statement processed.
SQL> oradebug tracefile_name;
/s01/admin/G10R2/bdump/g10r2_smon_18457.trc
select o.owner#,
o.obj#,
decode(o.linkname,
null,
decode(u.name, null, 'SYS', u.name),
o.remoteowner),
o.name,
o.linkname,
o.namespace,
o.subname
from user$ u, obj$ o
where u.use r#(+) = o.owner#
and o.type# = :1
and not exists
(select p_obj# from dependency$ where p_obj# = o.obj#)
order by o.obj#
for update
select null
from obj$
where obj# = :1
and type# = :2
and obj# not in
(select p_obj# from dependency$ where p_obj# = obj$.obj#)
delete from obj$ where obj# = :1
/* 删除过程其实较为复杂,可能要删除多个字典基表上的记录 */
现象
我们可以通过以下查询来了解obj$基表中NON-EXISTENT对象的条目总数(type#=10),若这个总数在不断减少说明smon正在执行清理工作
select trunc(mtime), substr(name, 1, 3) name, count(*)
from obj$
where type# = 10
and not exists (select * from dependency$ where obj# = p_obj#)
group by trunc(mtime), substr(name, 1, 3);
select count(*)
from user$ u, obj$ o
where u.user#(+) = o.owner#
and o.type# = 10
and not exists
(select p_obj# from dependency$ where p_obj# = o.obj#);
如何禁止SMON清理obj$基表
我们可以通过设置诊断事件event='10052 trace name context forever'来禁止SMON清理obj$基表,当我们需要避免SMON因cleanup obj$的相关代码而意外终止或spin从而开展进一步的诊断时可以设置该诊断事件。在Oracle并行服务器或RAC环境中,也可以设置该事件来保证只有特定的某个节点来执行清理工作。
10052, 00000, "don't clean up obj$"
alter system set events '10052 trace name context forever, level 65535';
Problem Description: We are receiving the below warning during db startup:
WARNING: kqlclo() has detected the following :
Non-existent object 37336 NOT deleted because an object
of the same name exists already.
Object name: PUBLIC.USER$
This is caused by the SMON trying to cleanup the SYS.OJB$.
SMON cleans all dropped objects which have a SYS.OBJ$.TYPE#=10.
This can happen very often when you create an object that have the same name as a public synonym.
When SMON is trying to remove non-existent objects and fails because there are duplicates,
multiple nonexistent objects with same name.
This query will returned many objects with same name under SYS schema:
select o.name,u.user# from user$ u, obj$ o where u.user# (+)=o.owner# and o.type#=10
and not exists (select p_obj# from dependency$ where p_obj# = o.obj#);
To cleanup this message:
Take a full backup of the database - this is crucial. If anything goes wrong during this procedure,
your only option would be to restore from backup, so make sure you have a good backup before proceeding.
We suggest a COLD backup. If you plan to use a HOT backup, you will have to restore point in time if any problem happens
Normally DML against dictionary objects is unsupported,
but in this case we know exactly what the type of corruption,
also you are instructing to do this under guidance from Support.
Data dictionary patching must be done by an experienced DBA.
This solution is unsupported.
It means that if there were problems after applying this solution, a database backup must be restored.
1. Set event 10052 at parameter file to disable cleanup of OBJ$ by SMON
EVENT="10052 trace name context forever, level 65535"
2. Startup database in restricted mode
3. Delete from OBJ$, COMMIT
SQL> delete from obj$ where (name,owner#) in ( select o.name,u.user# from user$ u, obj$ o
where u.user# (+)=o.owner# and o.type#=10 and not exists (select p_obj# from
dependency$ where p_obj# = o.obj#) );
SQL> commit;
SQL> Shutdown abort.
4. remove event 10052 from init.ora
5. Restart the database and monitor for the message in the ALERT LOG file