服务器整合以及数据整合
广义来说,数据整合就是服务器整合的架构之一。在服务器整合之中,有很多种架构。一般而言,应该以理论整合、地址整合、物理整合为焦点来讨论,所以这次不会说到应用整合。并且,数据整合是服务器整合的架构之一,但本文并不打算将数据整合特殊化,所以我们故意将数据整合以及服务器整合来分开说明。没有特别含义的情况下,“服务器整合”意味着服务器理论整合、服务器为止整合、服务器位置整合、然后数据整合也以为和需要将数据库进行再次架构、变更的数据的整合。
在此,为了明确服务器整合以及数据整合所需要的理由、环境的变化以及问题点,我们将说明导入了分散配置的系统的背景。
导入分散配置服务器的系统的背景是上世纪90年代,提倡技术的开源化的时代。伴随着开源技术的渗透,以PC服务器的使用为中心的终端Computing得到了增加。这样的架构是一个,对于终端用户所需要的信息,用必要的形式,在需要时,可以使用的方法。
并且,上世纪90年代的网络与其他因素相比较(服务器、软件、管理者的人工费等),价格稍高,所以系统都被尽量设计成不经过网络而得到数据的形式。另外,因为服务器自身的处理能力也是有限度的,一般而言系统架构都是在Downsizing之名之下,之下分散处理。
接下来,我想说明Downsizing、分散,在开源的世界中,环境发生了怎样的变换。
上世纪90年代使人们都选择分散配置系统的IT环境,如今也发生了翻天覆地的变换。首先是飞跃性的技术进步,服务器性能得到了飞跃性地提高,网络带宽也得到了扩展以及成本也得到了降低。服务器的能力单纯就CPU clock数来说,提高了几十倍到几百倍,而网络带宽的性能则提高了几百倍到几千倍。因此,至今不得不分散就无法处理的业务,都可以聚集到极少数几个服务器中来执行处理。
另外,在如今IT泡沫破灭的当今的各大企业中,正在积极推行提高资源利用效率、减少成本。比如,如利用Outsourcing来扩张自己的核心竞争力一样,经常可以看到有尽量减少核心业务以外所花费的时间来提高竞争力的情况。伴随着这样的变化,服务器以及系统的管理业务等,由这方面的专家,信息系统部,外包商来集中执行。用户为了更高效执行业务,利用系统,渐渐将其移动到不执行这些运用以及管理的架构中。
由这些背景,与环境的变换,我们就明确问题是什么,要解决什么。我们可以想到有以下四种有问题的要素。
a.TCO
b.系统可信性
c.安全水平
d.数据质量
a. TCO
相对于硬件的性能提高以及成本性能的提高,系统维护、管理业务中所必需的人工费却并没有下降。即使是在现在这个不景气的环境下,人工费的价格刚性还是较高,特别在日本人工费的高昂都被当做一个社会问题来研究了。换言之,要就这样一直维持进行了分散配置的架构的情况下,即使硬件、软件、网络的成本都下降了,在使用以及管理时所花费的成本也并不会下降。当之前分散配置是主流时,减少网络成本是个重要的课题,而现在最重要的是减少人工费。换言之,减少人工费对减少成本产生的效果更好。那么要减少人工费的话,就需要减少将会成为使用、管理对象的服务器数、种类以及对象软件的种类。
另外,在将服务器于每个用户部门中进行分散配置的系统中,执行使用以及管理的就不是信息系统部门,而是用户部门了。备份工作等使用工作以及面向故障的一次性对应,现在都变成由用户部门的用户来执行了。由此,使用管理处理就会从信息系统部门移动到用户部门,后果就是用户本来应该花费在执行的最优先业务上的时间,变成花在了使用、管理上了,造成资源利用效率降低。虽然通过将服务器从用户部门移动到信息系统部门,或者系统运用管理员配置到各个用户部门中,有望解决这个问题,但实际上要在各个用户部门中分配管理员的费用都是非常高的。
b.系统可信性
在进行分散配置开始时,我想通过分散配置多个服务器,从而提高系统整体的可信度,但实际上,在每个服务器的可用性都较低的情况下,我发现系统整体的可信性并不会继续提高。特别是实时指向较高,在流程都被明确地定义,每个业务进程的关联都得到加强的先到业务系统中,可能因为一个系统停止,导致全部的流程也停止。另外,被分散配置的服务器使用比较便宜的PC服务器的情况较多,无法取得足够的冗长结构从而无法提高可信性。要解决这个问题,就应该使用具有充分可信性的服务器,但要将现有的所有服务器全部切换成高可信性服务器的话,可能需要花费大量成本。并且考虑到使用管理多台服务器的成本的话,集中配置Fault-tolerant machine, cluster system以及大规模SMP machine来使用反而可以减少总体成本,并且可以提高整体可信性。特别是对于cluster system需要大量费用的情况,效果很好。并且,通过与便宜的存储组合,构成服务器的情况下,就无法对发生故障的磁盘进行热插拔,会出现无法取得由于冗长镜像所进行的高速备份的限制。通过使用SAN、NAS Storage,可以提高所有服务器的可信性。
在用各用户部门执行用户管理的情况下,特别是备份、恢复相关的应用水平可能发生错误。服务水平、复原顺序、系统复原优先顺序、备份保持期间,根据各个部门不同会有差异,根据发生故障的系统不同,可能会使得系统整体的MTTR产生变动,从故障发生时的故障转移地址的能力预测是很难的等系统使用的观点来看的话,不确定因素太多,风险也太大。解决方法有,对系统整体进行备份,恢复方案等,由信息系统部指定多的,将各部门管理这作为对象来训练的方案,但对于必须优先业务的用户部门的资源来说,这对成本的负担太过沉重,所以在没有如方案所述取得备份的情况下,就无法使用通常的恢复顺序,导致故障长期化。引起,要减少服务器的聚集数,从remote进行备份、恢复也是可行的。
c. 安全水平
在用户部门中执行服务器管理时,有在安全性较低的环境中使用/管理的情况。将业务处理中成为关键的服务器放在安全水平较低的环境中不管的话,这不仅可能危害到整个部门,甚至可能危害到全公司。如果是储存对于那个部分相当关键的数据的情况下,如果产生故障,就应该立即停止业务。并且,部门服务器连接公共网络的情况较多,因为网络的分割,对于网上数据的保护就不够充分,可能造成数据流出。如果在设置地点不安排专用的空间的话,就可能导致不相干的人也可以访问数据,并且无法对抗火灾、地震。要防止数据泄露,在发生故障时也能继续业务,就需要维持充分的安全性。聚集服务器,补充设置地点的设备,导入安全管理软件,重新架构网络。
d.数据质量
在分散配置系统中,用户部门会用架构业务上必要的处理的单位来架构。因此,对于全公司的必须得到统一管理的数据,各自系统就可以保持独自的形态来构筑系统。因此,分散系统的系统架构中,就会发生被称为Information Island的数据服务器。系统之间无法协作,或者说因为不够充分,会经常有数据重复等数据非一致的状态。比如,订购业务系统中的顾客数据与支持业务系统中顾客数据的重复与不一致。换言之,我们可以说这就是数据质量低下。另外,数据重复并被保持是指,出现了白白增加储存数据的存储设备、内存等浪费性的IT投资。在系统之间,对顾客的数据进行维护,但维护的时间不太准确的情况下,就会破坏数据的一致性。最近的趋势都是追求实时性,请大家尽可能回避这样的情况,可能的话,请在所有系统中都保持数据的一贯性。
以上整理如下表1.1所示。
| CTO | 信赖性 | 安全性 | 数据品质 | |
| 问题 | 管理者增加
服务器很多 配置地址多样 SW种类 HW种类 ->管理成本增加 |
不准备备份
不充分的冗长性 对整个系统的冲击 |
第三者的访问
不准备监视历史 耐故障性较低的机器 耐故障性较低的存放地点 |
欠缺一致性的数据
数据重复 未整合的数据 |
数据整合、服务器整合的现状
如上所述,服务器与数据由于分散配置会导致各种问题发生。要改善这个问题,就需要重新考虑服务器分散配置这种想法,所以就有了集中配置服务器,或者将其整合,减少台数的方法。
现在,在日本,包含已经完成的企业,这三年中,有约45%的企业都决定执行整合。另外,还有39%的企业表示对此很有兴趣(图1.1)。我们可以看出服务器整合、数据整合是非常重要的。在此,我将说明一些服务器整合、数据整合的架构、特征,然后考虑这到底适合怎样的整合模式。
广义的服务器整合中,有理论整合、地址整合、物理整合、数据整合等架构。在此,我将分别说明这些定义、概要以及特征。
在各用户部门中,将服务器进行分散配置来进行处理是一直以来的架构(图1.2)。但这会导致增加管理成本,可信度较低,数据重复,安全水平较低等问题。
将多个服务器看成一个理论上的一台大服务器的架构(图1.3)
从已经分散的服务器内部的结构,即是OS以及DBMS开始,执行Middleware等的标准化,就可以制作统一的运用管理的基盘,并且使用系统使用管理工具的远程监视等功能可以在中央聚集来制作可行的结构。这样的话,服务器在地理性,位置性上还是分散的,但可以达到假想式的统合系统,就不需要每个服务器都需要配备有专门技术的管理者了。
有各种各样功能的产品,需要企业选择符合自己情况的选择,另外,各种各样的产品都有与Oracle的协作功能,服务器数以及分散度较少的情况下,这是最简单的情的可以实现的整合方法。
这是将已经分散的服务器移动到一个地方或者多个地方的IT部门中,总括起来集中管理的架构。由此,用户部门可以从管理服务器等多余的工作中得到解放。
执行位置整合时,需要特别留意经过WAN上的network traffic。比如,将处理大容量数据(CAD数据、图像数据等)的服务器从各个分公司移动到总公司等进行位置整合的情况下,由于大容量数据的传送,WAN的traffic就会增大,系统的响应就会恶化。
另外不停止业务就执行服务器的移动的情况下,需要准备移动时的代替服务器,由此可能导致成本短期内增加。
将架构不同的多个服务器进行整合的情况下,仅仅将服务器聚集在1个地方,整合的效果非常有限所以在执行位置整合前需要讨论服务器构成的标准化以及共同化等理论整合。
物理整合
这是将多个小型服务器整合到大型服务器或者Rack mount型服务器中的架构(图1.5)。最近,支持理论区划分割功能的服务器很多,可以在一台服务器中构造多台虚拟的服务器。通过减少服务器的台数,不仅可以减少硬件成本,也可以减少运用管理成本。但因为系统的独立性较低,在一个地方发生的故障可能影响到多个业务。另外,与位置整合相同,需要考虑WAN上的traffic管理。
基本来说,物理整合是指,将执行理论结合的系统,与同一的架构上的可扩展性的高度大规模服务器进行整合的架构。但是,如电子邮件服务器以及ERP package用服务器等,不需要应用移植的情况下,不同的架构的服务器的整合也是可行的。
通过以上已经说明的一些服务器整合架构的内容,就已经可以解决TCO、安全水平、系统可信性相关的一部分问题了。但是,数据库使用,管理相关成本、数据量访问的可用性、数据质量等一些数据分散配置相关的问题还没能得到解决。要解决这些问题,就需要数据整合。接下来,我将简单介绍数据整合的架构。
数据整合架构是指将多个服务器的数据整理到1个服务器之中,用一个存储来管理,或者将多个服务器上的数据库进行理论性约束,实现将数据可以进行一元性管理的架构。数据整合概括分类的话有以下三种。
以下三种架构只是在此简单接触,详细内容从第二章开始。
只是仅仅整合数据的储存为止的架构。这种情况下,在数据分散时就会出现问题,可以说这是下一的数据整合。
这是理论性地整合数据的架构。分离需要保留的重复数据保持一致性的数据。利用其他的现有系统。实际运行提供透过性的Layer。在服务器进行理论整合是非有效的。
这是将所有的数据整合到一个数据库中的架构。通过数据库的理论设计以及物理设计,可以删除重复数据、保持数据的一贯性,从而提高数据质量。这是服务器物理整合的前提。
以上,我们讲解了服务器整合以及数据整合的架构。总结如下图所示。
| 优点 | 缺点 | 前提条件 | ||
| 服务器整合 | 理论整合 | 便于 导入
有各种各样的整合产品 |
整合产品成本高
服务器多的话效果不好 无法提高可信度 无法提高数据质量 |
没有 |
| 位置整合 | 提高服务器管理效率
不需要重新设计系统 提高安全水平 |
需要管理每个服务器
可信性提高不明显 服务器多的话效果不好 可能导致网络负荷上升 无法提高数据质量 |
尽可能用理论整合来完成 | |
| 物理整合 | 提高可信性
服务器管理效率很高 安全性得到提升 |
需要重新设计HW、Net
可能导致网络负荷上升 无法提高数据质量 |
完成了理论整合 | |
| 数据整合 | 理论整合 | 容易导入
DB重新设计的工作量很少 |
服务器数不会减少
无法提高可信性 无法提高数据质量 |
|
| 位置整合 | 不需要重新设计DB
减少服务器数量 |
不提高数据质量
需要进行DB管理 |
||
| 物理整合 | 提高数据质量
DB管理效率提高 减少服务器数量 |
需要重新设计DB
需要安装透明层 |
需要服务器物理整合 |
在第一章中,我们明确了服务器整合与数据整合的关联与各自的问题。在这章中,首先我们将介绍各个架构的实装方法以及详细的特征,然后介绍该用怎样的顺序来执行数据整合。
在此,我们来看看数据整合的详细架构。数据结合中,可以将多个服务器的数据整理到一个物理服务器中,用一个存储来管理,或者将多个服务器上的数据库用理论来约束对数据进行一元化管理的架构。数据整合可分为3个架构。
这是将被聚集的数据库服务器中现有的所有的数据库进行储存的架构。比如,将选项系统、会计系统、邮件系统的3个服务器上的数据库(图2.1)全储存到一台机器上,架构所有的数据库的形式(图2.2)。执行数据位置整合的情况下,服务器位置整合或者服务器物理整合就会成为前提。适用这种架构的情况下,就不需要重新设计数据库(包括理论设计、物理设计),为了适用,需要将工作量设置在最小限度。但是,这个架构中,还有许多使用、管理方面问题未得到解决,比如,数据的非一致性、二重投资、备份等。产生变化的是可以在一个数据库中储存所有的数据库选项。这时,schema以及object产生重复的话,就需要应用进行变更。
基本而言,这是将已分散配置的服务器,使用Oracle的分散DB功能,理论上用一个数据库来展示的方法。但是,需要选出现存的数据服务器中有的重复数据以及需要保持一致性的数据,作为共通数据库分离。各自的数据库中固有的数据保持着现有的数据库服务器的情况下,对这些应用提高透过性的Layer,保持应用的独立性。
在整理重复数据的过程中,可能发生小规模的数据物理整合。不重复的数据就那样保存在现有服务器中就行了。对于分散配置的系统,,应用与数据服务器保持一对一的关系的情况较多,为了提供面向应用的单张图像,使用DB Link、View以及Synonym,使其拥有物理透过性(图2.4)。
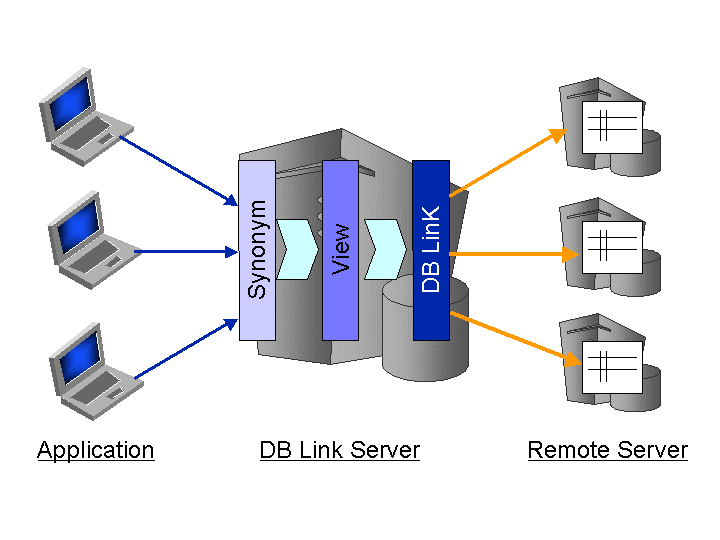
具体而言,System A与System B中,各种各样的Client访问各自的客户数据T_Kokyaku_A、T_Kokyaku_B(图2.5)。这里的客户信息几乎是同样的,但因为分散配置,在各自的系统中分别有着重复数据。
将这个客户信息作为共通DB分离的话就可以去除重复数据,保持有一致性的状态了。System A、System B中各自分别独自使用的数据还是被保存在各自的DB中,对这些数据设定DB Link。另外,对于作为共通DB被分离的数据,也同样使用DB Link来进行访问。但是,在已经完成整合的共通DB中,以前访问的表并不是用列结构的。(Client A是访问用ID,Name,Add构成的表,Client B是访问用ID,Name,Add,Tel构成的表)。这样的话,client A就只访问列增加的表,需要变更应用。因此,通过制成以前访问过的形式的view(V_kokyaku_A、V_kokyaku_B)就可以解决这个问题。并且,对于制成对应各自形式的view,还要制成Synonym(T_kokyaku_A、T_kokyaku_B)。这是schema的不同以及同一列结构中object名不同的情况下,为了吸收差异而这样设定的。
另外,所有的DB都由Oracle构成时,提供Oracle分散功能中Transaction处理的基本功能——ACID特性,万一发生故障,可以执行Transaction自动恢复。因为可以利用oracle的基本功能,使用FTP以及EAI工具时有比较优势。虽然没有什么前提条件,但使用Oracle进行访问理论结合的情况下,如上所示,所有的DB用Oracle来构成的模式对此的合适程度更高。极端情况下,服务器数量不仅不减少,甚至会有增加的情况,这从服务器整合的观点来看的话,可能会认为这效果并不好。但DB相关内容能利用OEM等资源、并且能远程实现一次元的管理,并且可以实现减少TCO。
第三个架构是将所有的数据放在一个数据库中的数据物理整合。
通过执行数据库的理论设计、物理设计,可以实现删除重复数据以及保持数据的一致性。这是将所有的数据用单一的数据库来管理的方法。运用管理效率,数据质量最高的是适合架构的系统。但是,这些工作中,都需要对数据库重新进行架构,同时也需要花费成本。并且,也会有需要变更应用的情况。如果,能将对应用的变更限制在最小的话,与数据理论结合相同,使用View、Synonym,需要将应用设定成能访问object。另外,单一服务器中为了整合,需要采用能够确保可扩展性的基盘架构。处理特性不同的应用,对将要使用的数据进行物理整合时,需要充分考虑应用的特性与数据库的设计间的完整性。比如,伴随着在线交易的业务系数据库以及伴随着大规模搜索的信息系应用,将需要使用的数据进行物理整合的情况下,需要考虑到各应用的优先度、需要的功能配件、负载均衡、资源管理等来架构、设计系统。具体而言,就是利用Oracle Resource Manager、组成Profile的资源分割方案的设定、RAC的service设定功能等。Oracle RDBMS,将要运行的硬件,没有被物理整合的话,数据物理整合就不能成立。
以上我们讲解了3种架构,每个架构都可以适用于Oracle Real Application Clusters。但是,数据理论整合的对象数据库是多数的情况下,对所有的服务器执行共享磁盘,节点的追加的话,从成本上来看是不可能的。另外,用RAW Device制成的数据库也是可行的,但在文件系统上制成数据库的情况下,就会发生重新构筑,数据理论整合的长处——适用的简易性就会无法发挥,用户享受到的好处就会消失。数据位置整合以及数据物理整合,因为会出现这样的前提:导入新的HW、制成数据库,RAC适用非常简单。特别是数据物理整合中,为了集中之前分散的数据访问,所以一定会采用可扩展的架构。
在此,我将介绍数据整合的顺序。数据整合以及服务器整合有密切关联,所以将结合服务器整合的顺序来说明。
使用以下数据、服务器整合的进行方法,我将说明6个阶段
收集每个用户部门的服务器台数、规格、OS、DBMS、其他的Middleware、应用的种类与版本等,每个服务器详细的信息。网络要收集其结构、机器的信息、线的种类以及运营商。另外要遵守机器的租赁合同与维修合同。
实施物理整合时,需要选定即使整合后也能充分轻松应对负荷的高性能的服务器。不仅大型服务器中,在准备如rack mount一样很多的小型服务器的情况下,也必须考虑如何分散负荷,所以把握负荷的状况是非常重要的。
在服务集中的站点中,访问也是集中的。就可能发生以前就经常发生的问题——带宽不足。所以需要测定现在的流量,变更为合适的带宽。也可以考虑广域LAN。
整理相关业务,定义整合服务器的范围。并且定义数据整合的范围。因为范围水平不同,协定不同导致整合需要花费一定成本的情况下,能够决定不执行整合是非常重要的。
为了将整合优点扩展到最大,在选择整合架构时,需要考虑到现在的协作、整合的水平来判断。调查数据相关信息,数据库以及应用的大幅度的改变等必要情况下仅仅进行位置整合,独立的情况下就仅仅进行理论整合。另外,根据所期待的效果,需要取得的架构也发生了变换。在经营策略上,无论如何也要追求实时性的话,就需要数据物理整合以及数据理论整合以及。另外,如果是以提高可信性为目的的话,就可以选择数据物理整合以及数据位置整合。
执行数据整合时需要考虑以下4点。
选出数据相关内容
-数据的主从/上下关系
-数据的重复
-区域的重复
-判断这是否是系统固有的数据
-判断这是否是系统固有的文件
数据的协作方法
-是否可以替换掉固有的数据
-是否可以替换掉固有的文件
-数据的跟新时机的同期、调整
数据正规化
-排除重复数据
-选出重复项目与费重复项目进行调整
数据的方法
-独立(物理整合时是单独表,理论整合时访问DB Link)
-snapshot(吸收到master中)
-外部协作/其他资源管理
经过以上讨论,就可以看见以及整合化的骨骼了,可以作成整合化的计划。伴随硬件成本、网络流量、负荷平衡、结构变更的成本,需要充分再次考虑。一边平均运营维持成本的降低度以及故障时造成的影响的大学,一边制成计划。
以上,我讲解了数据整合的各架构以及作业的流程。数据整合与服务器结合是互相关联的,因为是完全独立的,所以需要非常注意前提条件来完成整合工作的计划。
3.用实测值来比较数据整合架构
此章中,我们将比较数据整合架构——数据理论整合与数据物理结合。比较方法是对比各种的架构中使用的oracle的功能造成的性能变化。
使用oracle数据库执行数据整合时,推测将要使用的功能以及处理的有
- 数据库链接
- 远程交易
- 分散交易
- 2-phase commit
- Real Application Clusters(RAC)
能举出以上例子
在上述举出的Oracle功能之中,在执行数据物理整合之后才使用的是Real Application Clusters。其他功能是在所有数据的理论整合时使用的项目。此章中,可以确认到理论整合物理整合中性能的差异。以下我将叙述各功能的概要
远程交易仅通过访问1个远程节点的语句构成。远程交易有1个以上的远程语句,所有请参照1个远程节点。
分散交易是指由1个以上的语句变成的单独地或者抱团地,想更新分散数据库的多个节点的数据的交易。
与本地数据库的交易不同,分散数据库中伴随着多个数据库的变更。因此,Oracle是交易的变更的Commit以及需要作为自我完结单位来调整roll back。决定是commit交易全体或者进行roll back。
Oracle通过使用2阶段提交机制,保证了分散交易中数据的完整性。准备阶段中,交易内的开始节点对于其他参加节点,要求能确保commit交易或者进行roll back。Commit节点中,开始节点对于所有参加节点,要求commit所有交易。无法达成这个结果的话,要求roll back所有节点。
分散交易中参加的所有节点一定会执行同样的操作。换言之,所有节点都commit交易或者所有节点都roll back 交易。Oracle自动控制或者监视分散交易的commit或者roll back,使用2阶段提交机制,可以维持global数据库的完整性。这个机制是完全透过的,用户与应用开发者不需要编程。
这些功能是理论性以及物理性的,对于执行数据整合时是非常重要的。但是,通过使用这个功能,会造成overhead以及还有一些需要注意的问题,这需要我们对这个功能有正确的理解。考虑到这些内容,即使完成了数据整合,也要从性能、使用、成本等方面,考虑现有的系统是否发生了劣化。
在此章中,我将以实机验证结果为基础,来考虑会发生的数据的理论整合,远程交易以及2阶段commit的处理的影响。
以下叙述执行实机验证的概要
- 本地交易以及远程交易的比较
下章《远程交易对性能的影响》
- 1阶段commit与2阶段commit的比较
下章《2阶段commit对性能造成的影响》
基于以上验证,我叙述分别发生的性能影响。
《本地交易与远程交易的比较》中,需要确认数据的物理整合与理论整合到底有怎样的性能差异以及是否会发生overhead。另外,《1阶段commit2两阶段commit的比较》中,分散交易时,2阶段commit会对性能产生影响,并导致overhead。
验证环境
验证使用的环境如下所示。
DELL OptiPlex Gxi
OS: Red Hat Advanced Server 2.1
CPU:PentiumⅢ 600MHz
Memory:640MB
Oracle9i Enterprise Edition for Linux R9.2.0.3
Sun Enterprise E4500
CPU :Sun Ultra SPARC 400MHz x 8
Memory:2GB
Oracle9i Enterprise Edition for Solaris(32bit) R9.2.0.3
此章中,通过与本地数据库执行处理的情况进行比较,确认远程交易导致的性能的影响。同时,确认本地交易到远程交易之中的overhead。
执行本地交易以及远程交易时的环境如下所示。实际执行SQL语句处理的服务器是Solaris服务器,远程交易的情况下,经过在Linux服务器上构筑的本地服务器(数据库链接元)来访问。
验证方法有连续执行10000次(1次commit)Select从EMP表开始1行的数据的SQL语句。
通过经过数据库链接的使其变成远程交易,再与本地交易比较,可以发现对性能的影响有了重大变化,有4.94倍之多。
经过本地服务器,不仅是Select语句的处理,远程交易也导致了剧烈的性能恶化。
从statspack中确认Oracle数据库(远程服务器)中的处理时间的话,我们可以看出执行语句所需要的CPU时间是有差异的。处理SQL语句需要的CPU时间是0.82秒,而数据库全体所需要的时间就增加了1.51秒。实际应用中,处理SQL语句的数据库中,我们可以观察到远程交易造成的overhead。
| 远程服务器中的比较 | Local Tx | Remote Tx | |
| 处理时间(s) | 2.78 | 13.74 | |
| CPU | CPU Time(SQL) (s) | 1.88 | 2.7 |
| CPU used by this session(s) | 3.74 | 5.25 | |
| Elapsd Time(SQL) | 1.75 | 2.16 | |
一方面,可以用Statspack确认远程交易执行时的本地服务的状况(数据库连接元)。(表2)
CPU Time 与Elapsed Time的比较 ~本地服务器~
| CPU Time 与Elapsed Time的比较 | LocalTx | RemoteTx | |
| 処理時間(s) | 2.78 | 13.74 | |
| CPU | CPU Time(SQL) (s) | 1.88 | 4.24 |
| CPU used by this session(s) | 3.74 | 6.51 | |
| Elapsd Time(SQL) | 1.75 | 12.36 | |
远程交易执行时的本地服务器的性能会对整体的性能有重大影响。这是由于虽然远程服务器中的SQL处理时间(Elapsed Time)的增加了,但本地服务器中的SQL处理时间增加得更多。
这是因为使用本地服务器与远程服务器直接发生的数据库连接导致网络缓慢。Statspack开始可以确认数据库链接地址的与远程数据库的信息交换相关的待机项目「SQL*Net message from dblink」的合计待机时间是9秒。
如上所述,为了执行远程交易,通过使用数据库链接,可能造成网络延迟,从而导致整体的处理性能受到重大影响。
然后是Oracle内部的操作,我们从远程交易给处理性能带来的overhead的角度考虑。
远程交易造成overhead的发生可以从表1和表2的CPU Time的增加中确认。CPU Time是指Oracle执行某个处理时所使用的CPU时间,不包含其他(网络或磁盘I/O)原因导致延迟的时间。这里的时间增加是指,Oracle执行的内部操作不同的可能性。
从Statspack中试着确认内部操作是否有错误的话,就如表3所示,我们可以发现latch的获得次数也会有重大差异。这些latch是不会在本地交易时发生的,而在远程交易时大量发生。(表3)
表 3 远程交易导致大量获得latch ~远程服务器~
| Local Tx | Remote Tx | ||
| Latch | enqueues | 76 | 40,124 |
| enqueue hash chain | 359 | 40,399 | |
| global tx hash mapping | 0 | 20,003 | |
| transaction branch allocation | 1 | 20,003 | |
enqueues / enqueue hash chain latch相关是Oracle在开始分散交易时获得的DX队列(Distributed Transaction entry)造成的项目。这个队列是在分散开一开始时,Oracle在内存上持有的X$K2GTE表中写入entry时必需的东西。Oracle中对于远程数据库,在参照处理(SELECT语句)发行的情况下,因为认识为分散交易,就会发生上述的entry。
另外,global tx hash mapping / transaction branch allocation latch是在发生global交易的时候发生的。在Oracle中发生的Latch的获得(发生spin时排除)时不会对CPU负荷造成太大的负担,但是如果一般不发生latch的获得却突然大量发生的话,CPU时间以及性能就会受到影响。
为了确认之前所述latch获得到底能给CPU时间以及性能造成多大影响,在处理开始之前宣布”set transaction read only”,就可以减少这里latch的获得次数,执行测试。
表4 与Read Only 交易的操作比较
| – | Read Only | ||
| 処理時間(s) | 13.74 | 12.64 | |
| CPU | CPU Time(SQL) (s) | 2.7 | 2.82 |
| CPU used by this session(s) | 5.25 | 4.56 | |
| Latch | enqueues | 40,124 | 91 |
| enqueue hash chain | 40,399 | 350 | |
| global tx hash mapping | 20,003 | 0 | |
| transaction branch allocation | 20,003 | 1 | |
通过减少latch的获得次数,SQL语句执行时使用的CPU时间的变化是无法见到的,但可以观察到数据库使用的CPU时间的减少(15%)性能比提升了8%。
| =====================
PARSING IN CURSOR #1 len=19 dep=0 uid=350 oct=3 lid=350 tim=23071407270 hv=3079259369 ad=’2bd66c28′ SELECT * FROM “EMP” ç END OF STMT PARSE #1:c=0,e=14123,p=0,cr=0,cu=0,mis=1,r=0,dep=0,og=4,tim=23071407147 ç WAIT #1: nam=’SQL*Net message to client’ ela= 5 p1=1413697536 p2=1 p3=0 WAIT #1: nam=’SQL*Net message from client’ ela= 1156 p1=1413697536 p2=1 p3=0 WAIT #1: nam=’SQL*Net message to client’ ela= 2 p1=1413697536 p2=1 p3=0 WAIT #1: nam=’SQL*Net message from client’ ela= 1030 p1=1413697536 p2=1 p3=0 ===================== PARSING IN CURSOR #1 len=123 dep=0 uid=350 oct=3 lid=350 tim=23071412179 hv=327337135 ad=’2bd5d150′ SELECT “A1″.”EMPNO”,”A1″.”ENAME”,”A1″.”JOB”,”A1″.”MGR”,”A1″.”HIREDATE”,”A1″.”SAL”,”A1″.”COMM”,”A1″.” DEPTNO” FROM “EMP” “A1” END OF STMT : : |
上述的Trace是在执行远程交易时取得的,远程交易的SQL Trace的结果。我们可以看到实际处理的SQL语句(SELECT EMPNO, ENAME …)之前,有”SELECT * FROM EMP”这样一句SQL语句。
这章中,我们仅仅讲到了远程交易时参照系(select)的测试,但我们可以发现更新系(insert以及update)的处理也是同样的结果。
这章中,将讲授对于多个远程DB,执行更新处理的情况下发生的2阶段commit对性能的影响。同时,确认2阶段commit在Oracle内部造成的overhead。
观察这里的原因的话,会发现SQL处理(Insert语句)与使用的CPU时间的增加相比,COMMIT处理时使用的CPU时间的增加变得非常大了。
比较SQL处理时间(2个Insert语句的合计处理时间)的话,1阶段commit时是48.3秒,2阶段commit时是56.14秒。而COMMIT的处理时间从1阶段commit到2阶段commit的话,从71.9秒大幅增加到了288.7秒。这样,由于变成了2阶段commit,COMMIT的处理时间差对于全体的处理性能会有重大影响。
2阶段commit中有准备阶段,commit阶段以及消除信息阶段这3个阶段。这些阶段,从用户开始发行COMMIT的话,Oracle就会进行内部处理。各阶段中,本地服务器与各个远程服务器互相交换信息,管理状态。这时被执行的处理的overhead表示为COMMIT处理时的处理时间。
为了探究这里的原因,我们将确认COMMIT处理相关oracle数据库的操作。在执行COMMIT处理时,有oracle数据库中发生的代表性的待机项目,”log file sync”。这是COMMIT发行的时机,Oracle数据库将日志缓存上的信息写出到Redo日志文件中发生的待机项目
表6 待机项目“log file sync“的统计信息
| 1PC | 2PC | ||||
| DB Link | Remote DB | DB Link | Remote DB(1DB当) | ||
| log file sync | Waits | 1 | 10,003 | 30,001 | 20,006 |
| Wait Time (s) | 0 | 53 | 23 | 98 | |
在Statspack中,在1阶段commit执行时与2阶段commit执行时,可以发现”log file sync”的待机次数与伴随其的待机时间有重大差异。2阶段commit执行时,1次的交易中(COMMIT发行),在本地服务器中发生3次“log file sync”,在各个远程服务器中发生两次“log file sync”。
为了确认这件事,展示在本地服务器中取得的SQL Trace的结果。
| PARSING IN CURSOR #4 len=6 dep=1 uid=34 oct=44 lid=34 tim=1033533710847208 hv=1053795750 ad=’556257a
c’ COMMIT END OF STMT PARSE #4:c=0,e=655,p=0,cr=0,cu=0,mis=1,r=0,dep=1,og=4,tim=1033533710847185 XCTEND rlbk=0, rd_only=1 WAIT #4: nam=’log file sync’ ela= 1230 p1=21526 p2=0 p3=0 WAIT #4: nam=’SQL*Net message to dblink’ ela= 5 p1=675562835 p2=1 p3=0 WAIT #4: nam=’SQL*Net message from dblink’ ela= 14650 p1=675562835 p2=1 p3=0 WAIT #4: nam=’log file sync’ ela= 652 p1=21529 p2=0 p3=0 WAIT #4: nam=’SQL*Net message to dblink’ ela= 3 p1=675562835 p2=1 p3=0 WAIT #4: nam=’SQL*Net message from dblink’ ela= 10912 p1=675562835 p2=1 p3=0 WAIT #4: nam=’log file sync’ ela= 652 p1=21530 p2=0 p3=0 WAIT #4: nam=’SQL*Net message to dblink’ ela= 2 p1=675562835 p2=1 p3=0 WAIT #4: nam=’SQL*Net message from dblink’ ela= 4830 p1=675562835 p2=1 p3=0 WAIT #4: nam=’SQL*Net message to dblink’ ela= 3 p1=675562835 p2=1 p3=0 WAIT #4: nam=’SQL*Net message from dblink’ ela= 5327 p1=675562835 p2=1 p3=0 EXEC #4:c=0,e=40295,p=0,cr=0,cu=13,mis=0,r=0,dep=1,og=4,tim=1033533710887741 |
由于上述Trace,我们发现执行1次COMMIT却执行了3次”log file sync”。
伴随着这里的COMMIT发行的Redo日志的输入工作就成为了导致CPU资源使用以及磁盘I/O的发生原因。
另一方面,在远程数据库中,通过执行2阶段COMMIT,可以确认overhead。
我们可以发现1阶段commit时,同一实例内有一个已获得的latch,2阶段commit时有从各远程服务器中获得的事项。这些latch是远程交易时获得的enqueues、enqueue hash chain、global tx hash mapping、transaction branch allocation。
另外各个远程数据库以及本地数据库之间的网络延迟也会造成影响。
最后,我们将谈到1阶段commit与2阶段commit时发生的磁盘I/O最大的原因之一,我们将比较UNDO尺寸与Redo日志尺寸。(图4)通过使其变成2阶段commit,伴随着分散交易发生,UNDO以及Redo日志记录会在各数据库中被大量写出来。
这样,通过使其变成2阶段commit,Orace的内部操作(COMMIT发行时)会发生变化,就会对处理性能产生重大影响。不仅是CPU的使用率,生成的UNDO记录以及Redo记录的尺寸都会有涨到2倍以上的情况,需要好好考虑本地服务器以及远程服务器的磁盘性能。
与本地交易相比,我们可以发现因为执行分散处理所必要的处理(远程交易以及2阶段commit)的overhead都非常大。并不只是网络延迟,根据Orace的内部操作(latch获得以及Redo日志的增加等)的不同,也会导致性能劣化。
这些影响不仅经常在远程数据库中发生,也会经常在本地数据库中发生,在构筑实际系统时,需要考虑各个服务器的硬件资源。
远程交易以及2阶段commit都是主要在数据的理论整合时发生的处理,这些overhead会对性能造成重大影响。
由此,比起使用分散功能的数据理论整合,还是使用仅仅使用不会发生overhead的本地交易功能的数据物理整合在性能上才更好
理想的数据整合与移动路径
随着数据整合推进,架构的不同会对性能产生影响,甚至还会使得资源产生变化。
在数据理论整合中,远程交易以及2阶段commit对性能的影响非常大,所以使用、设计、架构时要充分注意,可能的话,对数据进行物理整合,希望其可以在数据发生理论整合时压抑overhead。
考虑到各种方法的性能,我们决定阶段性地完成数据整合。现在,将分散的系统同时整合是不太可能的。因此,这次数据整合的目标暂定为数据的物理真核,从其他整合形式开始的移行路径来考虑。
首先,考虑将现有的系统数据进行理论性地整合的“移动阶段”。在此阶段中,是以被分散的各系统的数据一致性以及提高自应用开始的物理高透过性为目的的。使用的Oracle功能有数据库链接。
这个系统的形态在第三章中陈述过的远程交易以及2阶段commit导致的overhead。
然后,将数据进行物理性的整合的整合模式。技术上来说,因为要在一个数据库中整合所有的数据,所以Oracle执行的处理全都会变成本地交易。由此,就会减少在移动模式中的overhead。另外,通过聚集到一个数据库中,会成为一个更方便管理的系统。
为了确保更高级别的可扩展性以及可用性,数据的物理整合是将已执行的数据库服务器进行集群构成。在这里的发展阶段中,就变成了使用Oracle的Real Application Clusters(RAC)系统结构,性能和使用方面都是最优秀的系统。
我们需要充分理解各阶段以及在各阶段使用的各功能的优缺点之后,再进行数据整合。在此,阶段性的“发展阶段”的为止是使用Real Application Clusters(RAC)的数据物理整合,但根据系统不同,在初期的阶段,需要考虑构成RAC。
根据验证结果,我们已经知道了我们需要一边考虑在各处理中发生的overhead一边进行数据整合这是非常重要的。
具体而言,分散交易中发生的远程交易以及2阶段commit造成的性能劣化等。
另外之前我就已经作为追加内容讲解并验证过的,如《分散交易导致Redo尺寸增加》所述,根据处理的组合(交易的内容)不同,所输出的Redo日志尺寸也有很大不同。配合这个结果,第三章中接触到的“远程交易对性能造成的影响”以及“2阶段commit对性能造成的影响”中的需要注意的地方,我们在此讨论一下进行数据整合时一些需要注意的点。
执行分散交易(包含远程交易)时,需要尽可能减少成为对象的远程服务器。首先对对由于分散交易导致的追加Redo日志进行确认测试结果后,根据成为处理对象的远程服务器的数量不同,我们可以看出被输出的Redo日志尺寸也有很大变化。Redo日志尺寸增加会使得磁盘I/O发生,会对系统全体产生重大影响。
另外,在对处理性能要求严格系统中,需要尽可能压制远程交易的发生,希望尽可能作为本地交易来处理。
因为远程交易发生,Oracle内部追加的处理就会消除,对性能的影响也亏变大。因此,为了尽可能减少远程交易,需要将多个数据库中存在的重复数据,尽量物理整合到本地服务器之中。
通过将执行更新的服务器合为一个,就可以防止2阶段commit的发生。由此,各交易就会变成远程交易处理,所以即使执行更新处理,也只能用1阶段commit来执行。因此,就不会有2阶段commit导致的overhead,就可以将对处理性能的影响限制在最小。
将数据进行理论性的或者物理性的结合,但前提必须是能保证系统的可扩展性与可用性。
执行数据理论结合的情况下,各数据库分别是作为其他的系统而存在的,对于各自数据库服务器,需要考虑可用性。
一方面,执行数据理论整合的情况下,因为数据库聚集到一个里了,需要充分考虑那个数据库服务器的可用性。
将各数据库改成HA结构或者RAC结构,就可以更加提高可用性。
考虑了如上所述几点的话,在数据整合的初期阶段,我推荐数据的物理整合以及理论整合的相组合的方法。这些方式的特征如下所示。
- 本地服务器中使用RAC功能的结构
确保可扩展性以及可用性
- 本地服务器中对重复数据进行物理整合
尽可能减少远程交易
抑制对性能的影响
- 使用数据库连接,执行数据的理论结合
有效活用现有的系统资产,抑制初期投资成本
通过采取这些方法,就可以比较简单地进行RAC构成的数据物理整合的全面移行。
在本文中,讲解了现在大家比较重视的数据整合的架构以及整合的进行方法。进行了各种比较实验,结果是数据物理整合比数据理论整合、数据位置整合效果好。TCO减少、系统的可信性、安全水平、数据质量等,以服务器物理整合为基础的数据物理整合要更好。
但是,考虑到将现在所有系统一口气进行整合的风险,调和各个要整合的用户部门等麻烦的话,将所有系统一次整合的成本是非常大的,要求技术也是非常高的。由此,在第4章中,我们展示了一边向完成型迈步一边讲解整合这样的路线图。
最后要求与Real Application Clusters的匹配。数据物理整合是最适合与RAC的匹配的。2.1.3中我们也稍微谈到过,通过与RAC的组合,可以大幅提高信赖性、安全性、可扩展性、管理效率。本文中给发展阶段定位了,但考虑到整合的重要性,实时指向的话,RAC的数据物理整合就可以能成为标准形式。所以我们最终应该追求的形式,也应该是RAC的数据物理整合。
此章中,通过执行分散交易,会稍微谈到被输出的Redo日志尺寸。
通过执行远程交易以及分散交易,Redo日志尺寸会发生变化,所以无论执行怎样的处理,都需要调查Redo日志的输出。
作为测试方法,将需要处理的SQL语句按① DB Link(本地数据库) ② Remote1(远程数据库)③ Remote2(远程数据库)这样的顺序发行,确认在各服务器中输出了Redo日志。
由测试结果,会在各个服务器中执行怎样的处理呢?被输出的追加Redo日志总结在表7中了。
下述就是Redo日志dump的结果,对应表8中Redo的日志记录
另外,本文中使用的Redo日志记录的输出内容相对的名称是这个验证中独立的。不是Oracle数据库中正式的名称,请大家注意。
2阶段commit时的Redo日志dump
REDO RECORD – Thread:1 RBA: 0x00003a.00000012.0010 LEN: 0x00d4 VLD: 0x01
>>> Remote
SCN: 0x0000.0ed8f8eb SUBSCN: 1 07/01/2003 21:00:36
CHANGE #1 TYP:0 CLS:21 AFN:2 DBA:0x00801409 SCN:0x0000.0ed8f8e6 SEQ: 1 OP:5.2
ktudh redo: slt: 0x0010 sqn: 0x000000b1 flg: 0x0011 siz: 52 fbi: 0
uba: 0x00801c09.000a.07 pxid: 0x0000.000.00000000
CHANGE #2 TYP:0 CLS:22 AFN:2 DBA:0x00801c09 SCN:0x0000.0ed8f8e4 SEQ: 2 OP:5.1
ktudb redo: siz: 52 spc: 6850 flg: 0x0012 seq: 0x000a rec: 0x07
xid: 0x0003.010.000000b1
ktubl redo: slt: 16 rci: 0 opc: 5.7 objn: 0 objd: 0 tsn: 0
Undo type: Regular undo Begin trans Last buffer split: No
Temp Object: No
Tablespace Undo: No
0x00000000 prev ctl uba: 0x00801c09.000a.04
prev ctl max cmt scn: 0x0000.0ed6667a prev tx cmt scn: 0x0000.0ed666dd
CHANGE #3 MEDIA RECOVERY MARKER SCN:0x0000.00000000 SEQ: 0 OP:5.20
session number = 7
serial number = 1103
transaction name =
REDO RECORD – Thread:1 RBA: 0x00003a.00000012.00e4 LEN: 0x00d4 VLD: 0x01
>>> 分散
SCN: 0x0000.0ed8f8eb SUBSCN: 1 07/01/2003 21:00:36
CHANGE #1 TYP:0 CLS:21 AFN:2 DBA:0x00801409 SCN:0x0000.0ed8f8eb SEQ: 1 OP:5.2
ktudh redo: slt: 0x0010 sqn: 0x00000000 flg: 0x0004 siz: 96 fbi: 1
uba: 0x00801c09.000a.08 pxid: 0x0000.000.00000000
CHANGE #2 TYP:0 CLS:22 AFN:2 DBA:0x00801c09 SCN:0x0000.0ed8f8eb SEQ: 1 OP:5.1
ktudb redo: siz: 96 spc: 6796 flg: 0x0024 seq: 0x000a rec: 0x08
xid: 0x0003.010.000000b1
ktubu redo: slt: 16 rci: 0 opc: 0.0 objn: 0 objd: 0 tsn: 0
Undo type: Regular undo Undo type: Last buffer split: No
Tablespace Undo: No
0x00000000
Dumping kcocv element #2 size 64:
Dump of memory from 0x405DA378 to 0x405DA3B8
405DA370 00000002 0004AC1E [……..]
405DA380 00000015 00000000 07060005 43415200 [………….RAC]
405DA390 6662632E 63323332 2E332E37 312E3631 [.cbf232c7.3.16.1]
405DA3A0 43533737 6F54544F 6C636172 6F6D7465 [77SCOTToracletmo]
405DA3B0 32306972 00000000 [ri02….]
REDO RECORD – Thread:1 RBA: 0x00003a.00000012.01b8 LEN: 0x0228 VLD: 0x01
>>> site信息
SCN: 0x0000.0ed8f8eb SUBSCN: 1 07/01/2003 21:00:36
CHANGE #1 TYP:0 CLS:22 AFN:2 DBA:0x00801c09 SCN:0x0000.0ed8f8eb SEQ: 2 OP:5.1
ktudb redo: siz: 496 spc: 6698 flg: 0x0024 seq: 0x000a rec: 0x09
xid: 0x0003.010.000000b1
ktubu redo: slt: 16 rci: 8 opc: 0.0 objn: 0 objd: 0 tsn: 0
Undo type: Regular undo Undo type: Last buffer split: No
Tablespace Undo: No
0x00000000
Dumping kcocv element #2 size 464:
Dump of memory from 0x0AAF784C to 0x0AAF7A1C
AAF7840 00000001 [….]
AAF7850 00000022 02020100 00000000 00000000 [“……………]
AAF7860 4D455207 3145544F 00000000 00000000 [.REMOTE1……..]
AAF7870 00000000 00000000 00000000 00000000 […………….]
Repeat 1 times
AAF7890 00000000 00000000 0AA91394 00000000 […………….]
AAF78A0 0040013C 0000006E 0000006E 00030000 [<[email protected]…n…….]
AAF78B0 00001FE8 00000000 0AA91394 00000000 […………….]
AAF78C0 00000000 00000000 00000000 00000000 […………….]
AAF78D0 00000000 00000000 0000005B 0AA8F0FC [……..[…….]
AAF78E0 37620830 38633261 0AA86135 0AA8F72C [0.b7a2c85a..,…]
AAF78F0 00000000 00000022 030A0104 B1001000 [….”………..]
AAF7900 01000000 00000004 00000000 00060000 […………….]
AAF7910 00000005 00000000 00000000 00000000 […………….]
AAF7920 00000000 00000000 00000000 00000000 […………….]
AAF7930 00000000 00000000 0040013D 4D455207 [……[email protected]]
AAF7940 3245544F 00030000 00001FE8 00000001 [OTE2…………]
AAF7950 00000000 0AA91394 00000000 516DE014 […………..mQ]
AAF7960 00100400 090C46D2 BFFE828C 090C79F4 […..F…….y..]
AAF7970 00000000 00000000 090C5B0C 0AA8F69C [………[……]
AAF7980 00000000 00000000 00000000 00000000 […………….]
AAF7990 FFFFFFFF 0000FFFF 00000000 00000214 […………….]
AAF79A0 00000000 00000001 000007BC 00000000 […………….]
AAF79B0 00000000 00000000 00000000 38360800 […………..68]
AAF79C0 65613364 00403762 0000006E 0000006E [[email protected]…n…]
AAF79D0 00000022 030A0003 B1001000 01000000 [“……………]
AAF79E0 014B0003 00000000 00000000 00000000 [..K………….]
AAF79F0 0000014B 0000FFFF 0040013D 0000014A [K……[email protected]…]
AAF7A00 0AA8F8BC 00000000 0AA8F69C 00000000 […………….]
AAF7A10 00000000 00000018 00400000 [……….@.]
REDO RECORD – Thread:1 RBA: 0x00003a.00000013.01f0 LEN: 0x0040 VLD: 0x01
>>> Commit(2PC)
SCN: 0x0000.0ed8f8eb SUBSCN: 1 07/01/2003 21:00:36
CHANGE #1 TYP:0 CLS:21 AFN:2 DBA:0x00801409 SCN:0x0000.0ed8f8eb SEQ: 2 OP:5.12
ktust redo: slt: 16 sqn: 0x000000b1 sta: 1 cfl: 0x2
REDO RECORD – Thread:1 RBA: 0x00003a.00000015.0010 LEN: 0x0040 VLD: 0x01
SCN: 0x0000.0ed8f8ef SUBSCN: 1 07/01/2003 21:00:36
CHANGE #1 TYP:0 CLS:21 AFN:2 DBA:0x00801409 SCN:0x0000.0ed8f8eb SEQ: 3 OP:5.12
ktust redo: slt: 16 sqn: 0x000000b1 sta: 2 cfl: 0x2
REDO RECORD – Thread:1 RBA: 0x00003a.00000016.0010 LEN: 0x0048 VLD: 0x01
SCN: 0x0000.0ed8f8f1 SUBSCN: 1 07/01/2003 21:00:36
CHANGE #1 TYP:0 CLS:21 AFN:2 DBA:0x00801409 SCN:0x0000.0ed8f8ef SEQ: 1 OP:5.4
ktucm redo: slt: 0x0010 sqn: 0x000000b1 srt: 1 sta: 3 flg: 0x1 scn: 0x0000.0ed8f8f1
REDO RECORD – Thread:1 RBA: 0x00003a.00000017.0010 LEN: 0x0040 VLD: 0x01
SCN: 0x0000.0ed8f8f3 SUBSCN: 1 07/01/2003 21:00:36
CHANGE #1 TYP:0 CLS:21 AFN:2 DBA:0x00801409 SCN:0x0000.0ed8f8f1 SEQ: 1 OP:5.12
ktust redo: slt: 16 sqn: 0x000000b1 sta: 9 cfl: 0x0
>>> Commit(至此)
REDO RECORD – Thread:1 RBA: 0x00003a.00000008.0028 LEN: 0x0040 VLD: 0x01
>>> Commit (1PC)
SCN: 0x0000.0ed8f8dc SUBSCN: 1 07/01/2003 21:00:33
CHANGE #1 TYP:0 CLS:21 AFN:2 DBA:0x00801409 SCN:0x0000.0ed8f8dc SEQ: 1 OP:5.12
ktust redo: slt: 8 sqn: 0x000000b1 sta: 1 cfl: 0x2
REDO RECORD – Thread:1 RBA: 0x00003a.00000009.0010 LEN: 0x0050 VLD: 0x01
SCN: 0x0000.0ed8f8de SUBSCN: 1 07/01/2003 21:00:33
CHANGE #1 TYP:0 CLS:21 AFN:2 DBA:0x00801409 SCN:0x0000.0ed8f8dc SEQ: 2 OP:5.4
ktucm redo: slt: 0x0008 sqn: 0x000000b1 srt: 0 sta: 9 flg: 0x2
ktucf redo: uba: 0x00801c09.000a.03 ext: 8 spc: 7500 fbi: 0
>>> Commit(至此)
Leave a Reply